 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Video Object Segmentation in X-Ray Angiography Using Local Matching and Spatio-Temporal Consistency Loss
Jan 02, 2026We introduce a novel FSVOS model that employs a local matching strategy to restrict the search space to the most relevant neighboring pixels. Rather than relying on inefficient standard im2col-like implementations (e.g., spatial convolutions, depthwise convolutions and feature-shifting mechanisms) or hardware-specific CUDA kernels (e.g., deformable and neighborhood attention), which often suffer from limited portability across non-CUDA devices, we reorganize the local sampling process through a direction-based sampling perspective. Specifically, we implement a non-parametric sampling mechanism that enables dynamically varying sampling regions. This approach provides the flexibility to adapt to diverse spatial structures without the computational costs of parametric layers and the need for model retraining. To further enhance feature coherence across frames, we design a supervised spatio-temporal contrastive learning scheme that enforces consistency in feature representations. In addition, we introduce a publicly available benchmark dataset for multi-object segmentation in X-ray angiography videos (MOSXAV), featuring detailed, manually labeled segmentation ground truth. Extensive experiments on the CADICA, XACV, and MOSXAV datasets show that our proposed FSVOS method outperforms current state-of-the-art video segmentation methods in terms of segmentation accuracy and generalization capability (i.e., seen and unseen categories). This work offers enhanced flexibility and potential for a wide range of clinical applications.
Robust Noisy Pseudo-label Learning for Semi-supervised Medical Image Segmentation Using Diffusion Model
Jul 22, 2025Obtaining pixel-level annotations in the medical domain is both expensive and time-consuming, often requiring close collaboration between clinical experts and developers. Semi-supervised medical image segmentation aims to leverage limited annotated data alongside abundant unlabeled data to achieve accurate segmentation. However, existing semi-supervised methods often struggle to structure semantic distributions in the latent space due to noise introduced by pseudo-labels. In this paper, we propose a novel diffusion-based framework for semi-supervised medical image segmentation. Our method introduces a constraint into the latent structure of semantic labels during the denoising diffusion process by enforcing prototype-based contrastive consistency. Rather than explicitly delineating semantic boundaries, the model leverages class prototypes centralized semantic representations in the latent space as anchors. This strategy improves the robustness of dense predictions, particularly in the presence of noisy pseudo-labels. We also introduce a new publicly available benchmark: Multi-Object Segmentation in X-ray Angiography Videos (MOSXAV), which provides detailed, manually annotated segmentation ground truth for multiple anatomical structures in X-ray angiography videos. Extensive experiments on the EndoScapes2023 and MOSXAV datasets demonstrate that our method outperforms state-of-the-art medical image segmentation approaches under the semi-supervised learning setting. This work presents a robust and data-efficient diffusion model that offers enhanced flexibility and strong potential for a wide range of clinical applications.
Weighted Combination and Singular Spectrum Analysis Based Remote Photoplethysmography Pulse Extraction in Low-light Environments
Mar 04, 2025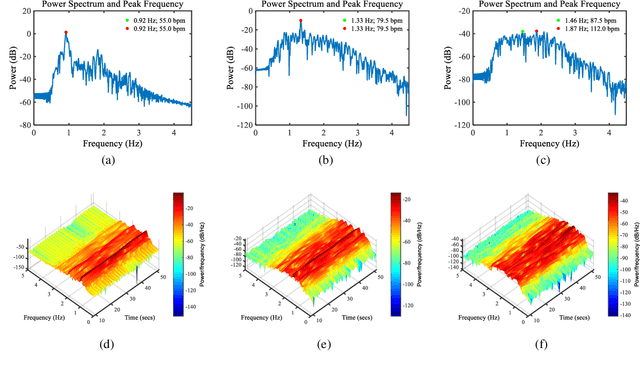
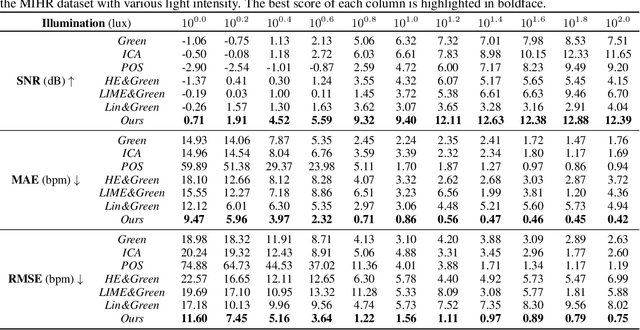
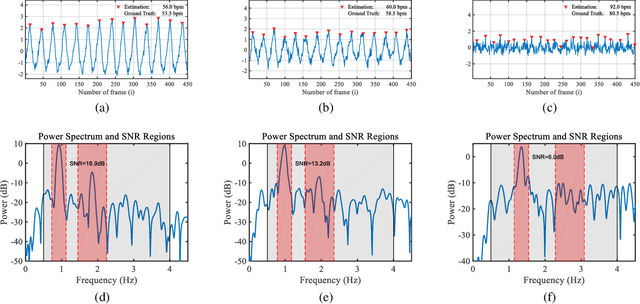
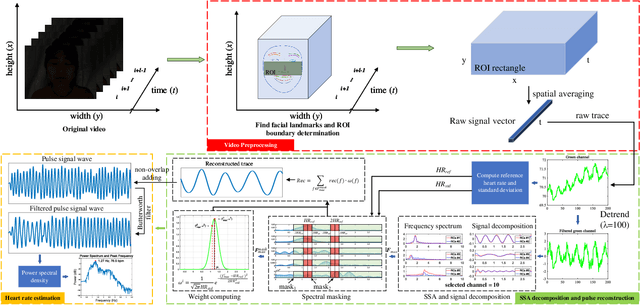
Camera-based vital signs monitoring in recent years has attracted more and more researchers and the results are promising. However, a few research works focus on heart rate extraction under extremely low illumination environments. In this paper, we propose a novel framework for remote heart rate estimation under low-light conditions. This method uses singular spectrum analysis (SSA) to decompose the filtered signal into several reconstructed components. A spectral masking algorithm is utilized to refine the preliminary candidate components on the basis of a reference heart rate. The contributive components are fused into the final pulse signal. To evaluate the performance of our framework in low-light conditions, the proposed approach is tested on a large-scale multi-illumination HR dataset (named MIHR). The test results verify that the proposed method has stronger robustness to low illumination than state-of-the-art methods, effectively improving the signal-to-noise ratio and heart rate estimation precision. We further perform experiments on the PUlse RatE detection (PURE) dataset which is recorded under normal light conditions to demonstrate the generalization of our method. The experiment results show that our method can stably detect pulse rate and achieve comparative results. The proposed method pioneers a new solution to the remote heart rate estimation in low-light conditions.
Catheter Detection and Segmentation in X-ray Images via Multi-task Learning
Mar 04, 2025Automated detection and segmentation of surgical devices, such as catheters or wires, in X-ray fluoroscopic images have the potential to enhance image guidance in minimally invasive heart surgeries. In this paper, we present a convolutional neural network model that integrates a resnet architecture with multiple prediction heads to achieve real-time, accurate localization of electrodes on catheters and catheter segmentation in an end-to-end deep learning framework. We also propose a multi-task learning strategy in which our model is trained to perform both accurate electrode detection and catheter segmentation simultaneously. A key challenge with this approach is achieving optimal performance for both tasks. To address this, we introduce a novel multi-level dynamic resource prioritization method. This method dynamically adjusts sample and task weights during training to effectively prioritize more challenging tasks, where task difficulty is inversely proportional to performance and evolves throughout the training process. Experiments on both public and private datasets have demonstrated that the accuracy of our method surpasses the existing state-of-the-art methods in both single segmentation task and in the detection and segmentation multi-task. Our approach achieves a good trade-off between accuracy and efficiency, making it well-suited for real-time surgical guidance applications.
Online Unsupervised Video Object Segmentation via Contrastive Motion Clustering
Jun 21, 2023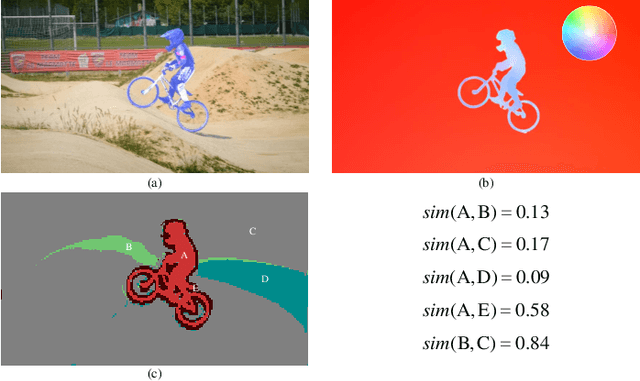
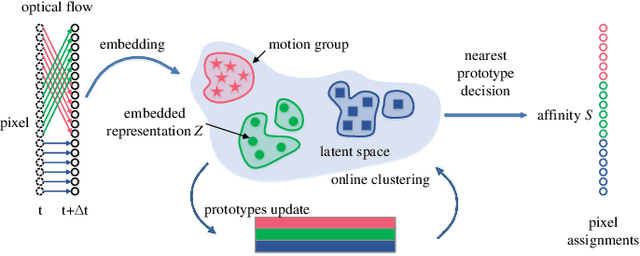
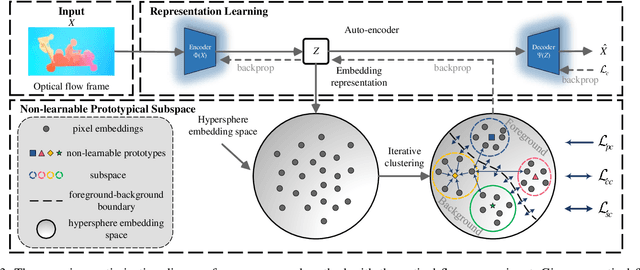
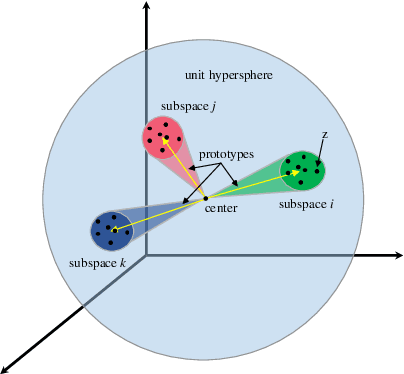
Online unsupervised video object segmentation (UVOS) uses the previous frames as its input to automatically separate the primary object(s) from a streaming video without using any further manual annotation. A major challenge is that the model has no access to the future and must rely solely on the history, i.e., the segmentation mask is predicted from the current frame as soon as it is captured. In this work, a novel contrastive motion clustering algorithm with an optical flow as its input is proposed for the online UVOS by exploiting the common fate principle that visual elements tend to be perceived as a group if they possess the same motion pattern. We build a simple and effective auto-encoder to iteratively summarize non-learnable prototypical bases for the motion pattern, while the bases in turn help learn the representation of the embedding network. Further, a contrastive learning strategy based on a boundary prior is developed to improve foreground and background feature discrimination in the representation learning stage. The proposed algorithm can be optimized on arbitrarily-scale data i.e., frame, clip, dataset) and performed in an online fashion. Experiments on $\textit{DAVIS}_{\textit{16}}$, $\textit{FBMS}$, and $\textit{SegTrackV2}$ datasets show that the accuracy of our method surpasses the previous state-of-the-art (SoTA) online UVOS method by a margin of 0.8%, 2.9%, and 1.1%, respectively. Furthermore, by using an online deep subspace clustering to tackle the motion grouping, our method is able to achieve higher accuracy at $3\times$ faster inference time compared to SoTA online UVOS method, and making a good trade-off between effectiveness and efficiency.
Image Enhancement for Remote Photoplethysmography in a Low-Light Environment
Mar 16, 2023


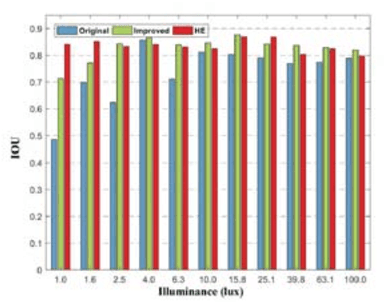
With the improvement of sensor technology and significant algorithmic advances, the accuracy of remote heart rate monitoring technology has been significantly improved. Despite of the significant algorithmic advances, the performance of rPPG algorithm can degrade in the long-term, high-intensity continuous work occurred in evenings or insufficient light environments. One of the main challenges is that the lost facial details and low contrast cause the failure of detection and tracking. Also, insufficient lighting in video capturing hurts the quality of physiological signal. In this paper, we collect a large-scale dataset that was designed for remote heart rate estimation recorded with various illumination variations to evaluate the performance of the rPPG algorithm (Green, ICA, and POS). We also propose a low-light enhancement solution (technical solution) for remote heart rate estimation under the low-light condition. Using collected dataset, we found 1) face detection algorithm cannot detect faces in video captured in low light conditions; 2) A decrease in the amplitude of the pulsatile signal will lead to the noise signal to be in the dominant position; and 3) the chrominance-based method suffers from the limitation in the assumption about skin-tone will not hold, and Green and ICA method receive less influence than POS in dark illuminance environment. The proposed solution for rPPG process is effective to detect and improve the signal-to-noise ratio and precision of the pulsatile signal.
Implicit Motion-Compensated Network for Unsupervised Video Object Segmentation
Apr 06, 2022



Unsupervised video object segmentation (UVOS) aims at automatically separating the primary foreground object(s) from the background in a video sequence. Existing UVOS methods either lack robustness when there are visually similar surroundings (appearance-based) or suffer from deterioration in the quality of their predictions because of dynamic background and inaccurate flow (flow-based). To overcome the limitations, we propose an implicit motion-compensated network (IMCNet) combining complementary cues ($\textit{i.e.}$, appearance and motion) with aligned motion information from the adjacent frames to the current frame at the feature level without estimating optical flows. The proposed IMCNet consists of an affinity computing module (ACM), an attention propagation module (APM), and a motion compensation module (MCM). The light-weight ACM extracts commonality between neighboring input frames based on appearance features. The APM then transmits global correlation in a top-down manner. Through coarse-to-fine iterative inspiring, the APM will refine object regions from multiple resolutions so as to efficiently avoid losing details. Finally, the MCM aligns motion information from temporally adjacent frames to the current frame which achieves implicit motion compensation at the feature level. We perform extensive experiments on $\textit{DAVIS}_{\textit{16}}$ and $\textit{YouTube-Objects}$. Our network achieves favorable performance while running at a faster speed compared to the state-of-the-art methods.
Using Deep Learning and Machine Learning to Detect Epileptic Seizure with Electroencephalography Data
Oct 06, 2019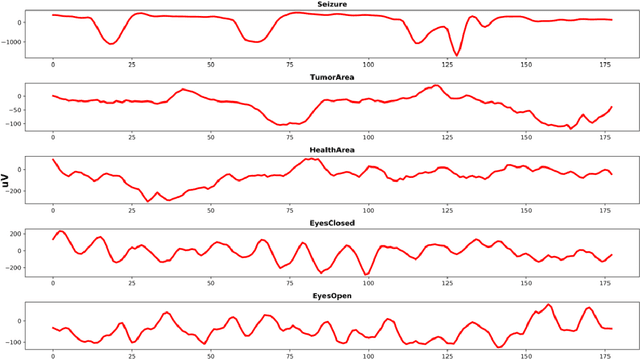
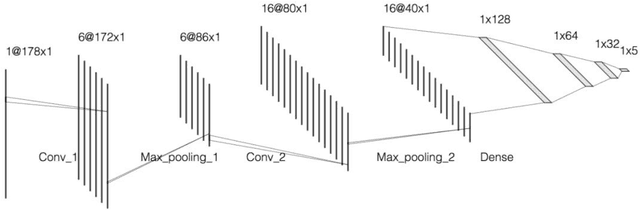
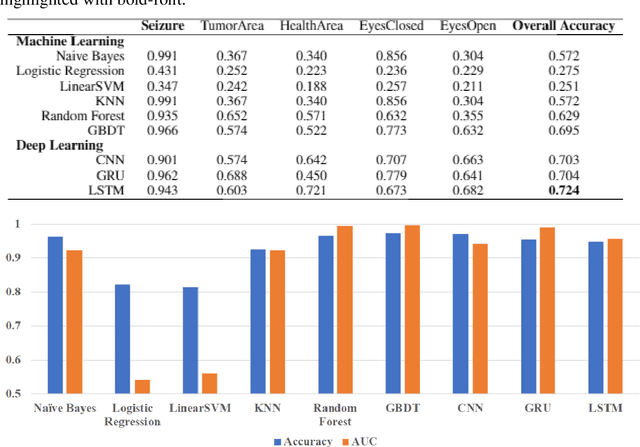
The prediction of epileptic seizure has always been extremely challenging in medical domain. However, as the development of computer technology, the application of machine learning introduced new ideas for seizure forecasting. Applying machine learning model onto the predication of epileptic seizure could help us obtain a better result and there have been plenty of scientists who have been doing such works so that there are sufficient medical data provided for researchers to do training of machine learning models.