 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Monocular Depth Estimation with Self-Reference Distillation and Disparity Offset Refinement
Paper and Code
Feb 20, 2023

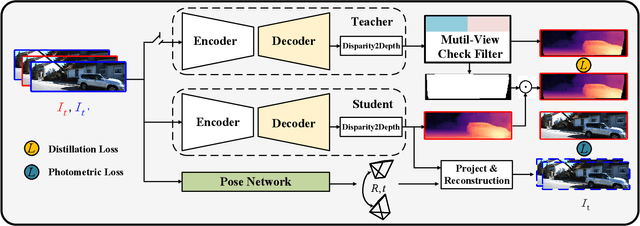
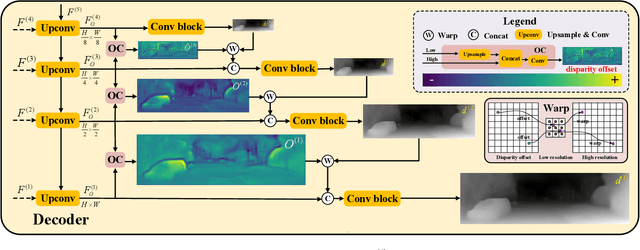
Monocular depth estimation plays a fundamental role in computer vision. Due to the costly acquisition of depth ground truth, self-supervised methods that leverage adjacent frames to establish a supervisory signal have emerged as the most promising paradigms. In this work, we propose two novel ideas to improve self-supervised monocular depth estimation: 1) self-reference distillation and 2) disparity offset refinement. Specifically, we use a parameter-optimized model as the teacher updated as the training epochs to provide additional supervision during the training process. The teacher model has the same structure as the student model, with weights inherited from the historical student model. In addition, a multiview check is introduced to filter out the outliers produced by the teacher model. Furthermore, we leverage the contextual consistency between high-scale and low-scale features to obtain multiscale disparity offsets, which are used to refine the disparity output incrementally by aligning disparity information at different scales. The experimental results on the KITTI and Make3D datasets show that our method outperforms previous state-of-the-art competitors.