 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualKanbaFormer: Kolmogorov-Arnold Networks and State Space Model Transformer for Multimodal Aspect-based Sentiment Analysis
Aug 30, 2024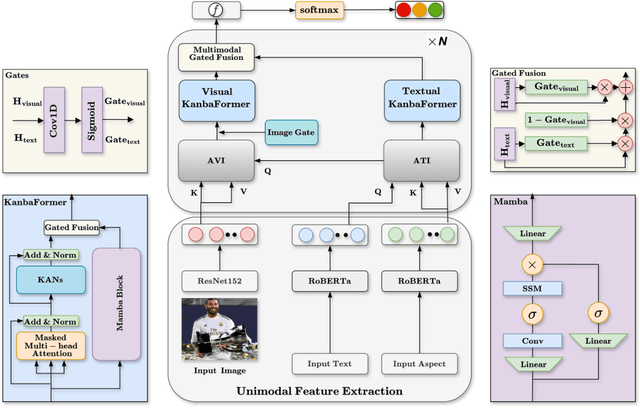
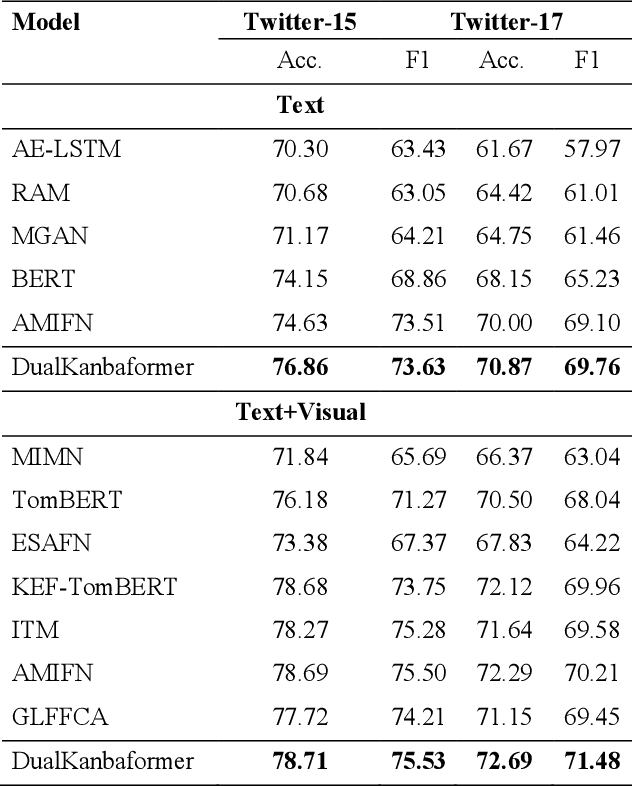
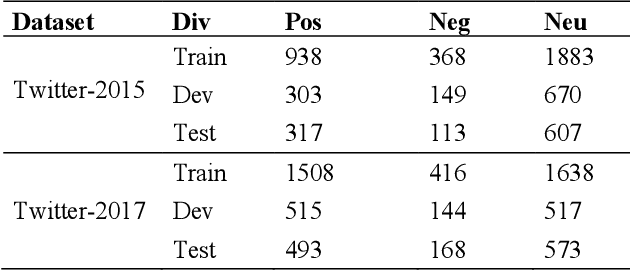
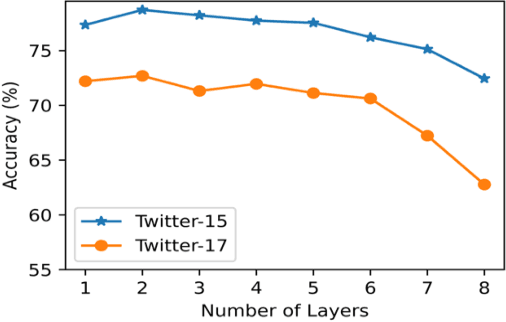
Multimodal aspect-based sentiment analysis (MABSA) enhances sentiment detection by combining text with other data types like images. However, despite setting significant benchmarks, attention mechanisms exhibit limitations in efficiently modelling long-range dependencies between aspect and opinion targets within the text. They also face challenges in capturing global-context dependencies for visual representations. To this end, we propose Kolmogorov-Arnold Networks (KANs) and Selective State Space model (Mamba) transformer (DualKanbaFormer), a novel architecture to address the above issues. We leverage the power of Mamba to capture global context dependencies, Multi-head Attention (MHA) to capture local context dependencies, and KANs to capture non-linear modelling patterns for both textual representations (textual KanbaFormer) and visual representations (visual KanbaFormer). Furthermore, we fuse the textual KanbaFormer and visual KanbaFomer with a gated fusion layer to capture the inter-modality dynamics. According to extensive experimental results, our model outperforms some state-of-the-art (SOTA) studies on two public datasets.