 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Redistribution in Visual Machine Unlearning: Does Forgetting One Group Harm Another?
Apr 09, 2026Machine unlearning enables models to selectively forget training data, driven by privacy regulations such as GDPR and CCPA. However, its fairness implications remain underexplored: when a model forgets a demographic group, does it neutralize that concept or redistribute it to correlated groups, potentially amplifying bias? We investigate this bias redistribution phenomenon on CelebA using CLIP models (ViT/B-32, ViT-L/14, ViT-B/16) under a zero-shot classification setting across intersectional groups defined by age and gender. We evaluate three unlearning methods, Prompt Erasure, Prompt Reweighting, and Refusal Vector using per-group accuracy shifts, demographic parity gaps, and a redistribution score. Our results show that unlearning does not eliminate bias but redistributes it primarily along gender rather than age boundaries. In particular, removing the dominant Young Female group consistently transfers performance to Old Female across all model scales, revealing a gender-dominant structure in CLIP's embedding space. While the Refusal Vector method reduces redistribution, it fails to achieve complete forgetting and significantly degrades retained performance. These findings highlight a fundamental limitation of current unlearning methods: without accounting for embedding geometry, they risk amplifying bias in retained groups.
MOSAIC: A Unified Platform for Cross-Paradigm Comparison and Evaluation of Homogeneous and Heterogeneous Multi-Agent RL, LLM, VLM, and Human Decision-Makers
Mar 01, 2026Reinforcement learning (RL), large language models (LLMs), and vision-language models (VLMs) have been widely studied in isolation. However, existing infrastructure lacks the ability to deploy agents from different decision-making paradigms within the same environment, making it difficult to study them in hybrid multi-agent settings or to compare their behaviour fairly under identical conditions. We present MOSAIC, an open-source platform that bridges this gap by incorporating a diverse set of existing reinforcement learning environments and enabling heterogeneous agents (RL policies, LLMs, VLMs, and human players) to operate within them in ad-hoc team settings with reproducible results. MOSAIC introduces three contributions. (i) An IPC-based worker protocol that wraps both native and third-party frameworks as isolated subprocess workers, each executing its native training and inference logic unmodified, communicating through a versioned inter-process protocol. (ii) An operator abstraction that forms an agent-level interface by mapping workers to agents: each operator, regardless of whether it is backed by an RL policy, an LLM, or a human, conforms to a minimal unified interface. (iii) A deterministic cross-paradigm evaluation framework offering two complementary modes: a manual mode that advances up to N concurrent operators in lock-step under shared seeds for fine-grained visual inspection of behavioural differences, and a script mode that drives automated, long-running evaluation through declarative Python scripts, for reproducible experiments. We release MOSAIC as an open, visual-first platform to facilitate reproducible cross-paradigm research across the RL, LLM, and human-in-the-loop communities.
vGamba: Attentive State Space Bottleneck for efficient Long-range Dependencies in Visual Recognition
Mar 27, 2025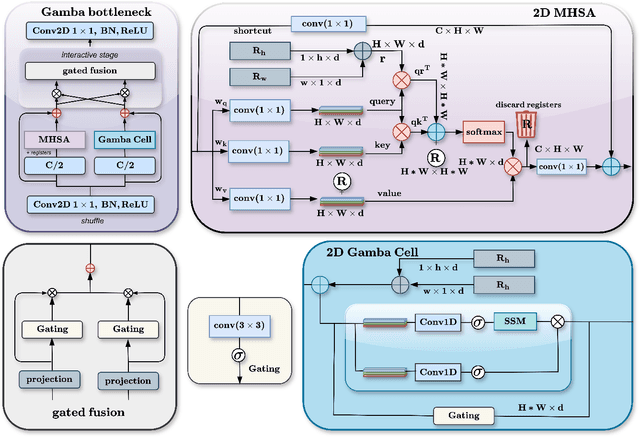
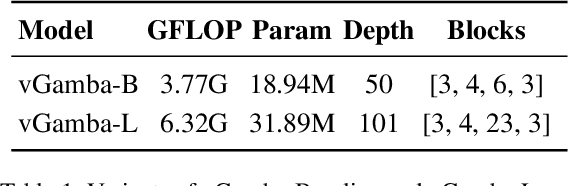
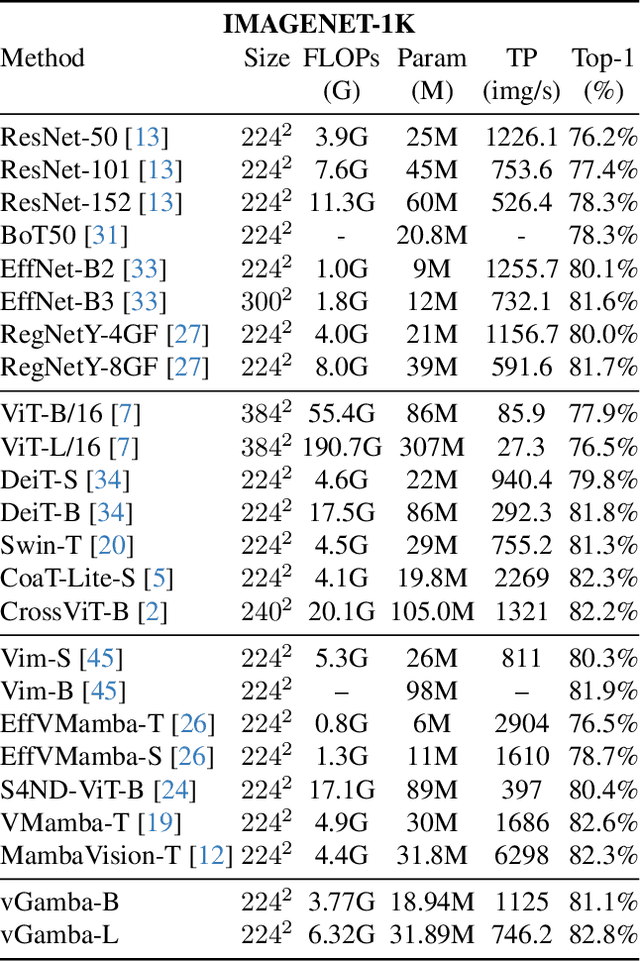

Capturing long-range dependencies efficiently is essential for visual recognition tasks, yet existing methods face limitations. Convolutional neural networks (CNNs) struggle with restricted receptive fields, while Vision Transformers (ViTs) achieve global context and long-range modeling at a high computational cost. State-space models (SSMs) offer an alternative, but their application in vision remains underexplored. This work introduces vGamba, a hybrid vision backbone that integrates SSMs with attention mechanisms to enhance efficiency and expressiveness. At its core, the Gamba bottleneck block that includes, Gamba Cell, an adaptation of Mamba for 2D spatial structures, alongside a Multi-Head Self-Attention (MHSA) mechanism and a Gated Fusion Module for effective feature representation. The interplay of these components ensures that vGamba leverages the low computational demands of SSMs while maintaining the accuracy of attention mechanisms for modeling long-range dependencies in vision tasks. Additionally, the Fusion module enables seamless interaction between these components. Extensive experiments on classification, detection, and segmentation tasks demonstrate that vGamba achieves a superior trade-off between accuracy and computational efficiency, outperforming several existing models.
VulCatch: Enhancing Binary Vulnerability Detection through CodeT5 Decompilation and KAN Advanced Feature Extraction
Aug 13, 2024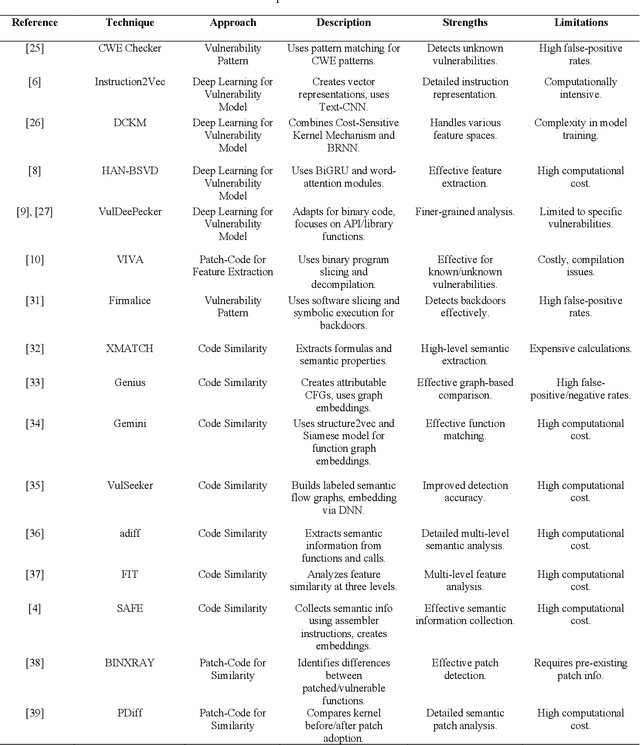

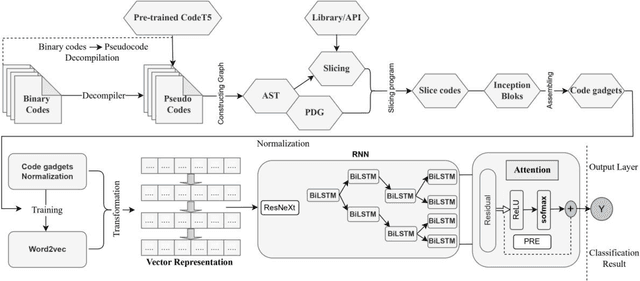
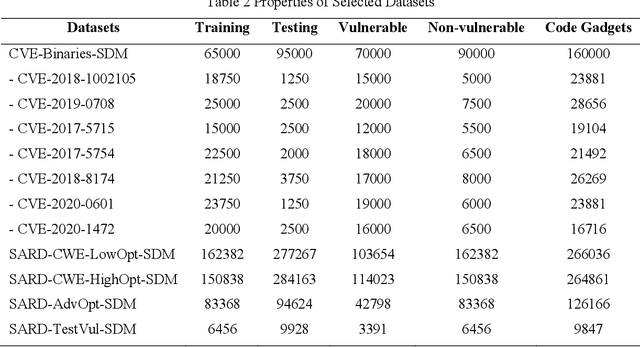
Binary program vulnerability detection is critical for software security, yet existing deep learning approaches often rely on source code analysis, limiting their ability to detect unknown vulnerabilities. To address this, we propose VulCatch, a binary-level vulnerability detection framework. VulCatch introduces a Synergy Decompilation Module (SDM) and Kolmogorov-Arnold Networks (KAN) to transform raw binary code into pseudocode using CodeT5, preserving high-level semantics for deep analysis with tools like Ghidra and IDA. KAN further enhances feature transformation, enabling the detection of complex vulnerabilities. VulCatch employs word2vec, Inception Blocks, BiLSTM Attention, and Residual connections to achieve high detection accuracy (98.88%) and precision (97.92%), while minimizing false positives (1.56%) and false negatives (2.71%) across seven CVE datasets.
mAPm: multi-scale Attention Pyramid module for Enhanced scale-variation in RLD detection
Feb 26, 2024Detecting objects across various scales remains a significant challenge in computer vision, particularly in tasks such as Rice Leaf Disease (RLD) detection, where objects exhibit considerable scale variations. Traditional object detection methods often struggle to address these variations, resulting in missed detections or reduced accuracy. In this study, we propose the multi-scale Attention Pyramid module (mAPm), a novel approach that integrates dilated convolutions into the Feature Pyramid Network (FPN) to enhance multi-scale information ex-traction. Additionally, we incorporate a global Multi-Head Self-Attention (MHSA) mechanism and a deconvolutional layer to refine the up-sampling process. We evaluate mAPm on YOLOv7 using the MRLD and COCO datasets. Compared to vanilla FPN, BiFPN, NAS-FPN, PANET, and ACFPN, mAPm achieved a significant improvement in Average Precision (AP), with a +2.61% increase on the MRLD dataset compared to the baseline FPN method in YOLOv7. This demonstrates its effectiveness in handling scale variations. Furthermore, the versatility of mAPm allows its integration into various FPN-based object detection models, showcasing its potential to advance object detection techniques.