 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Variance: Prompt-Efficient RLVR via Rare-Event Amplification and Bidirectional Pairing
Feb 03, 2026Reinforcement learning with verifiable rewards (RLVR) is effective for training large language models on deterministic outcome reasoning tasks. Prior work shows RLVR works with few prompts, but prompt selection is often based only on training-accuracy variance, leading to unstable optimization directions and weaker transfer. We revisit prompt selection from a mechanism-level view and argue that an effective minibatch should provide both (i) a reliable positive anchor and (ii) explicit negative learning signals from rare failures. Based on this principle, we propose \emph{positive--negative pairing}: at each update, we sample a hard-but-solvable $q^{+}$ and an easy-but-brittle prompt $q^{-}$(high success rate but not perfect), characterized by low and high empirical success rates under multiple rollouts. We further introduce Weighted GRPO, which reweights binary outcomes at the pair level and uses group-normalized advantages to amplify rare successes on $q^{+}$ into sharp positive guidance while turning rare failures on $q^{-}$ into strong negative penalties. This bidirectional signal provides informative learning feedback for both successes and failures, improving sample efficiency without suppressing exploration. On Qwen2.5-Math-7B, a single paired minibatch per update consistently outperforms a GRPO baseline that selects two prompts via commonly used variance-based selection heuristics: AIME~2025 Pass@8 improves from 16.8 to 22.2, and AMC23 Pass@64 from 94.0 to 97.0, while remaining competitive with large-scale RLVR trained from a pool of 1209 training prompts. Similar gains are observed on Qwen2.5-Math-7B-Instruct.
DistillMatch: Leveraging Knowledge Distillation from Vision Foundation Model for Multimodal Image Matching
Sep 19, 2025Multimodal image matching seeks pixel-level correspondences between images of different modalities, crucial for cross-modal perception, fusion and analysis. However, the significant appearance differences between modalities make this task challenging. Due to the scarcity of high-quality annotated datasets, existing deep learning methods that extract modality-common features for matching perform poorly and lack adaptability to diverse scenarios. Vision Foundation Model (VFM), trained on large-scale data, yields generalizable and robust feature representations adapted to data and tasks of various modalities, including multimodal matching. Thus, we propose DistillMatch, a multimodal image matching method using knowledge distillation from VFM. DistillMatch employs knowledge distillation to build a lightweight student model that extracts high-level semantic features from VFM (including DINOv2 and DINOv3) to assist matching across modalities. To retain modality-specific information, it extracts and injects modality category information into the other modality's features, which enhances the model's understanding of cross-modal correlations. Furthermore, we design V2I-GAN to boost the model's generalization by translating visible to pseudo-infrared images for data augmentation. Experiments show that DistillMatch outperforms existing algorithms on public datasets.
RIS-FUSION: Rethinking Text-Driven Infrared and Visible Image Fusion from the Perspective of Referring Image Segmentation
Sep 16, 2025Text-driven infrared and visible image fusion has gained attention for enabling natural language to guide the fusion process. However, existing methods lack a goal-aligned task to supervise and evaluate how effectively the input text contributes to the fusion outcome. We observe that referring image segmentation (RIS) and text-driven fusion share a common objective: highlighting the object referred to by the text. Motivated by this, we propose RIS-FUSION, a cascaded framework that unifies fusion and RIS through joint optimization. At its core is the LangGatedFusion module, which injects textual features into the fusion backbone to enhance semantic alignment. To support multimodal referring image segmentation task, we introduce MM-RIS, a large-scale benchmark with 12.5k training and 3.5k testing triplets, each consisting of an infrared-visible image pair, a segmentation mask, and a referring expression. Extensive experiments show that RIS-FUSION achieves state-of-the-art performance, outperforming existing methods by over 11% in mIoU. Code and dataset will be released at https://github.com/SijuMa2003/RIS-FUSION.
PromptAL: Sample-Aware Dynamic Soft Prompts for Few-Shot Active Learning
Jul 22, 2025Active learning (AL) aims to optimize model training and reduce annotation costs by selecting the most informative samples for labeling. Typically, AL methods rely on the empirical distribution of labeled data to define the decision boundary and perform uncertainty or diversity estimation, subsequently identifying potential high-quality samples. In few-shot scenarios, the empirical distribution often diverges significantly from the target distribution, causing the decision boundary to shift away from its optimal position. However, existing methods overlook the role of unlabeled samples in enhancing the empirical distribution to better align with the target distribution, resulting in a suboptimal decision boundary and the selection of samples that inadequately represent the target distribution. To address this, we propose a hybrid AL framework, termed \textbf{PromptAL} (Sample-Aware Dynamic Soft \textbf{Prompts} for Few-Shot \textbf{A}ctive \textbf{L}earning). This framework accounts for the contribution of each unlabeled data point in aligning the current empirical distribution with the target distribution, thereby optimizing the decision boundary. Specifically, PromptAL first leverages unlabeled data to construct sample-aware dynamic soft prompts that adjust the model's predictive distribution and decision boundary. Subsequently, based on the adjusted decision boundary, it integrates uncertainty estimation with both global and local diversity to select high-quality samples that more accurately represent the target distribution. Experimental results on six in-domain and three out-of-domain datasets show that PromptAL achieves superior performance over nine baselines. Our codebase is openly accessible.
Advancing User-Voice Interaction: Exploring Emotion-Aware Voice Assistants Through a Role-Swapping Approach
Feb 21, 2025As voice assistants (VAs) become increasingly integrated into daily life, the need for emotion-aware systems that can recognize and respond appropriately to user emotions has grown. While significant progress has been made in speech emotion recognition (SER) and sentiment analysis, effectively addressing user emotions-particularly negative ones-remains a challenge. This study explores human emotional response strategies in VA interactions using a role-swapping approach, where participants regulate AI emotions rather than receiving pre-programmed responses. Through speech feature analysis and natural language processing (NLP), we examined acoustic and linguistic patterns across various emotional scenarios. Results show that participants favor neutral or positive emotional responses when engaging with negative emotional cues, highlighting a natural tendency toward emotional regulation and de-escalation. Key acoustic indicators such as root mean square (RMS), zero-crossing rate (ZCR), and jitter were identified as sensitive to emotional states, while sentiment polarity and lexical diversity (TTR) distinguished between positive and negative responses. These findings provide valuable insights for developing adaptive, context-aware VAs capable of delivering empathetic, culturally sensitive, and user-aligned responses. By understanding how humans naturally regulate emotions in AI interactions, this research contributes to the design of more intuitive and emotionally intelligent voice assistants, enhancing user trust and engagement in human-AI interactions.
Improving Acoustic Scene Classification in Low-Resource Conditions
Dec 30, 2024



Acoustic Scene Classification (ASC) identifies an environment based on an audio signal. This paper explores ASC in low-resource conditions and proposes a novel model, DS-FlexiNet, which combines depthwise separable convolutions from MobileNetV2 with ResNet-inspired residual connections for a balance of efficiency and accuracy. To address hardware limitations and device heterogeneity, DS-FlexiNet employs Quantization Aware Training (QAT) for model compression and data augmentation methods like Auto Device Impulse Response (ADIR) and Freq-MixStyle (FMS) to improve cross-device generalization. Knowledge Distillation (KD) from twelve teacher models further enhances performance on unseen devices. The architecture includes a custom Residual Normalization layer to handle domain differences across devices, and depthwise separable convolutions reduce computational overhead without sacrificing feature representation. Experimental results show that DS-FlexiNet excels in both adaptability and performance under resource-constrained conditions.
The 1st InterAI Workshop: Interactive AI for Human-centered Robotics
Sep 17, 2024The workshop is affiliated with 33nd IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2024) August 26~30, 2023 / Pasadena, CA, USA. It is designed as a half-day event, extending over four hours from 9:00 to 12:30 PST time. It accommodates both in-person and virtual attendees (via Zoom), ensuring a flexible participation mode. The agenda is thoughtfully crafted to include a diverse range of sessions: two keynote speeches that promise to provide insightful perspectives, two dedicated paper presentation sessions, an interactive panel discussion to foster dialogue among experts which facilitates deeper dives into specific topics, and a 15-minute coffee break. The workshop website: https://sites.google.com/view/interaiworkshops/home.
Rotation center identification based on geometric relationships for rotary motion deblurring
Aug 08, 2024



Non-blind rotary motion deblurring (RMD) aims to recover the latent clear image from a rotary motion blurred (RMB) image. The rotation center is a crucial input parameter in non-blind RMD methods. Existing methods directly estimate the rotation center from the RMB image. However they always suffer significant errors, and the performance of RMD is limited. For the assembled imaging systems, the position of the rotation center remains fixed. Leveraging this prior knowledge, we propose a geometric-based method for rotation center identification and analyze its error range. Furthermore, we construct a RMB imaging system. The experiment demonstrates that our method achieves less than 1-pixel error along a single axis (x-axis or y-axis). We utilize the constructed imaging system to capture real RMB images, and experimental results show that our method can help existing RMD approaches yield better RMD images.
Vision Beyond Boundaries: An Initial Design Space of Domain-specific Large Vision Models in Human-robot Interaction
Apr 23, 2024The emergence of Large Vision Models (LVMs) is following in the footsteps of the recent prosperity of Large Language Models (LLMs) in following years. However, there's a noticeable gap in structured research applying LVMs to Human-Robot Interaction (HRI), despite extensive evidence supporting the efficacy of vision models in enhancing interactions between humans and robots. Recognizing the vast and anticipated potential, we introduce an initial design space that incorporates domain-specific LVMs, chosen for their superior performance over normal models. We delve into three primary dimensions: HRI contexts, vision-based tasks, and specific domains. The empirical validation was implemented among 15 experts across six evaluated metrics, showcasing the primary efficacy in relevant decision-making scenarios. We explore the process of ideation and potential application scenarios, envisioning this design space as a foundational guideline for future HRI system design, emphasizing accurate domain alignment and model selection.
Mind Meets Robots: A Review of EEG-Based Brain-Robot Interaction Systems
Mar 13, 2024


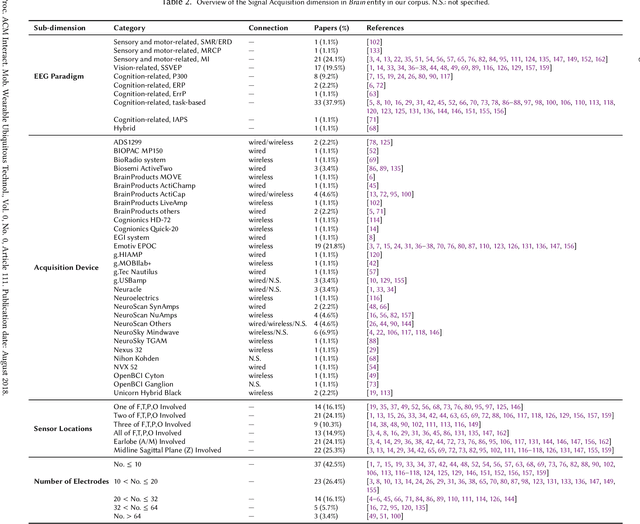
Brain-robot interaction (BRI) empowers individuals to control (semi-)automated machines through their brain activity, either passively or actively. In the past decade, BRI systems have achieved remarkable success, predominantly harnessing electroencephalogram (EEG) signals as the central component. This paper offers an up-to-date and exhaustive examination of 87 curated studies published during the last five years (2018-2023), focusing on identifying the research landscape of EEG-based BRI systems. This review aims to consolidate and underscore methodologies, interaction modes, application contexts, system evaluation, existing challenges, and potential avenues for future investigations in this domain. Based on our analysis, we present a BRI system model with three entities: Brain, Robot, and Interaction, depicting the internal relationships of a BRI system. We especially investigate the essence and principles on interaction modes between human brains and robots, a domain that has not yet been identified anywhere. We then discuss these entities with different dimensions encompassed. Within this model, we scrutinize and classify current research, reveal insights, specify challenges, and provide recommendations for future research trajectories in this field. Meanwhile, we envision our findings offer a design space for future human-robot interaction (HRI) research, informing the creation of efficient BRI frameworks.