 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGA: xLSTM with Multihead Exponential Gated Fusion for Precise Aspect-based Sentiment Analysis
Jul 01, 2025Aspect-based Sentiment Analysis (ABSA) is a critical Natural Language Processing (NLP) task that extracts aspects from text and determines their associated sentiments, enabling fine-grained analysis of user opinions. Existing ABSA methods struggle to balance computational efficiency with high performance: deep learning models often lack global context, transformers demand significant computational resources, and Mamba-based approaches face CUDA dependency and diminished local correlations. Recent advancements in Extended Long Short-Term Memory (xLSTM) models, particularly their efficient modeling of long-range dependencies, have significantly advanced the NLP community. However, their potential in ABSA remains untapped. To this end, we propose xLSTM with Multihead Exponential Gated Fusion (MEGA), a novel framework integrating a bi-directional mLSTM architecture with forward and partially flipped backward (PF-mLSTM) streams. The PF-mLSTM enhances localized context modeling by processing the initial sequence segment in reverse with dedicated parameters, preserving critical short-range patterns. We further introduce an mLSTM-based multihead cross exponential gated fusion mechanism (MECGAF) that dynamically combines forward mLSTM outputs as query and key with PF-mLSTM outputs as value, optimizing short-range dependency capture while maintaining global context and efficiency. Experimental results on three benchmark datasets demonstrate that MEGA outperforms state-of-the-art baselines, achieving superior accuracy and efficiency in ABSA tasks.
vGamba: Attentive State Space Bottleneck for efficient Long-range Dependencies in Visual Recognition
Mar 27, 2025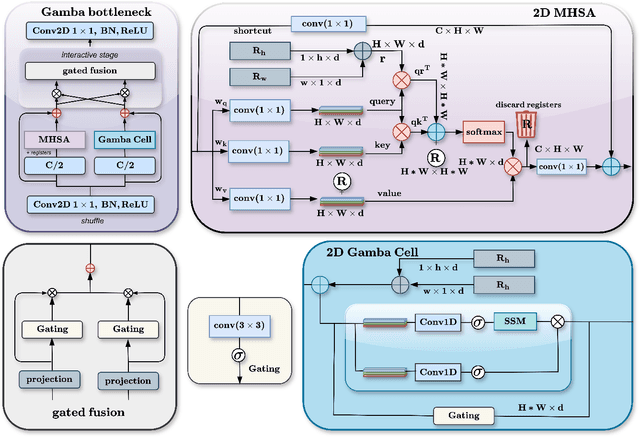
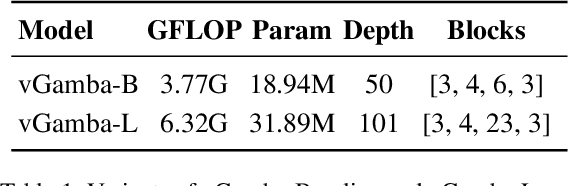
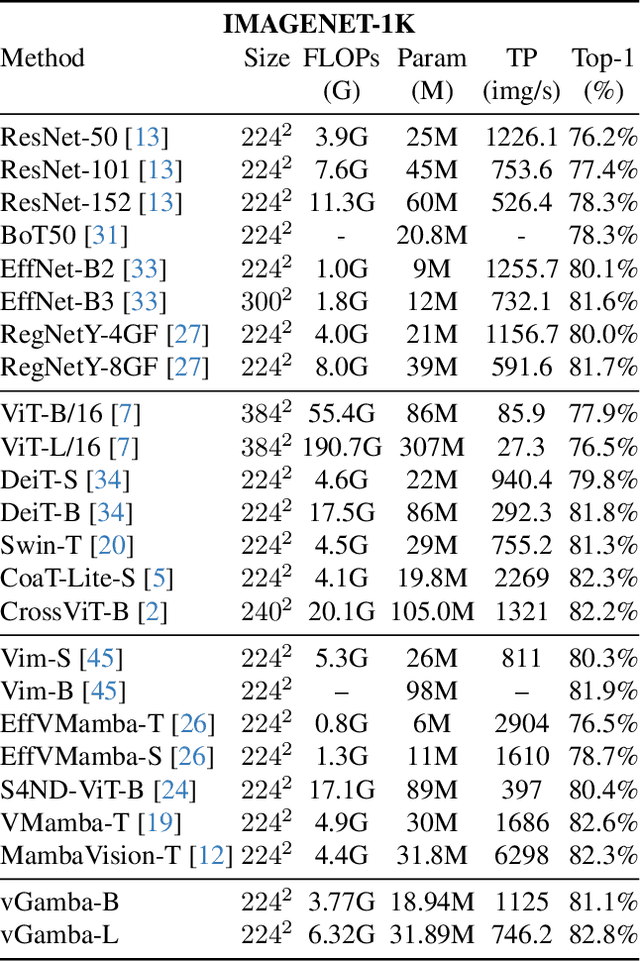

Capturing long-range dependencies efficiently is essential for visual recognition tasks, yet existing methods face limitations. Convolutional neural networks (CNNs) struggle with restricted receptive fields, while Vision Transformers (ViTs) achieve global context and long-range modeling at a high computational cost. State-space models (SSMs) offer an alternative, but their application in vision remains underexplored. This work introduces vGamba, a hybrid vision backbone that integrates SSMs with attention mechanisms to enhance efficiency and expressiveness. At its core, the Gamba bottleneck block that includes, Gamba Cell, an adaptation of Mamba for 2D spatial structures, alongside a Multi-Head Self-Attention (MHSA) mechanism and a Gated Fusion Module for effective feature representation. The interplay of these components ensures that vGamba leverages the low computational demands of SSMs while maintaining the accuracy of attention mechanisms for modeling long-range dependencies in vision tasks. Additionally, the Fusion module enables seamless interaction between these components. Extensive experiments on classification, detection, and segmentation tasks demonstrate that vGamba achieves a superior trade-off between accuracy and computational efficiency, outperforming several existing models.
Detecting Dark Patterns in User Interfaces Using Logistic Regression and Bag-of-Words Representation
Dec 09, 2024Dark patterns in user interfaces represent deceptive design practices intended to manipulate users' behavior, often leading to unintended consequences such as coerced purchases, involuntary data disclosures, or user frustration. Detecting and mitigating these dark patterns is crucial for promoting transparency, trust, and ethical design practices in digital environments. This paper proposes a novel approach for detecting dark patterns in user interfaces using logistic regression and bag-of-words representation. Our methodology involves collecting a diverse dataset of user interface text samples, preprocessing the data, extracting text features using the bag-of-words representation, training a logistic regression model, and evaluating its performance using various metrics such as accuracy, precision, recall, F1-score, and the area under the ROC curve (AUC). Experimental results demonstrate the effectiveness of the proposed approach in accurately identifying instances of dark patterns, with high predictive performance and robustness to variations in dataset composition and model parameters. The insights gained from this study contribute to the growing body of knowledge on dark patterns detection and classification, offering practical implications for designers, developers, and policymakers in promoting ethical design practices and protecting user rights in digital environments.
DualKanbaFormer: Kolmogorov-Arnold Networks and State Space Model Transformer for Multimodal Aspect-based Sentiment Analysis
Aug 30, 2024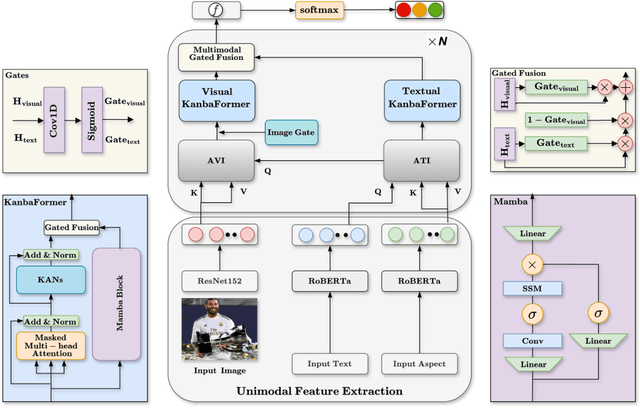
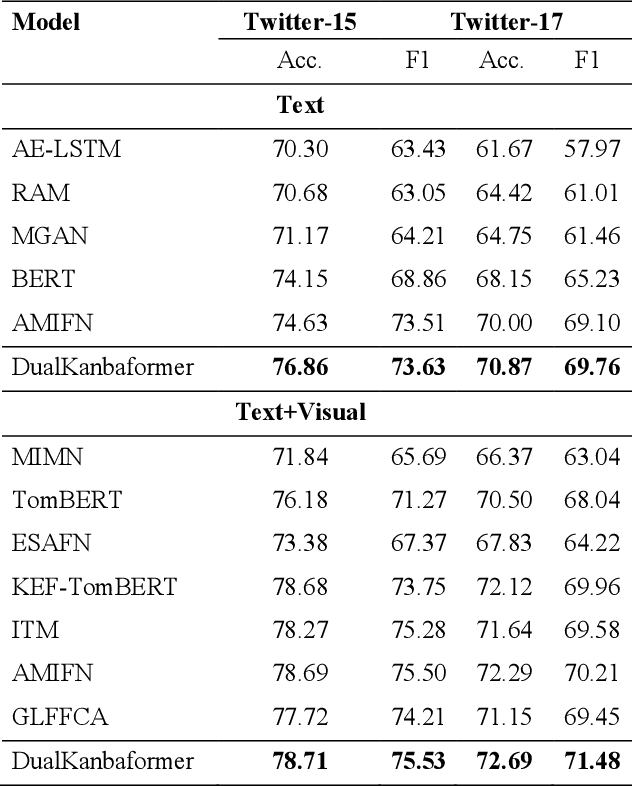
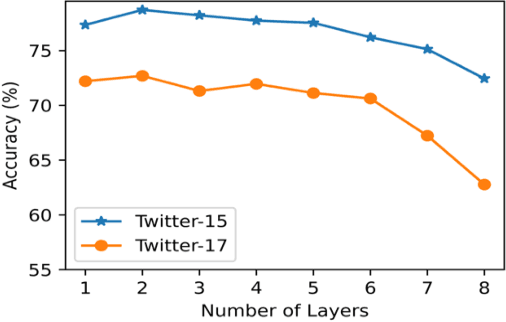
Multimodal aspect-based sentiment analysis (MABSA) enhances sentiment detection by combining text with other data types like images. However, despite setting significant benchmarks, attention mechanisms exhibit limitations in efficiently modelling long-range dependencies between aspect and opinion targets within the text. They also face challenges in capturing global-context dependencies for visual representations. To this end, we propose Kolmogorov-Arnold Networks (KANs) and Selective State Space model (Mamba) transformer (DualKanbaFormer), a novel architecture to address the above issues. We leverage the power of Mamba to capture global context dependencies, Multi-head Attention (MHA) to capture local context dependencies, and KANs to capture non-linear modelling patterns for both textual representations (textual KanbaFormer) and visual representations (visual KanbaFormer). Furthermore, we fuse the textual KanbaFormer and visual KanbaFomer with a gated fusion layer to capture the inter-modality dynamics. According to extensive experimental results, our model outperforms some state-of-the-art (SOTA) studies on two public datasets.
KonvLiNA: Integrating Kolmogorov-Arnold Network with Linear Nyström Attention for feature fusion in Crop Field Detection
Aug 23, 2024Crop field detection is a critical component of precision agriculture, essential for optimizing resource allocation and enhancing agricultural productivity. This study introduces KonvLiNA, a novel framework that integrates Convolutional Kolmogorov-Arnold Networks (cKAN) with Nystr\"om attention mechanisms for effective crop field detection. Leveraging KAN adaptive activation functions and the efficiency of Nystr\"om attention in handling largescale data, KonvLiNA significantly enhances feature extraction, enabling the model to capture intricate patterns in complex agricultural environments. Experimental results on rice crop dataset demonstrate KonvLiNA superiority over state-of-the-art methods, achieving a 0.415 AP and 0.459 AR with the Swin-L backbone, outperforming traditional YOLOv8 by significant margins. Additionally, evaluation on the COCO dataset showcases competitive performance across small, medium, and large objects, highlighting KonvLiNA efficacy in diverse agricultural settings. This work highlights the potential of hybrid KAN and attention mechanisms for advancing precision agriculture through improved crop field detection and management.
MambaForGCN: Enhancing Long-Range Dependency with State Space Model and Kolmogorov-Arnold Networks for Aspect-Based Sentiment Analysis
Jul 14, 2024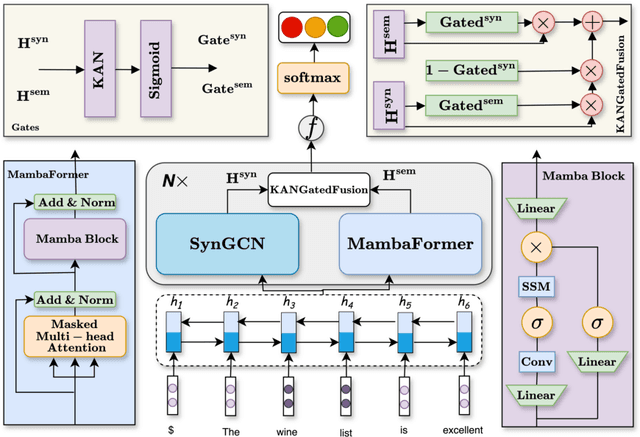
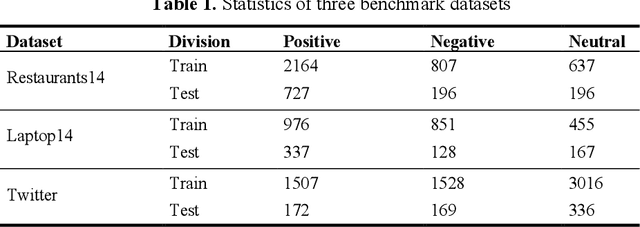
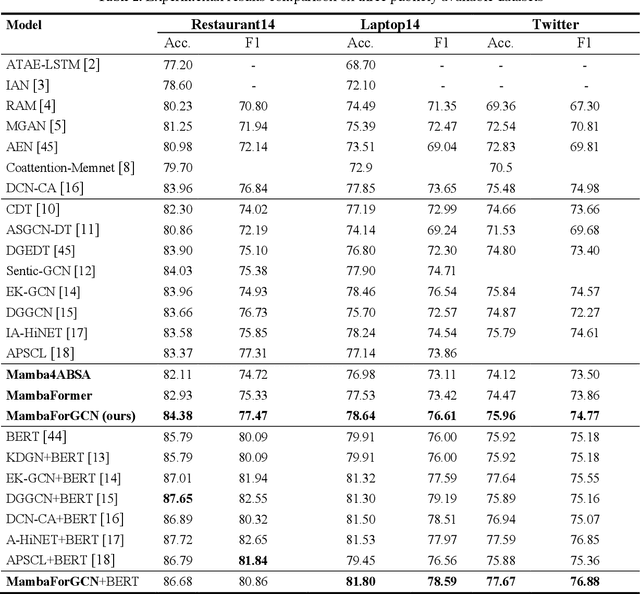
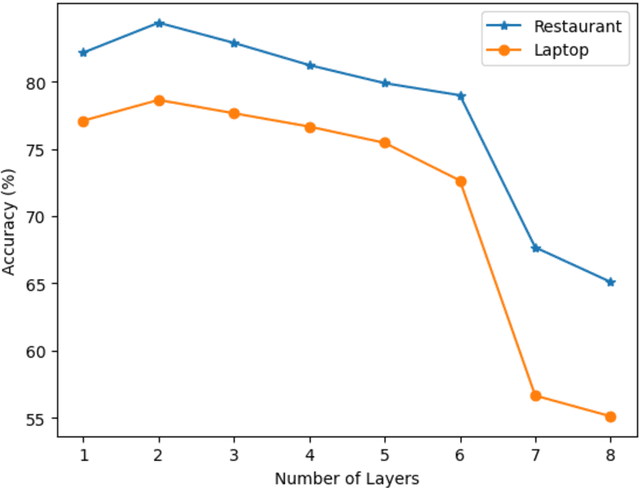
Aspect-based sentiment Analysis (ABSA) identifies and evaluates sentiments toward specific aspects of entities within text, providing detailed insights beyond overall sentiment. However, Attention mechanisms and neural network models struggle with syntactic constraints, and the quadratic complexity of attention mechanisms hinders their adoption for capturing long-range dependencies between aspect and opinion words in ABSA. This complexity can lead to the misinterpretation of irrelevant con-textual words, restricting their effectiveness to short-range dependencies. Some studies have investigated merging semantic and syntactic approaches but face challenges in effectively integrating these methods. To address the above problems, we present MambaForGCN, a novel approach to enhance short and long-range dependencies between aspect and opinion words in ABSA. This innovative approach incorporates syntax-based Graph Convolutional Network (SynGCN) and MambaFormer (Mamba-Transformer) modules to encode input with dependency relations and semantic information. The Multihead Attention (MHA) and Mamba blocks in the MambaFormer module serve as channels to enhance the model with short and long-range dependencies between aspect and opinion words. We also introduce the Kolmogorov-Arnold Networks (KANs) gated fusion, an adaptively integrated feature representation system combining SynGCN and MambaFormer representations. Experimental results on three benchmark datasets demonstrate MambaForGCN's effectiveness, outperforming state-of-the-art (SOTA) baseline models.
iiANET: Inception Inspired Attention Hybrid Network for efficient Long-Range Dependency
Jul 10, 2024
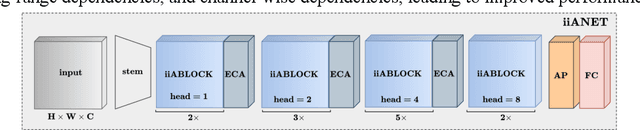
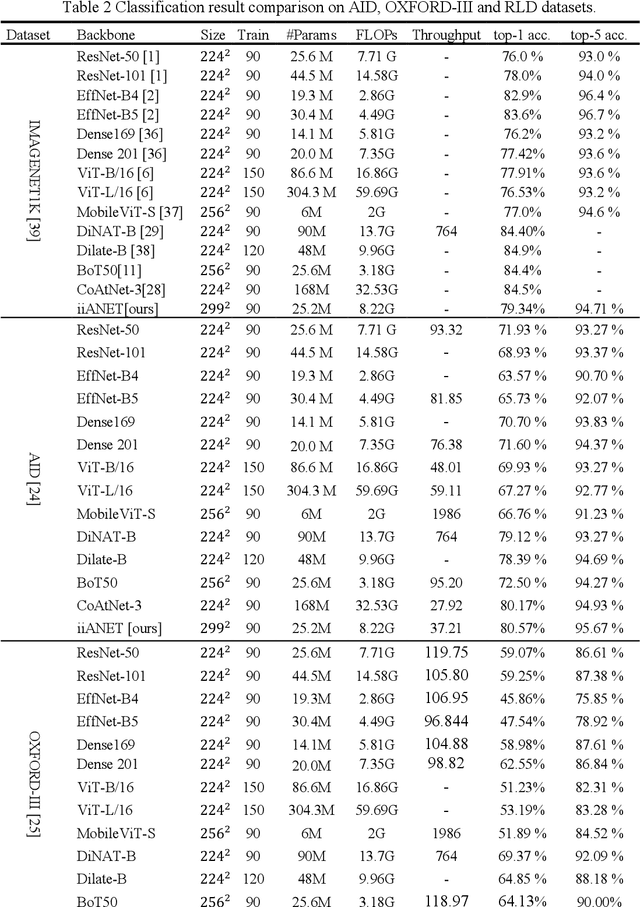

The recent emergence of hybrid models has introduced another transformative approach to solving computer vision tasks, slowly shifting away from conventional CNN (Convolutional Neural Network) and ViT (Vision Transformer). However, not enough effort has been made to efficiently combine these two approaches to improve capturing long-range dependencies prevalent in complex images. In this paper, we introduce iiANET (Inception Inspired Attention Network), an efficient hybrid model designed to capture long-range dependencies in complex images. The fundamental building block, iiABlock, integrates global 2D-MHSA (Multi-Head Self-Attention) with Registers, MBConv2 (MobileNetV2-based convolution), and dilated convolution in parallel, enabling the model to adeptly leverage self-attention for capturing long-range dependencies while utilizing MBConv2 for effective local-detail extraction and dilated convolution for efficiently expanding the kernel receptive field to capture more contextual information. Lastly, we serially integrate an ECANET (Efficient Channel Attention Network) at the end of each iiABlock to calibrate channel-wise attention for enhanced model performance. Extensive qualitative and quantitative comparative evaluation on various benchmarks demonstrates improved performance over some state-of-the-art models.
mAPm: multi-scale Attention Pyramid module for Enhanced scale-variation in RLD detection
Feb 26, 2024Detecting objects across various scales remains a significant challenge in computer vision, particularly in tasks such as Rice Leaf Disease (RLD) detection, where objects exhibit considerable scale variations. Traditional object detection methods often struggle to address these variations, resulting in missed detections or reduced accuracy. In this study, we propose the multi-scale Attention Pyramid module (mAPm), a novel approach that integrates dilated convolutions into the Feature Pyramid Network (FPN) to enhance multi-scale information ex-traction. Additionally, we incorporate a global Multi-Head Self-Attention (MHSA) mechanism and a deconvolutional layer to refine the up-sampling process. We evaluate mAPm on YOLOv7 using the MRLD and COCO datasets. Compared to vanilla FPN, BiFPN, NAS-FPN, PANET, and ACFPN, mAPm achieved a significant improvement in Average Precision (AP), with a +2.61% increase on the MRLD dataset compared to the baseline FPN method in YOLOv7. This demonstrates its effectiveness in handling scale variations. Furthermore, the versatility of mAPm allows its integration into various FPN-based object detection models, showcasing its potential to advance object detection techniques.
Exploring the Synergies of Hybrid CNNs and ViTs Architectures for Computer Vision: A survey
Feb 05, 2024The hybrid of Convolutional Neural Network (CNN) and Vision Transformers (ViT) architectures has emerged as a groundbreaking approach, pushing the boundaries of computer vision (CV). This comprehensive review provides a thorough examination of the literature on state-of-the-art hybrid CNN-ViT architectures, exploring the synergies between these two approaches. The main content of this survey includes: (1) a background on the vanilla CNN and ViT, (2) systematic review of various taxonomic hybrid designs to explore the synergy achieved through merging CNNs and ViTs models, (3) comparative analysis and application task-specific synergy between different hybrid architectures, (4) challenges and future directions for hybrid models, (5) lastly, the survey concludes with a summary of key findings and recommendations. Through this exploration of hybrid CV architectures, the survey aims to serve as a guiding resource, fostering a deeper understanding of the intricate dynamics between CNNs and ViTs and their collective impact on shaping the future of CV architectures.