 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Detection of Pre-training Text in Black-box LLMs
Jun 24, 2025Detecting whether a given text is a member of the pre-training data of Large Language Models (LLMs) is crucial for ensuring data privacy and copyright protection. Most existing methods rely on the LLM's hidden information (e.g., model parameters or token probabilities), making them ineffective in the black-box setting, where only input and output texts are accessible. Although some methods have been proposed for the black-box setting, they rely on massive manual efforts such as designing complicated questions or instructions. To address these issues, we propose VeilProbe, the first framework for automatically detecting LLMs' pre-training texts in a black-box setting without human intervention. VeilProbe utilizes a sequence-to-sequence mapping model to infer the latent mapping feature between the input text and the corresponding output suffix generated by the LLM. Then it performs the key token perturbations to obtain more distinguishable membership features. Additionally, considering real-world scenarios where the ground-truth training text samples are limited, a prototype-based membership classifier is introduced to alleviate the overfitting issue. Extensive evaluations on three widely used datasets demonstrate that our framework is effective and superior in the black-box setting.
A Novel Prompt-tuning Method: Incorporating Scenario-specific Concepts into a Verbalizer
Jan 10, 2024



The verbalizer, which serves to map label words to class labels, is an essential component of prompt-tuning. In this paper, we present a novel approach to constructing verbalizers. While existing methods for verbalizer construction mainly rely on augmenting and refining sets of synonyms or related words based on class names, this paradigm suffers from a narrow perspective and lack of abstraction, resulting in limited coverage and high bias in the label-word space. To address this issue, we propose a label-word construction process that incorporates scenario-specific concepts. Specifically, we extract rich concepts from task-specific scenarios as label-word candidates and then develop a novel cascade calibration module to refine the candidates into a set of label words for each class. We evaluate the effectiveness of our proposed approach through extensive experiments on {five} widely used datasets for zero-shot text classification. The results demonstrate that our method outperforms existing methods and achieves state-of-the-art results.
CodePrompt: Improving Source Code-Related Classification with Knowledge Features through Prompt Learning
Jan 10, 2024Researchers have explored the potential of utilizing pre-trained language models, such as CodeBERT, to improve source code-related tasks. Previous studies have mainly relied on CodeBERT's text embedding capability and the `[CLS]' sentence embedding information as semantic representations for fine-tuning downstream source code-related tasks. However, these methods require additional neural network layers to extract effective features, resulting in higher computational costs. Furthermore, existing approaches have not leveraged the rich knowledge contained in both source code and related text, which can lead to lower accuracy. This paper presents a novel approach, CodePrompt, which utilizes rich knowledge recalled from a pre-trained model by prompt learning and an attention mechanism to improve source code-related classification tasks. Our approach initially motivates the language model with prompt information to retrieve abundant knowledge associated with the input as representative features, thus avoiding the need for additional neural network layers and reducing computational costs. Subsequently, we employ an attention mechanism to aggregate multiple layers of related knowledge for each task as final features to boost their accuracy. We conducted extensive experiments on four downstream source code-related tasks to evaluate our approach and our results demonstrate that CodePrompt achieves new state-of-the-art performance on the accuracy metric while also exhibiting computation cost-saving capabilities.
Relational Triple Extraction: One Step is Enough
May 11, 2022
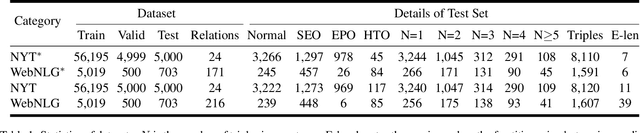
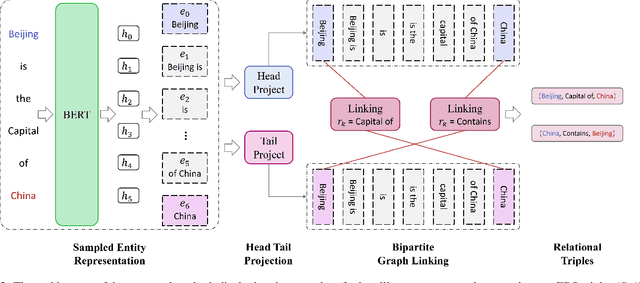
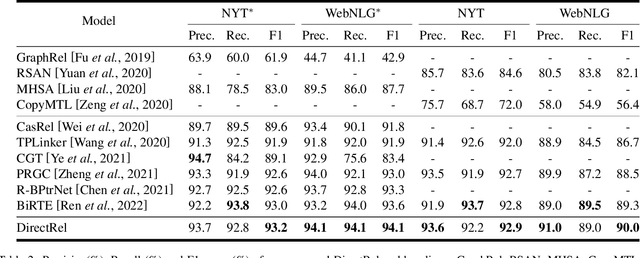
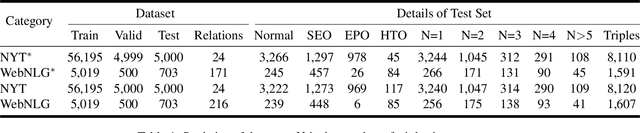
Extracting relational triples from unstructured text is an essential task in natural language processing and knowledge graph construction. Existing approaches usually contain two fundamental steps: (1) finding the boundary positions of head and tail entities; (2) concatenating specific tokens to form triples. However, nearly all previous methods suffer from the problem of error accumulation, i.e., the boundary recognition error of each entity in step (1) will be accumulated into the final combined triples. To solve the problem, in this paper, we introduce a fresh perspective to revisit the triple extraction task, and propose a simple but effective model, named DirectRel. Specifically, the proposed model first generates candidate entities through enumerating token sequences in a sentence, and then transforms the triple extraction task into a linking problem on a "head $\rightarrow$ tail" bipartite graph. By doing so, all triples can be directly extracted in only one step. Extensive experimental results on two widely used datasets demonstrate that the proposed model performs better than the state-of-the-art baselines.
OneRel:Joint Entity and Relation Extraction with One Module in One Step
Mar 17, 2022
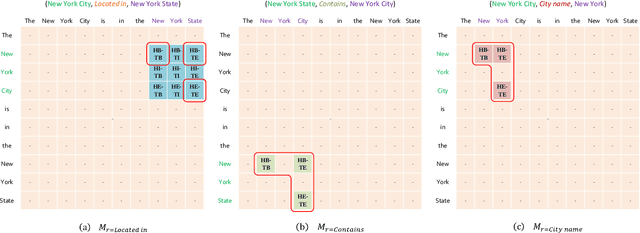
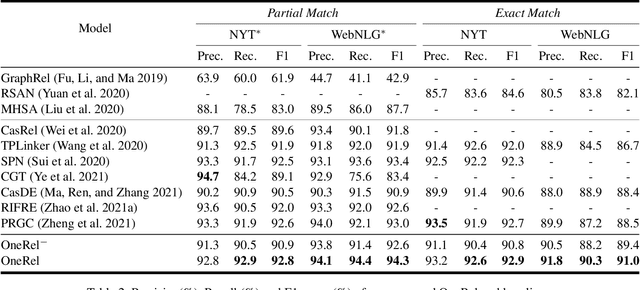
Joint entity and relation extraction is an essential task in natural language processing and knowledge graph construction. Existing approaches usually decompose the joint extraction task into several basic modules or processing steps to make it easy to conduct. However, such a paradigm ignores the fact that the three elements of a triple are interdependent and indivisible. Therefore, previous joint methods suffer from the problems of cascading errors and redundant information. To address these issues, in this paper, we propose a novel joint entity and relation extraction model, named OneRel, which casts joint extraction as a fine-grained triple classification problem. Specifically, our model consists of a scoring-based classifier and a relation-specific horns tagging strategy. The former evaluates whether a token pair and a relation belong to a factual triple. The latter ensures a simple but effective decoding process. Extensive experimental results on two widely used datasets demonstrate that the proposed method performs better than the state-of-the-art baselines, and delivers consistent performance gain on complex scenarios of various overlapping patterns and multiple triples.