 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiiANET: Inception Inspired Attention Hybrid Network for efficient Long-Range Dependency
Paper and Code
Jul 10, 2024
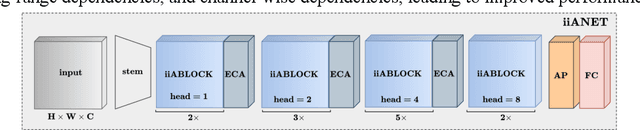
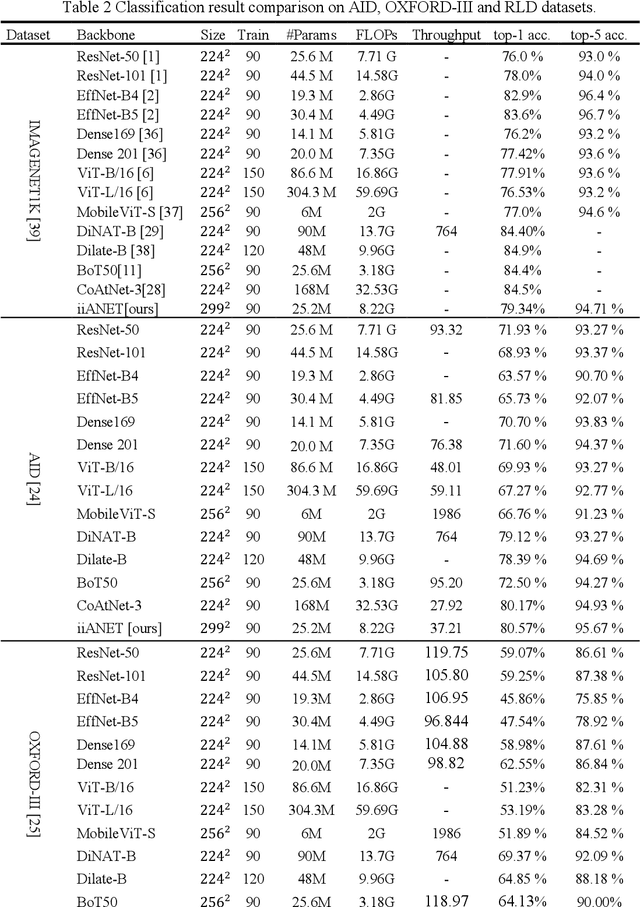

The recent emergence of hybrid models has introduced another transformative approach to solving computer vision tasks, slowly shifting away from conventional CNN (Convolutional Neural Network) and ViT (Vision Transformer). However, not enough effort has been made to efficiently combine these two approaches to improve capturing long-range dependencies prevalent in complex images. In this paper, we introduce iiANET (Inception Inspired Attention Network), an efficient hybrid model designed to capture long-range dependencies in complex images. The fundamental building block, iiABlock, integrates global 2D-MHSA (Multi-Head Self-Attention) with Registers, MBConv2 (MobileNetV2-based convolution), and dilated convolution in parallel, enabling the model to adeptly leverage self-attention for capturing long-range dependencies while utilizing MBConv2 for effective local-detail extraction and dilated convolution for efficiently expanding the kernel receptive field to capture more contextual information. Lastly, we serially integrate an ECANET (Efficient Channel Attention Network) at the end of each iiABlock to calibrate channel-wise attention for enhanced model performance. Extensive qualitative and quantitative comparative evaluation on various benchmarks demonstrates improved performance over some state-of-the-art models.