 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework
Paper and Code
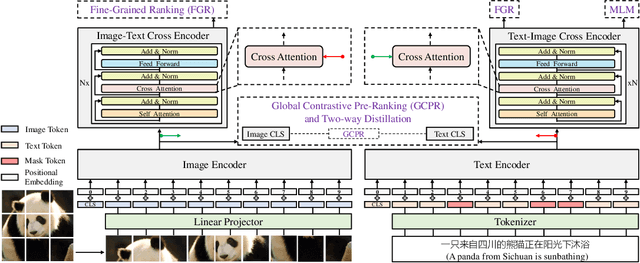
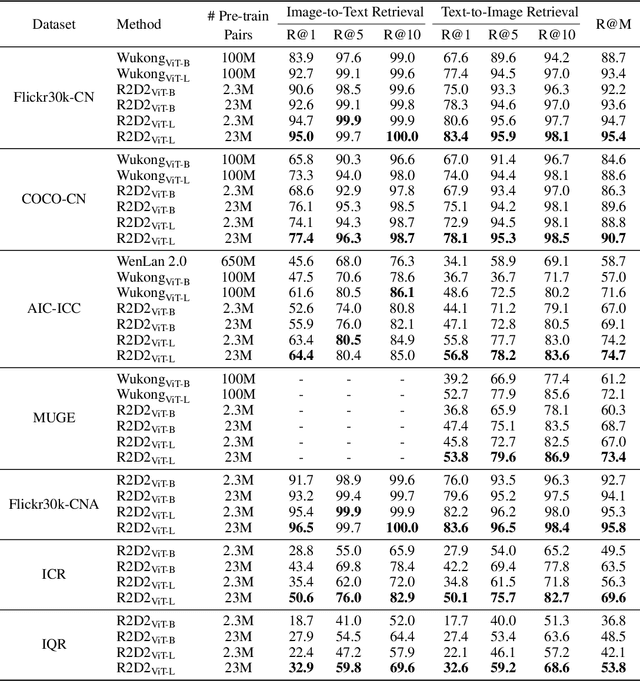

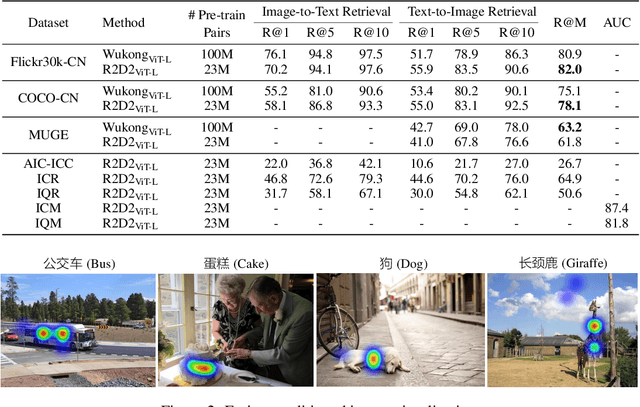
Vision-language pre-training (VLP) relying on large-scale pre-training datasets has shown premier performance on various downstream tasks. In this sense, a complete and fair benchmark (i.e., including large-scale pre-training datasets and a variety of downstream datasets) is essential for VLP. But how to construct such a benchmark in Chinese remains a critical problem. To this end, we develop a large-scale Chinese cross-modal benchmark called Zero for AI researchers to fairly compare VLP models. We release two pre-training datasets and five fine-tuning datasets for downstream tasks. Furthermore, we propose a novel pre-training framework of pre-Ranking + Ranking for cross-modal learning. Specifically, we apply global contrastive pre-ranking to learn the individual representations of images and Chinese texts, respectively. We then fuse the representations in a fine-grained ranking manner via an image-text cross encoder and a text-image cross encoder. To further enhance the capability of the model, we propose a two-way distillation strategy consisting of target-guided Distillation and feature-guided Distillation. For simplicity, we call our model R2D2. We achieve state-of-the-art performance on four public cross-modal datasets and our five downstream datasets. The datasets, models and codes will be made available.