 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgevGamba: Attentive State Space Bottleneck for efficient Long-range Dependencies in Visual Recognition
Paper and Code
Mar 27, 2025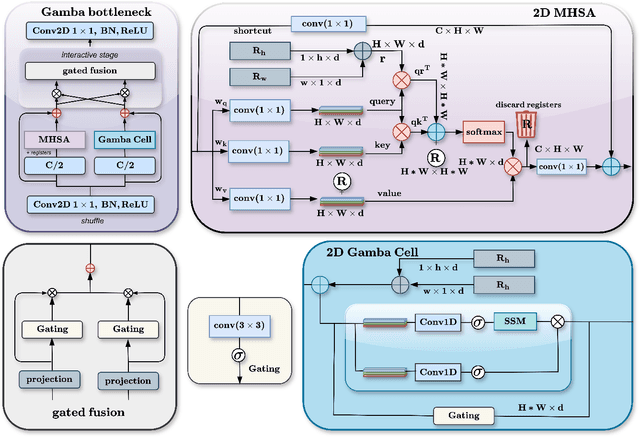
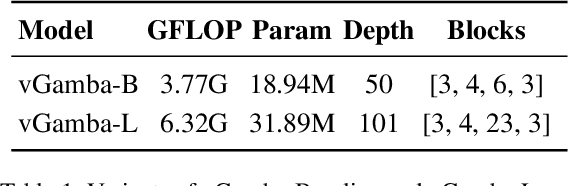
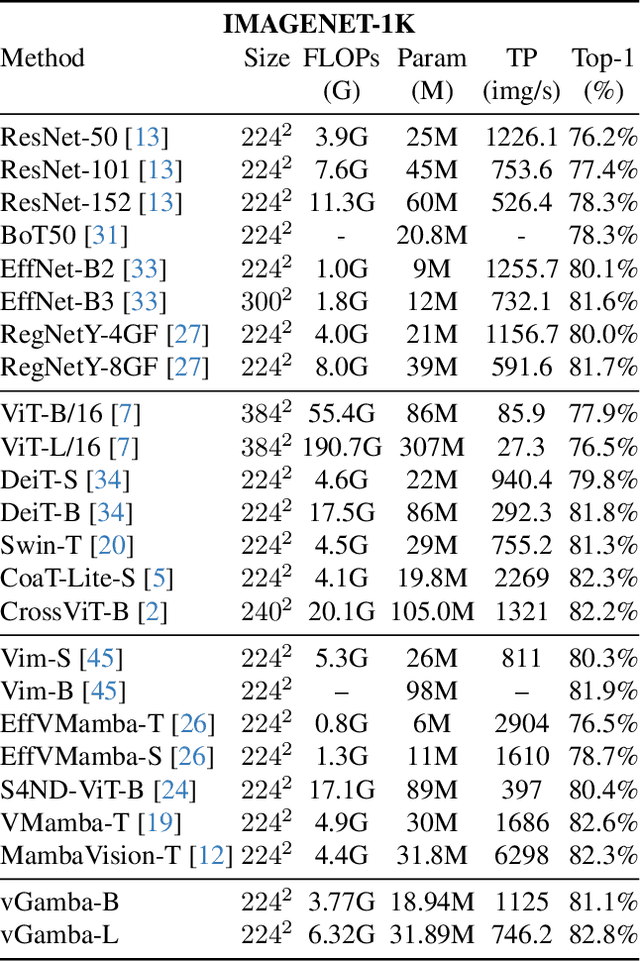

Capturing long-range dependencies efficiently is essential for visual recognition tasks, yet existing methods face limitations. Convolutional neural networks (CNNs) struggle with restricted receptive fields, while Vision Transformers (ViTs) achieve global context and long-range modeling at a high computational cost. State-space models (SSMs) offer an alternative, but their application in vision remains underexplored. This work introduces vGamba, a hybrid vision backbone that integrates SSMs with attention mechanisms to enhance efficiency and expressiveness. At its core, the Gamba bottleneck block that includes, Gamba Cell, an adaptation of Mamba for 2D spatial structures, alongside a Multi-Head Self-Attention (MHSA) mechanism and a Gated Fusion Module for effective feature representation. The interplay of these components ensures that vGamba leverages the low computational demands of SSMs while maintaining the accuracy of attention mechanisms for modeling long-range dependencies in vision tasks. Additionally, the Fusion module enables seamless interaction between these components. Extensive experiments on classification, detection, and segmentation tasks demonstrate that vGamba achieves a superior trade-off between accuracy and computational efficiency, outperforming several existing models.