 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKonvLiNA: Integrating Kolmogorov-Arnold Network with Linear Nyström Attention for feature fusion in Crop Field Detection
Aug 23, 2024Crop field detection is a critical component of precision agriculture, essential for optimizing resource allocation and enhancing agricultural productivity. This study introduces KonvLiNA, a novel framework that integrates Convolutional Kolmogorov-Arnold Networks (cKAN) with Nystr\"om attention mechanisms for effective crop field detection. Leveraging KAN adaptive activation functions and the efficiency of Nystr\"om attention in handling largescale data, KonvLiNA significantly enhances feature extraction, enabling the model to capture intricate patterns in complex agricultural environments. Experimental results on rice crop dataset demonstrate KonvLiNA superiority over state-of-the-art methods, achieving a 0.415 AP and 0.459 AR with the Swin-L backbone, outperforming traditional YOLOv8 by significant margins. Additionally, evaluation on the COCO dataset showcases competitive performance across small, medium, and large objects, highlighting KonvLiNA efficacy in diverse agricultural settings. This work highlights the potential of hybrid KAN and attention mechanisms for advancing precision agriculture through improved crop field detection and management.
VulCatch: Enhancing Binary Vulnerability Detection through CodeT5 Decompilation and KAN Advanced Feature Extraction
Aug 13, 2024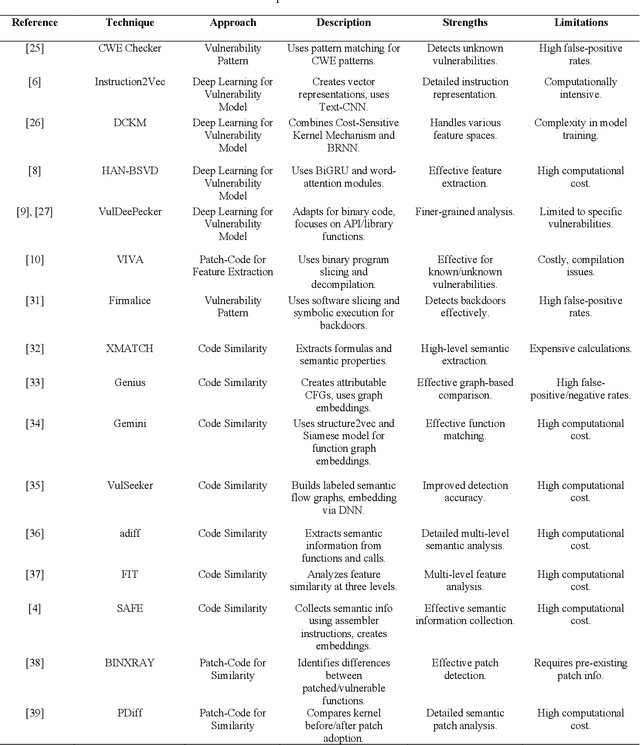

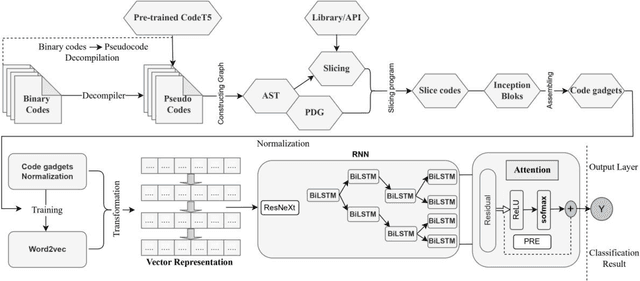
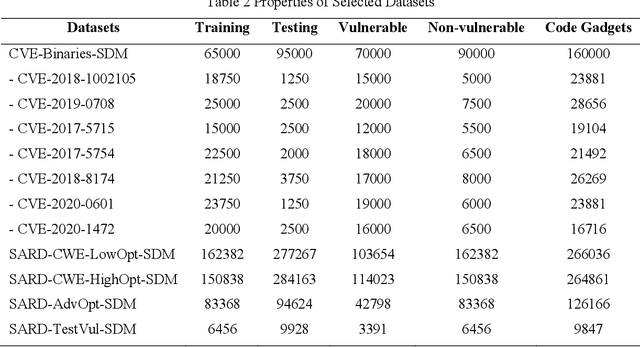
Binary program vulnerability detection is critical for software security, yet existing deep learning approaches often rely on source code analysis, limiting their ability to detect unknown vulnerabilities. To address this, we propose VulCatch, a binary-level vulnerability detection framework. VulCatch introduces a Synergy Decompilation Module (SDM) and Kolmogorov-Arnold Networks (KAN) to transform raw binary code into pseudocode using CodeT5, preserving high-level semantics for deep analysis with tools like Ghidra and IDA. KAN further enhances feature transformation, enabling the detection of complex vulnerabilities. VulCatch employs word2vec, Inception Blocks, BiLSTM Attention, and Residual connections to achieve high detection accuracy (98.88%) and precision (97.92%), while minimizing false positives (1.56%) and false negatives (2.71%) across seven CVE datasets.
iiANET: Inception Inspired Attention Hybrid Network for efficient Long-Range Dependency
Jul 10, 2024
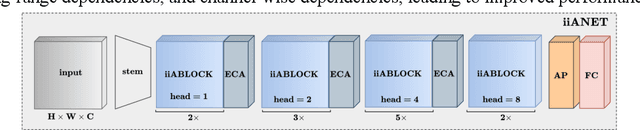
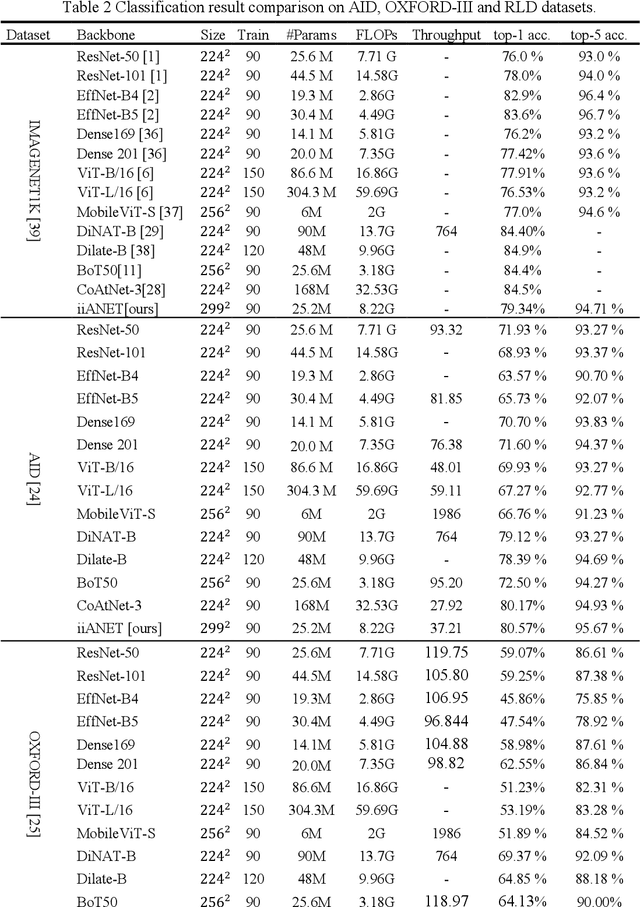

The recent emergence of hybrid models has introduced another transformative approach to solving computer vision tasks, slowly shifting away from conventional CNN (Convolutional Neural Network) and ViT (Vision Transformer). However, not enough effort has been made to efficiently combine these two approaches to improve capturing long-range dependencies prevalent in complex images. In this paper, we introduce iiANET (Inception Inspired Attention Network), an efficient hybrid model designed to capture long-range dependencies in complex images. The fundamental building block, iiABlock, integrates global 2D-MHSA (Multi-Head Self-Attention) with Registers, MBConv2 (MobileNetV2-based convolution), and dilated convolution in parallel, enabling the model to adeptly leverage self-attention for capturing long-range dependencies while utilizing MBConv2 for effective local-detail extraction and dilated convolution for efficiently expanding the kernel receptive field to capture more contextual information. Lastly, we serially integrate an ECANET (Efficient Channel Attention Network) at the end of each iiABlock to calibrate channel-wise attention for enhanced model performance. Extensive qualitative and quantitative comparative evaluation on various benchmarks demonstrates improved performance over some state-of-the-art models.
mAPm: multi-scale Attention Pyramid module for Enhanced scale-variation in RLD detection
Feb 26, 2024Detecting objects across various scales remains a significant challenge in computer vision, particularly in tasks such as Rice Leaf Disease (RLD) detection, where objects exhibit considerable scale variations. Traditional object detection methods often struggle to address these variations, resulting in missed detections or reduced accuracy. In this study, we propose the multi-scale Attention Pyramid module (mAPm), a novel approach that integrates dilated convolutions into the Feature Pyramid Network (FPN) to enhance multi-scale information ex-traction. Additionally, we incorporate a global Multi-Head Self-Attention (MHSA) mechanism and a deconvolutional layer to refine the up-sampling process. We evaluate mAPm on YOLOv7 using the MRLD and COCO datasets. Compared to vanilla FPN, BiFPN, NAS-FPN, PANET, and ACFPN, mAPm achieved a significant improvement in Average Precision (AP), with a +2.61% increase on the MRLD dataset compared to the baseline FPN method in YOLOv7. This demonstrates its effectiveness in handling scale variations. Furthermore, the versatility of mAPm allows its integration into various FPN-based object detection models, showcasing its potential to advance object detection techniques.
Exploring the Synergies of Hybrid CNNs and ViTs Architectures for Computer Vision: A survey
Feb 05, 2024The hybrid of Convolutional Neural Network (CNN) and Vision Transformers (ViT) architectures has emerged as a groundbreaking approach, pushing the boundaries of computer vision (CV). This comprehensive review provides a thorough examination of the literature on state-of-the-art hybrid CNN-ViT architectures, exploring the synergies between these two approaches. The main content of this survey includes: (1) a background on the vanilla CNN and ViT, (2) systematic review of various taxonomic hybrid designs to explore the synergy achieved through merging CNNs and ViTs models, (3) comparative analysis and application task-specific synergy between different hybrid architectures, (4) challenges and future directions for hybrid models, (5) lastly, the survey concludes with a summary of key findings and recommendations. Through this exploration of hybrid CV architectures, the survey aims to serve as a guiding resource, fostering a deeper understanding of the intricate dynamics between CNNs and ViTs and their collective impact on shaping the future of CV architectures.