 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Chinese Multi-label Affective Computing Dataset Based on Social Media Network Users
Nov 13, 2024



Emotion and personality are central elements in understanding human psychological states. Emotions reflect an individual subjective experiences, while personality reveals relatively stable behavioral and cognitive patterns. Existing affective computing datasets often annotate emotion and personality traits separately, lacking fine-grained labeling of micro-emotions and emotion intensity in both single-label and multi-label classifications. Chinese emotion datasets are extremely scarce, and datasets capturing Chinese user personality traits are even more limited. To address these gaps, this study collected data from the major social media platform Weibo, screening 11,338 valid users from over 50,000 individuals with diverse MBTI personality labels and acquiring 566,900 posts along with the user MBTI personality tags. Using the EQN method, we compiled a multi-label Chinese affective computing dataset that integrates the same user's personality traits with six emotions and micro-emotions, each annotated with intensity levels. Validation results across multiple NLP classification models demonstrate the dataset strong utility. This dataset is designed to advance machine recognition of complex human emotions and provide data support for research in psychology, education, marketing, finance, and politics.
Expansion Quantization Network: An Efficient Micro-emotion Annotation and Detection Framework
Nov 09, 2024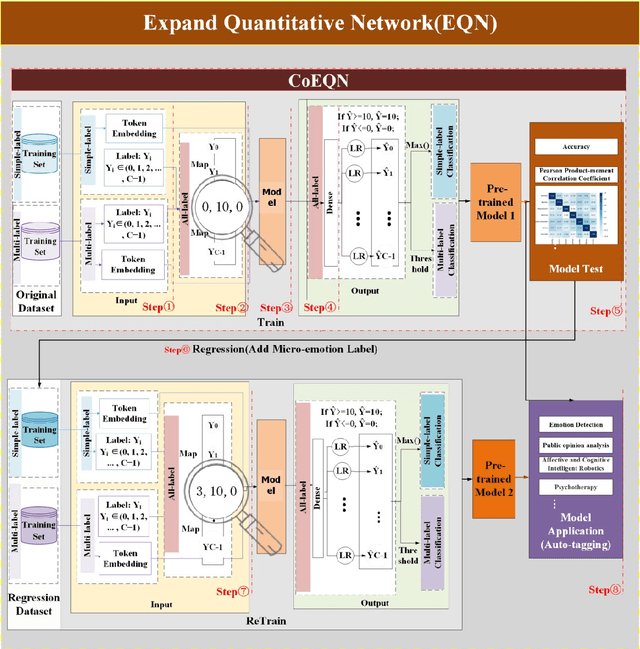

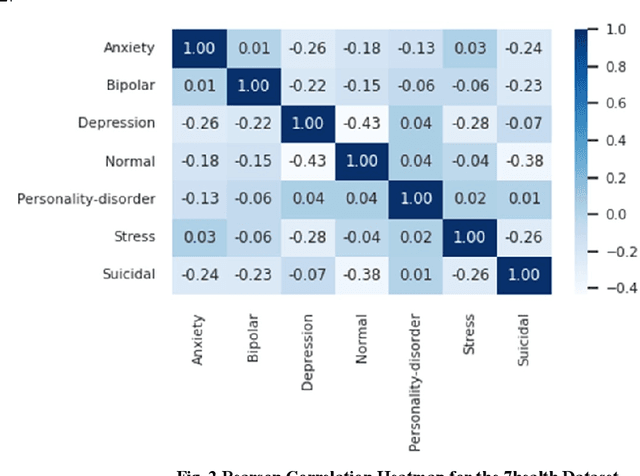
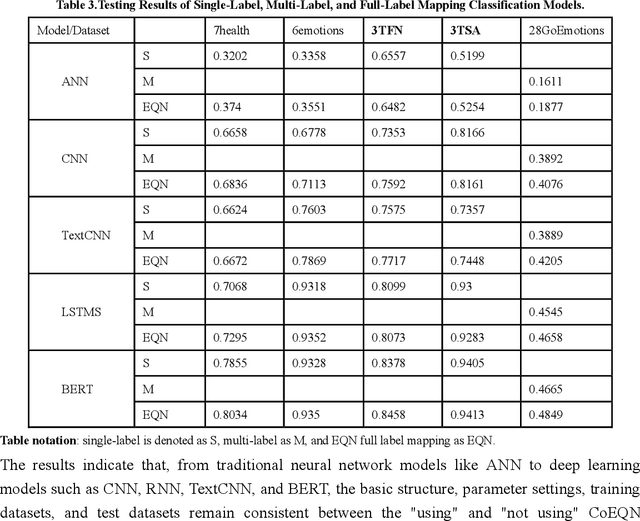
Text emotion detection constitutes a crucial foundation for advancing artificial intelligence from basic comprehension to the exploration of emotional reasoning. Most existing emotion detection datasets rely on manual annotations, which are associated with high costs, substantial subjectivity, and severe label imbalances. This is particularly evident in the inadequate annotation of micro-emotions and the absence of emotional intensity representation, which fail to capture the rich emotions embedded in sentences and adversely affect the quality of downstream task completion. By proposing an all-labels and training-set label regression method, we map label values to energy intensity levels, thereby fully leveraging the learning capabilities of machine models and the interdependencies among labels to uncover multiple emotions within samples. This led to the establishment of the Emotion Quantization Network (EQN) framework for micro-emotion detection and annotation. Using five commonly employed sentiment datasets, we conducted comparative experiments with various models, validating the broad applicability of our framework within NLP machine learning models. Based on the EQN framework, emotion detection and annotation are conducted on the GoEmotions dataset. A comprehensive comparison with the results from Google literature demonstrates that the EQN framework possesses a high capability for automatic detection and annotation of micro-emotions. The EQN framework is the first to achieve automatic micro-emotion annotation with energy-level scores, providing strong support for further emotion detection analysis and the quantitative research of emotion computing.
VulCatch: Enhancing Binary Vulnerability Detection through CodeT5 Decompilation and KAN Advanced Feature Extraction
Aug 13, 2024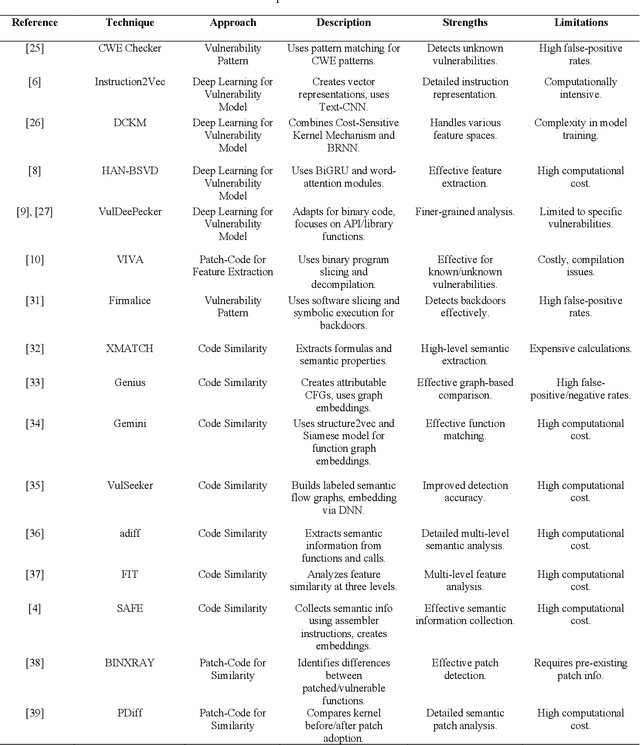

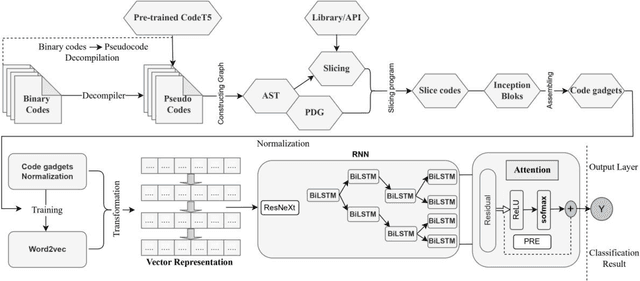
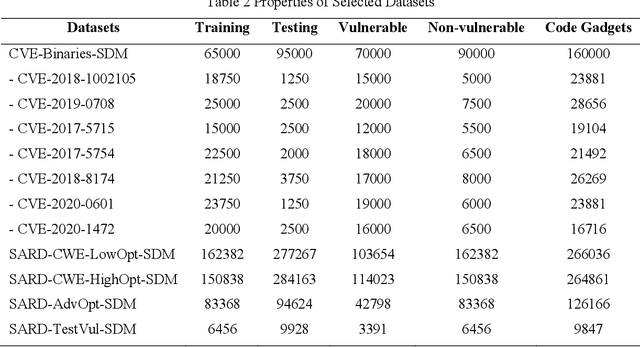
Binary program vulnerability detection is critical for software security, yet existing deep learning approaches often rely on source code analysis, limiting their ability to detect unknown vulnerabilities. To address this, we propose VulCatch, a binary-level vulnerability detection framework. VulCatch introduces a Synergy Decompilation Module (SDM) and Kolmogorov-Arnold Networks (KAN) to transform raw binary code into pseudocode using CodeT5, preserving high-level semantics for deep analysis with tools like Ghidra and IDA. KAN further enhances feature transformation, enabling the detection of complex vulnerabilities. VulCatch employs word2vec, Inception Blocks, BiLSTM Attention, and Residual connections to achieve high detection accuracy (98.88%) and precision (97.92%), while minimizing false positives (1.56%) and false negatives (2.71%) across seven CVE datasets.
A Novel Prompt-tuning Method: Incorporating Scenario-specific Concepts into a Verbalizer
Jan 10, 2024



The verbalizer, which serves to map label words to class labels, is an essential component of prompt-tuning. In this paper, we present a novel approach to constructing verbalizers. While existing methods for verbalizer construction mainly rely on augmenting and refining sets of synonyms or related words based on class names, this paradigm suffers from a narrow perspective and lack of abstraction, resulting in limited coverage and high bias in the label-word space. To address this issue, we propose a label-word construction process that incorporates scenario-specific concepts. Specifically, we extract rich concepts from task-specific scenarios as label-word candidates and then develop a novel cascade calibration module to refine the candidates into a set of label words for each class. We evaluate the effectiveness of our proposed approach through extensive experiments on {five} widely used datasets for zero-shot text classification. The results demonstrate that our method outperforms existing methods and achieves state-of-the-art results.
CodePrompt: Improving Source Code-Related Classification with Knowledge Features through Prompt Learning
Jan 10, 2024Researchers have explored the potential of utilizing pre-trained language models, such as CodeBERT, to improve source code-related tasks. Previous studies have mainly relied on CodeBERT's text embedding capability and the `[CLS]' sentence embedding information as semantic representations for fine-tuning downstream source code-related tasks. However, these methods require additional neural network layers to extract effective features, resulting in higher computational costs. Furthermore, existing approaches have not leveraged the rich knowledge contained in both source code and related text, which can lead to lower accuracy. This paper presents a novel approach, CodePrompt, which utilizes rich knowledge recalled from a pre-trained model by prompt learning and an attention mechanism to improve source code-related classification tasks. Our approach initially motivates the language model with prompt information to retrieve abundant knowledge associated with the input as representative features, thus avoiding the need for additional neural network layers and reducing computational costs. Subsequently, we employ an attention mechanism to aggregate multiple layers of related knowledge for each task as final features to boost their accuracy. We conducted extensive experiments on four downstream source code-related tasks to evaluate our approach and our results demonstrate that CodePrompt achieves new state-of-the-art performance on the accuracy metric while also exhibiting computation cost-saving capabilities.
Co-Attention Hierarchical Network: Generating Coherent Long Distractors for Reading Comprehension
Nov 20, 2019

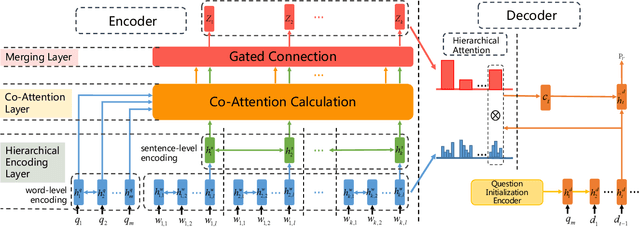
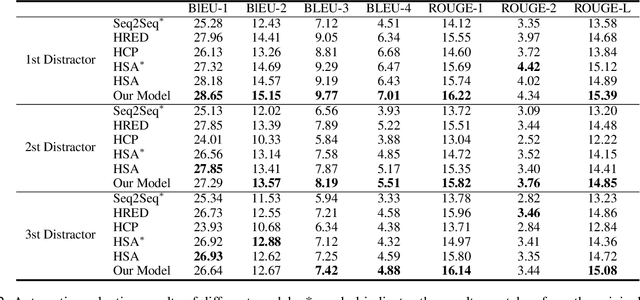
In reading comprehension, generating sentence-level distractors is a significant task, which requires a deep understanding of the article and question. The traditional entity-centered methods can only generate word-level or phrase-level distractors. Although recently proposed neural-based methods like sequence-to-sequence (Seq2Seq) model show great potential in generating creative text, the previous neural methods for distractor generation ignore two important aspects. First, they didn't model the interactions between the article and question, making the generated distractors tend to be too general or not relevant to question context. Second, they didn't emphasize the relationship between the distractor and article, making the generated distractors not semantically relevant to the article and thus fail to form a set of meaningful options. To solve the first problem, we propose a co-attention enhanced hierarchical architecture to better capture the interactions between the article and question, thus guide the decoder to generate more coherent distractors. To alleviate the second problem, we add an additional semantic similarity loss to push the generated distractors more relevant to the article. Experimental results show that our model outperforms several strong baselines on automatic metrics, achieving state-of-the-art performance. Further human evaluation indicates that our generated distractors are more coherent and more educative compared with those distractors generated by baselines.