 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating knowledge bases to improve coreference and bridging resolution for the chemical domain
Apr 16, 2024Resolving coreference and bridging relations in chemical patents is important for better understanding the precise chemical process, where chemical domain knowledge is very critical. We proposed an approach incorporating external knowledge into a multi-task learning model for both coreference and bridging resolution in the chemical domain. The results show that integrating external knowledge can benefit both chemical coreference and bridging resolution.
Valley: Video Assistant with Large Language model Enhanced abilitY
Jun 12, 2023Recently, several multi-modal models have been developed for joint image and language understanding, which have demonstrated impressive chat abilities by utilizing advanced large language models (LLMs). The process of developing such models is straightforward yet effective. It involves pre-training an adaptation module to align the semantics of the vision encoder and language model, followed by fine-tuning on the instruction-following data. However, despite the success of this pipeline in image and language understanding, its effectiveness in joint video and language understanding has not been widely explored. In this paper, we aim to develop a novel multi-modal foundation model capable of perceiving video, image, and language within a general framework. To achieve this goal, we introduce Valley: Video Assistant with Large Language model Enhanced ability. Specifically, our proposed Valley model is designed with a simple projection module that bridges video, image, and language modalities, and is further unified with a multi-lingual LLM. We also collect multi-source vision-text pairs and adopt a spatio-temporal pooling strategy to obtain a unified vision encoding of video and image input for pre-training. Furthermore, we generate multi-task instruction-following video data, including multi-shot captions, long video descriptions, action recognition, causal relationship inference, etc. To obtain the instruction-following data, we design diverse rounds of task-oriented conversations between humans and videos, facilitated by ChatGPT. Qualitative examples demonstrate that our proposed model has the potential to function as a highly effective multilingual video assistant that can make complex video understanding scenarios easy. Code, data, and models will be available at https://github.com/RupertLuo/Valley.
SourceP: Smart Ponzi Schemes Detection on Ethereum Using Pre-training Model with Data Flow
Jun 02, 2023

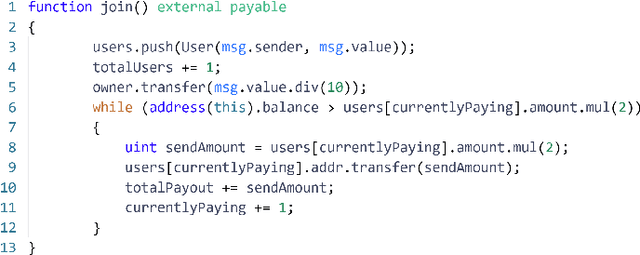

As blockchain technology becomes more and more popular, a typical financial scam, the Ponzi scheme, has also emerged in the blockchain platform Ethereum. This Ponzi scheme deployed through smart contracts, also known as the smart Ponzi scheme, has caused a lot of economic losses and negative impacts. Existing methods for detecting smart Ponzi schemes on Ethereum mainly rely on bytecode features, opcode features, account features, and transaction behavior features of smart contracts, and such methods lack interpretability and sustainability. In this paper, we propose SourceP, a method to detect smart Ponzi schemes on the Ethereum platform using pre-training models and data flow, which only requires using the source code of smart contracts as features to explore the possibility of detecting smart Ponzi schemes from another direction. SourceP reduces the difficulty of data acquisition and feature extraction of existing detection methods while increasing the interpretability of the model. Specifically, we first convert the source code of a smart contract into a data flow graph and then introduce a pre-training model based on learning code representations to build a classification model to identify Ponzi schemes in smart contracts. The experimental results show that SourceP achieves 87.2\% recall and 90.7\% F-score for detecting smart Ponzi schemes within Ethereum's smart contract dataset, outperforming state-of-the-art methods in terms of performance and sustainability. We also demonstrate through additional experiments that pre-training models and data flow play an important contribution to SourceP, as well as proving that SourceP has a good generalization ability.
Coreference Resolution for the Biomedical Domain: A Survey
Sep 25, 2021
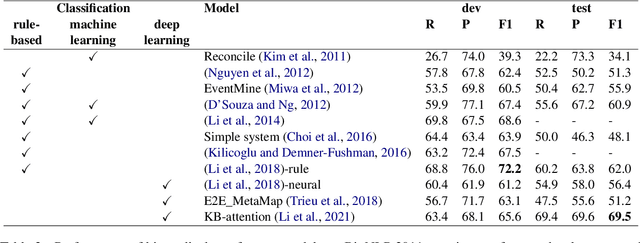


Issues with coreference resolution are one of the most frequently mentioned challenges for information extraction from the biomedical literature. Thus, the biomedical genre has long been the second most researched genre for coreference resolution after the news domain, and the subject of a great deal of research for NLP in general. In recent years this interest has grown enormously leading to the development of a number of substantial datasets, of domain-specific contextual language models, and of several architectures. In this paper we review the state-of-the-art of coreference in the biomedical domain with a particular attention on these most recent developments.