 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Valley2: Exploring Multimodal Models with Scalable Vision-Language Design
Jan 13, 2025



Recently, vision-language models have made remarkable progress, demonstrating outstanding capabilities in various tasks such as image captioning and video understanding. We introduce Valley2, a novel multimodal large language model designed to enhance performance across all domains and extend the boundaries of practical applications in e-commerce and short video scenarios. Notably, Valley2 achieves state-of-the-art (SOTA) performance on e-commerce benchmarks, surpassing open-source models of similar size by a large margin (79.66 vs. 72.76). Additionally, Valley2 ranks second on the OpenCompass leaderboard among models with fewer than 10B parameters, with an impressive average score of 67.4. The code and model weights are open-sourced at https://github.com/bytedance/Valley.
VoCoT: Unleashing Visually Grounded Multi-Step Reasoning in Large Multi-Modal Models
May 28, 2024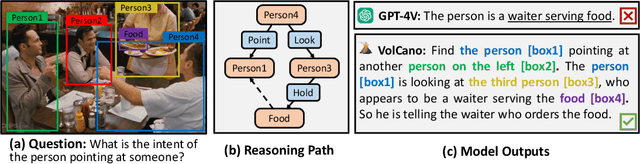

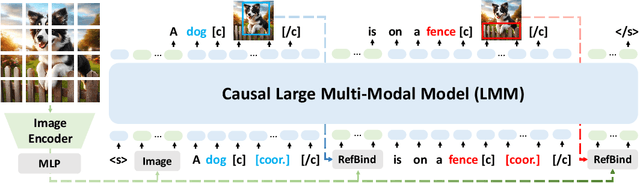
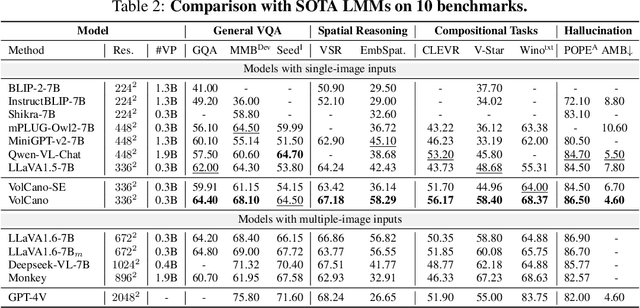
While large multi-modal models (LMMs) have exhibited impressive capabilities across diverse tasks, their effectiveness in handling complex tasks has been limited by the prevailing single-step reasoning paradigm. To this end, this paper proposes VoCoT, a multi-step Visually grounded object-centric Chain-of-Thought reasoning framework tailored for inference with LMMs. VoCoT is characterized by two key features: (1) object-centric reasoning paths that revolve around cross-modal shared object-level information, and (2) visually grounded representation of object concepts in a multi-modal interleaved and aligned manner, which effectively bridges the modality gap within LMMs during long-term generation. Additionally, we construct an instruction dataset to facilitate LMMs in adapting to reasoning with VoCoT. By introducing VoCoT into the prevalent open-source LMM architecture, we introduce VolCano. With only 7B parameters and limited input resolution, VolCano demonstrates excellent performance across various scenarios, surpassing SOTA models, including GPT-4V, in tasks requiring complex reasoning. Our code, data and model will be available at https://github.com/RupertLuo/VoCoT.
DELAN: Dual-Level Alignment for Vision-and-Language Navigation by Cross-Modal Contrastive Learning
Apr 02, 2024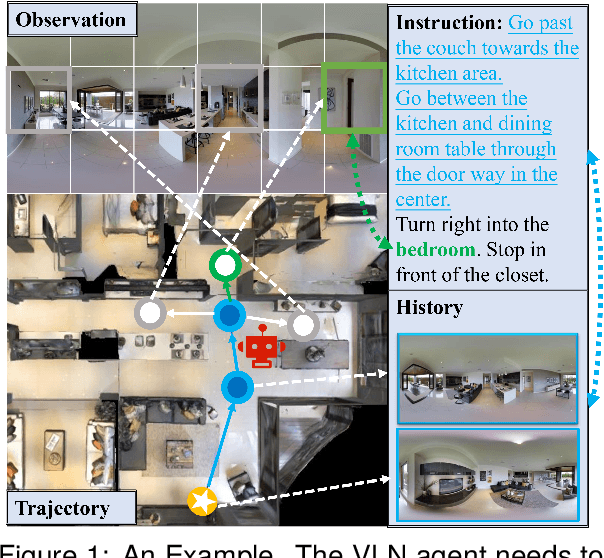

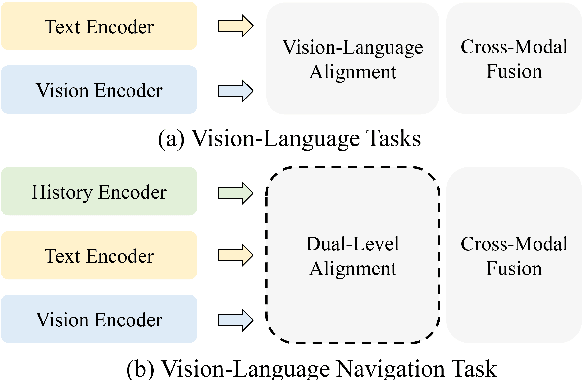

Vision-and-Language navigation (VLN) requires an agent to navigate in unseen environment by following natural language instruction. For task completion, the agent needs to align and integrate various navigation modalities, including instruction, observation and navigation history. Existing works primarily concentrate on cross-modal attention at the fusion stage to achieve this objective. Nevertheless, modality features generated by disparate uni-encoders reside in their own spaces, leading to a decline in the quality of cross-modal fusion and decision. To address this problem, we propose a Dual-levEL AligNment (DELAN) framework by cross-modal contrastive learning. This framework is designed to align various navigation-related modalities before fusion, thereby enhancing cross-modal interaction and action decision-making. Specifically, we divide the pre-fusion alignment into dual levels: instruction-history level and landmark-observation level according to their semantic correlations. We also reconstruct a dual-level instruction for adaptation to the dual-level alignment. As the training signals for pre-fusion alignment are extremely limited, self-supervised contrastive learning strategies are employed to enforce the matching between different modalities. Our approach seamlessly integrates with the majority of existing models, resulting in improved navigation performance on various VLN benchmarks, including R2R, R4R, RxR and CVDN.
Breaking Down the Task: A Unit-Grained Hybrid Training Framework for Vision and Language Decision Making
Jul 16, 2023



Vision language decision making (VLDM) is a challenging multimodal task. The agent have to understand complex human instructions and complete compositional tasks involving environment navigation and object manipulation. However, the long action sequences involved in VLDM make the task difficult to learn. From an environment perspective, we find that task episodes can be divided into fine-grained \textit{units}, each containing a navigation phase and an interaction phase. Since the environment within a unit stays unchanged, we propose a novel hybrid-training framework that enables active exploration in the environment and reduces the exposure bias. Such framework leverages the unit-grained configurations and is model-agnostic. Specifically, we design a Unit-Transformer (UT) with an intrinsic recurrent state that maintains a unit-scale cross-modal memory. Through extensive experiments on the TEACH benchmark, we demonstrate that our proposed framework outperforms existing state-of-the-art methods in terms of all evaluation metrics. Overall, our work introduces a novel approach to tackling the VLDM task by breaking it down into smaller, manageable units and utilizing a hybrid-training framework. By doing so, we provide a more flexible and effective solution for multimodal decision making.
Valley: Video Assistant with Large Language model Enhanced abilitY
Jun 12, 2023Recently, several multi-modal models have been developed for joint image and language understanding, which have demonstrated impressive chat abilities by utilizing advanced large language models (LLMs). The process of developing such models is straightforward yet effective. It involves pre-training an adaptation module to align the semantics of the vision encoder and language model, followed by fine-tuning on the instruction-following data. However, despite the success of this pipeline in image and language understanding, its effectiveness in joint video and language understanding has not been widely explored. In this paper, we aim to develop a novel multi-modal foundation model capable of perceiving video, image, and language within a general framework. To achieve this goal, we introduce Valley: Video Assistant with Large Language model Enhanced ability. Specifically, our proposed Valley model is designed with a simple projection module that bridges video, image, and language modalities, and is further unified with a multi-lingual LLM. We also collect multi-source vision-text pairs and adopt a spatio-temporal pooling strategy to obtain a unified vision encoding of video and image input for pre-training. Furthermore, we generate multi-task instruction-following video data, including multi-shot captions, long video descriptions, action recognition, causal relationship inference, etc. To obtain the instruction-following data, we design diverse rounds of task-oriented conversations between humans and videos, facilitated by ChatGPT. Qualitative examples demonstrate that our proposed model has the potential to function as a highly effective multilingual video assistant that can make complex video understanding scenarios easy. Code, data, and models will be available at https://github.com/RupertLuo/Valley.