 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagenWorld: Stress-Testing Image Generation Models with Explainable Human Evaluation on Open-ended Real-World Tasks
Mar 29, 2026Advances in diffusion, autoregressive, and hybrid models have enabled high-quality image synthesis for tasks such as text-to-image, editing, and reference-guided composition. Yet, existing benchmarks remain limited, either focus on isolated tasks, cover only narrow domains, or provide opaque scores without explaining failure modes. We introduce \textbf{ImagenWorld}, a benchmark of 3.6K condition sets spanning six core tasks (generation and editing, with single or multiple references) and six topical domains (artworks, photorealistic images, information graphics, textual graphics, computer graphics, and screenshots). The benchmark is supported by 20K fine-grained human annotations and an explainable evaluation schema that tags localized object-level and segment-level errors, complementing automated VLM-based metrics. Our large-scale evaluation of 14 models yields several insights: (1) models typically struggle more in editing tasks than in generation tasks, especially in local edits. (2) models excel in artistic and photorealistic settings but struggle with symbolic and text-heavy domains such as screenshots and information graphics. (3) closed-source systems lead overall, while targeted data curation (e.g., Qwen-Image) narrows the gap in text-heavy cases. (4) modern VLM-based metrics achieve Kendall accuracies up to 0.79, approximating human ranking, but fall short of fine-grained, explainable error attribution. ImagenWorld provides both a rigorous benchmark and a diagnostic tool to advance robust image generation.
The Curse of Conditions: Analyzing and Improving Optimal Transport for Conditional Flow-Based Generation
Mar 13, 2025



Minibatch optimal transport coupling straightens paths in unconditional flow matching. This leads to computationally less demanding inference as fewer integration steps and less complex numerical solvers can be employed when numerically solving an ordinary differential equation at test time. However, in the conditional setting, minibatch optimal transport falls short. This is because the default optimal transport mapping disregards conditions, resulting in a conditionally skewed prior distribution during training. In contrast, at test time, we have no access to the skewed prior, and instead sample from the full, unbiased prior distribution. This gap between training and testing leads to a subpar performance. To bridge this gap, we propose conditional optimal transport C^2OT that adds a conditional weighting term in the cost matrix when computing the optimal transport assignment. Experiments demonstrate that this simple fix works with both discrete and continuous conditions in 8gaussians-to-moons, CIFAR-10, ImageNet-32x32, and ImageNet-256x256. Our method performs better overall compared to the existing baselines across different function evaluation budgets. Code is available at https://hkchengrex.github.io/C2OT
Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
Dec 19, 2024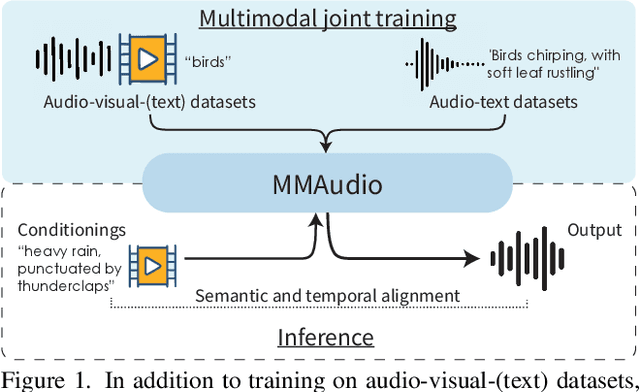
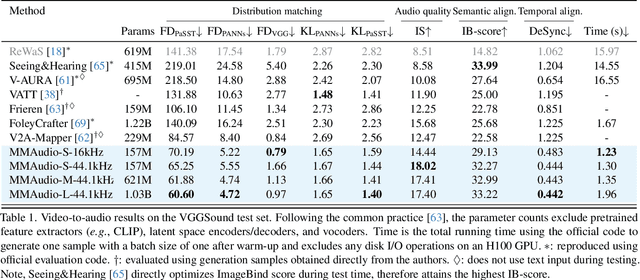
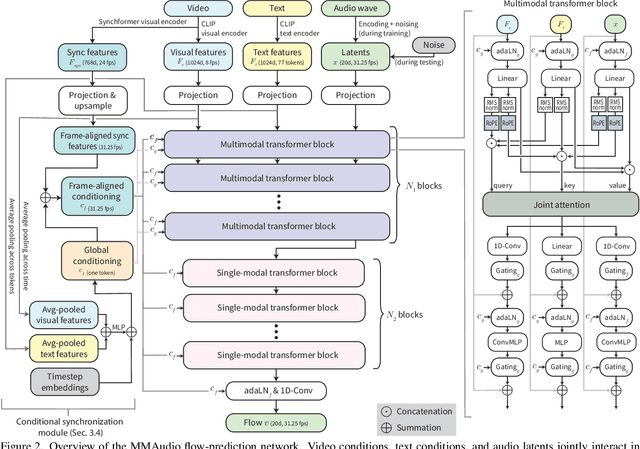
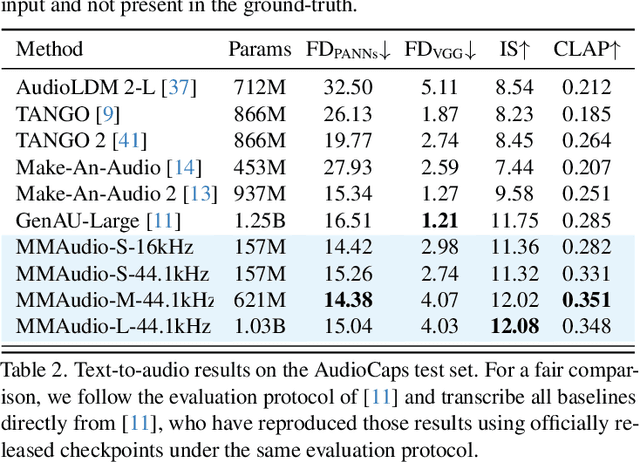
We propose to synthesize high-quality and synchronized audio, given video and optional text conditions, using a novel multimodal joint training framework MMAudio. In contrast to single-modality training conditioned on (limited) video data only, MMAudio is jointly trained with larger-scale, readily available text-audio data to learn to generate semantically aligned high-quality audio samples. Additionally, we improve audio-visual synchrony with a conditional synchronization module that aligns video conditions with audio latents at the frame level. Trained with a flow matching objective, MMAudio achieves new video-to-audio state-of-the-art among public models in terms of audio quality, semantic alignment, and audio-visual synchronization, while having a low inference time (1.23s to generate an 8s clip) and just 157M parameters. MMAudio also achieves surprisingly competitive performance in text-to-audio generation, showing that joint training does not hinder single-modality performance. Code and demo are available at: https://hkchengrex.github.io/MMAudio
Putting the Object Back into Video Object Segmentation
Oct 19, 2023We present Cutie, a video object segmentation (VOS) network with object-level memory reading, which puts the object representation from memory back into the video object segmentation result. Recent works on VOS employ bottom-up pixel-level memory reading which struggles due to matching noise, especially in the presence of distractors, resulting in lower performance in more challenging data. In contrast, Cutie performs top-down object-level memory reading by adapting a small set of object queries for restructuring and interacting with the bottom-up pixel features iteratively with a query-based object transformer (qt, hence Cutie). The object queries act as a high-level summary of the target object, while high-resolution feature maps are retained for accurate segmentation. Together with foreground-background masked attention, Cutie cleanly separates the semantics of the foreground object from the background. On the challenging MOSE dataset, Cutie improves by 8.7 J&F over XMem with a similar running time and improves by 4.2 J&F over DeAOT while running three times as fast. Code is available at: https://hkchengrex.github.io/Cutie
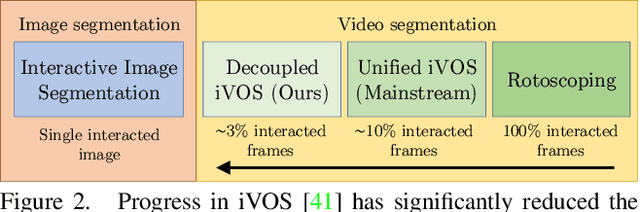
Tracking Anything with Decoupled Video Segmentation
Sep 07, 2023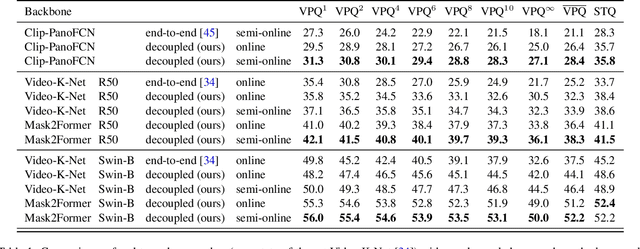

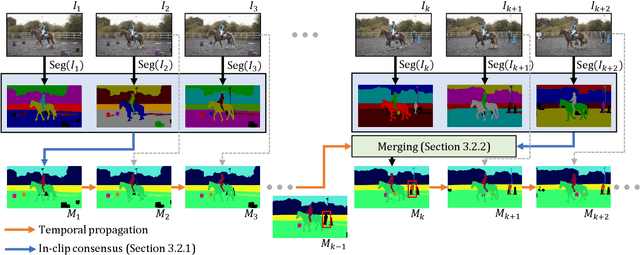
Training data for video segmentation are expensive to annotate. This impedes extensions of end-to-end algorithms to new video segmentation tasks, especially in large-vocabulary settings. To 'track anything' without training on video data for every individual task, we develop a decoupled video segmentation approach (DEVA), composed of task-specific image-level segmentation and class/task-agnostic bi-directional temporal propagation. Due to this design, we only need an image-level model for the target task (which is cheaper to train) and a universal temporal propagation model which is trained once and generalizes across tasks. To effectively combine these two modules, we use bi-directional propagation for (semi-)online fusion of segmentation hypotheses from different frames to generate a coherent segmentation. We show that this decoupled formulation compares favorably to end-to-end approaches in several data-scarce tasks including large-vocabulary video panoptic segmentation, open-world video segmentation, referring video segmentation, and unsupervised video object segmentation. Code is available at: https://hkchengrex.github.io/Tracking-Anything-with-DEVA
XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
Jul 18, 2022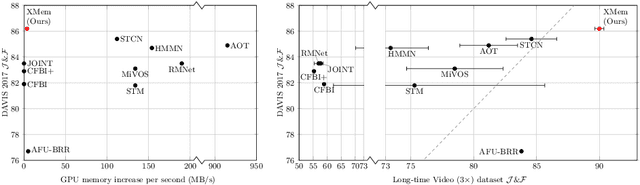

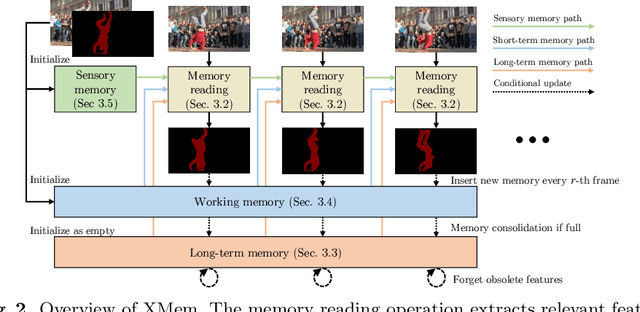
We present XMem, a video object segmentation architecture for long videos with unified feature memory stores inspired by the Atkinson-Shiffrin memory model. Prior work on video object segmentation typically only uses one type of feature memory. For videos longer than a minute, a single feature memory model tightly links memory consumption and accuracy. In contrast, following the Atkinson-Shiffrin model, we develop an architecture that incorporates multiple independent yet deeply-connected feature memory stores: a rapidly updated sensory memory, a high-resolution working memory, and a compact thus sustained long-term memory. Crucially, we develop a memory potentiation algorithm that routinely consolidates actively used working memory elements into the long-term memory, which avoids memory explosion and minimizes performance decay for long-term prediction. Combined with a new memory reading mechanism, XMem greatly exceeds state-of-the-art performance on long-video datasets while being on par with state-of-the-art methods (that do not work on long videos) on short-video datasets. Code is available at https://hkchengrex.github.io/XMem
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
Jun 09, 2021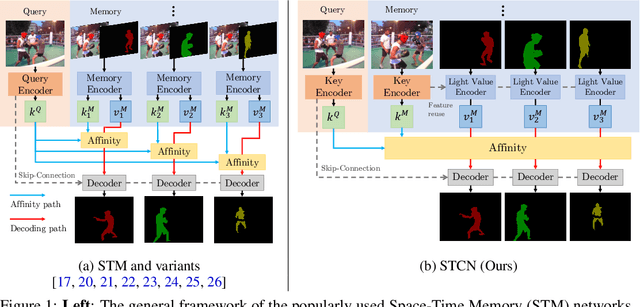

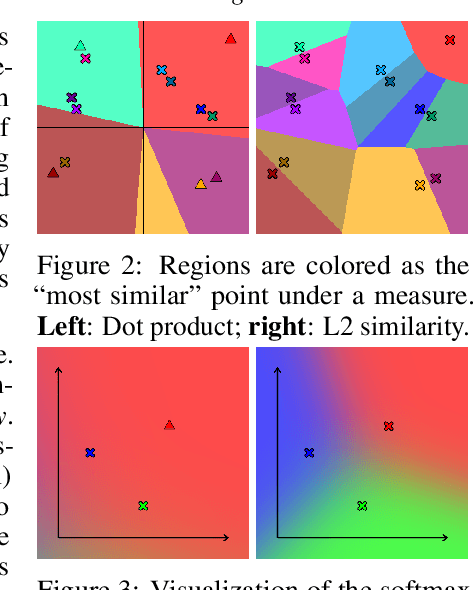
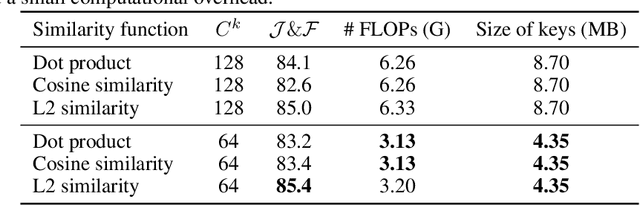
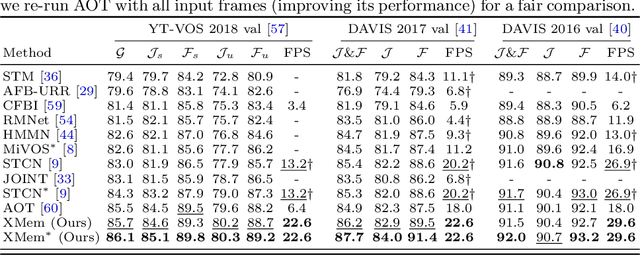
This paper presents a simple yet effective approach to modeling space-time correspondences in the context of video object segmentation. Unlike most existing approaches, we establish correspondences directly between frames without re-encoding the mask features for every object, leading to a highly efficient and robust framework. With the correspondences, every node in the current query frame is inferred by aggregating features from the past in an associative fashion. We cast the aggregation process as a voting problem and find that the existing inner-product affinity leads to poor use of memory with a small (fixed) subset of memory nodes dominating the votes, regardless of the query. In light of this phenomenon, we propose using the negative squared Euclidean distance instead to compute the affinities. We validated that every memory node now has a chance to contribute, and experimentally showed that such diversified voting is beneficial to both memory efficiency and inference accuracy. The synergy of correspondence networks and diversified voting works exceedingly well, achieves new state-of-the-art results on both DAVIS and YouTubeVOS datasets while running significantly faster at 20+ FPS for multiple objects without bells and whistles.
Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
Mar 21, 2021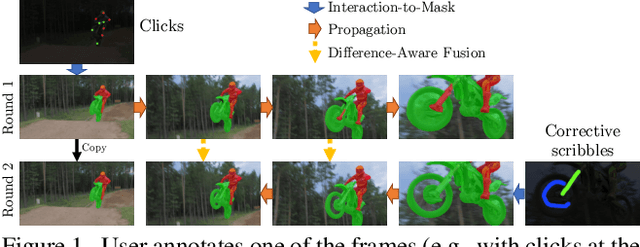
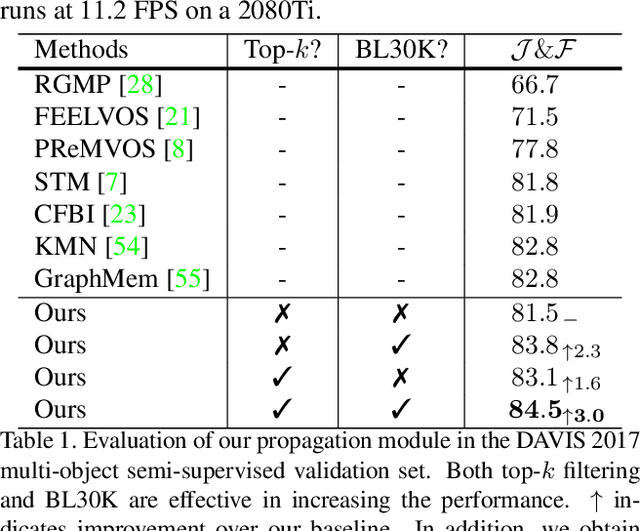
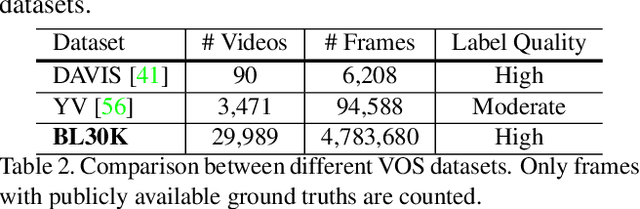
We present Modular interactive VOS (MiVOS) framework which decouples interaction-to-mask and mask propagation, allowing for higher generalizability and better performance. Trained separately, the interaction module converts user interactions to an object mask, which is then temporally propagated by our propagation module using a novel top-$k$ filtering strategy in reading the space-time memory. To effectively take the user's intent into account, a novel difference-aware module is proposed to learn how to properly fuse the masks before and after each interaction, which are aligned with the target frames by employing the space-time memory. We evaluate our method both qualitatively and quantitatively with different forms of user interactions (e.g., scribbles, clicks) on DAVIS to show that our method outperforms current state-of-the-art algorithms while requiring fewer frame interactions, with the additional advantage in generalizing to different types of user interactions. We contribute a large-scale synthetic VOS dataset with pixel-accurate segmentation of 4.8M frames to accompany our source codes to facilitate future research.
CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement
May 06, 2020
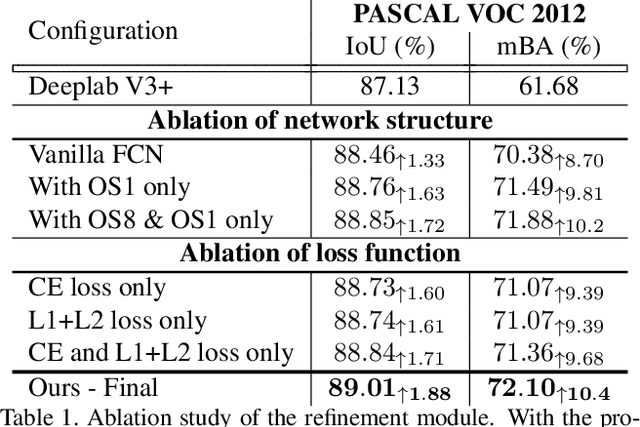
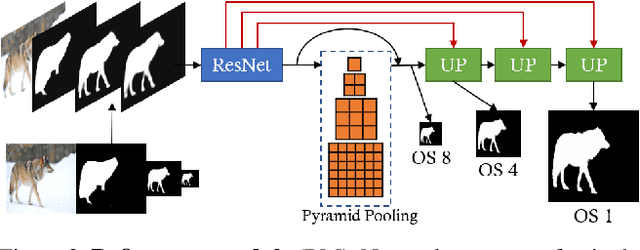
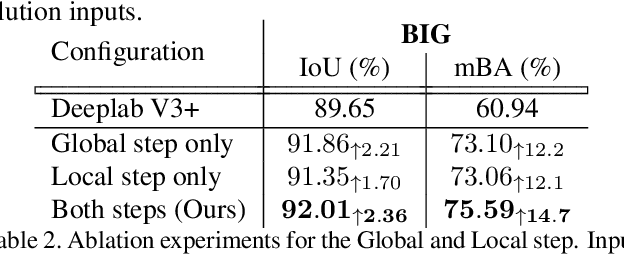
State-of-the-art semantic segmentation methods were almost exclusively trained on images within a fixed resolution range. These segmentations are inaccurate for very high-resolution images since using bicubic upsampling of low-resolution segmentation does not adequately capture high-resolution details along object boundaries. In this paper, we propose a novel approach to address the high-resolution segmentation problem without using any high-resolution training data. The key insight is our CascadePSP network which refines and corrects local boundaries whenever possible. Although our network is trained with low-resolution segmentation data, our method is applicable to any resolution even for very high-resolution images larger than 4K. We present quantitative and qualitative studies on different datasets to show that CascadePSP can reveal pixel-accurate segmentation boundaries using our novel refinement module without any finetuning. Thus, our method can be regarded as class-agnostic. Finally, we demonstrate the application of our model to scene parsing in multi-class segmentation.