 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECORAIT -- DECentralized Opt-in/out Registry for AI Training
Sep 25, 2023
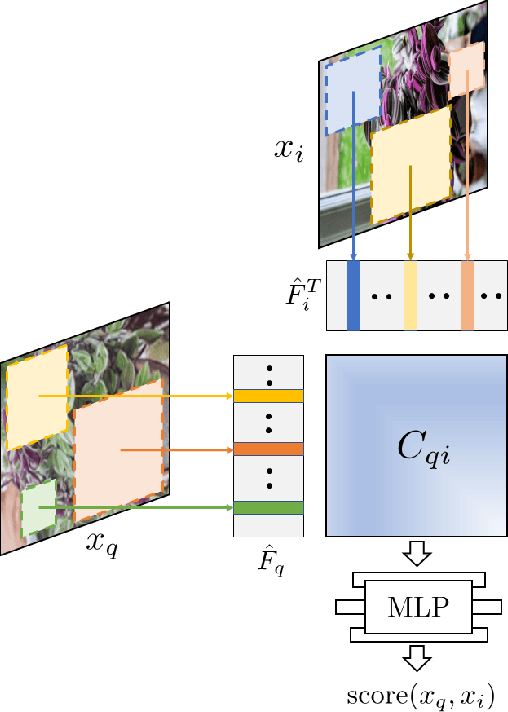
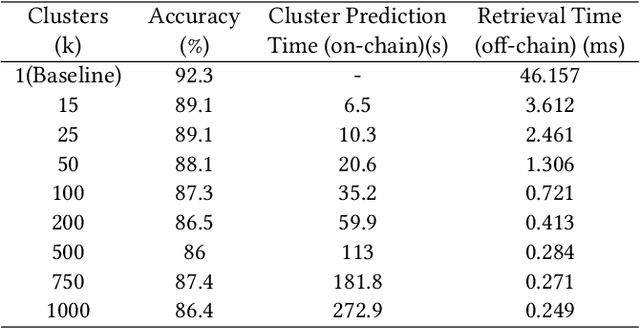
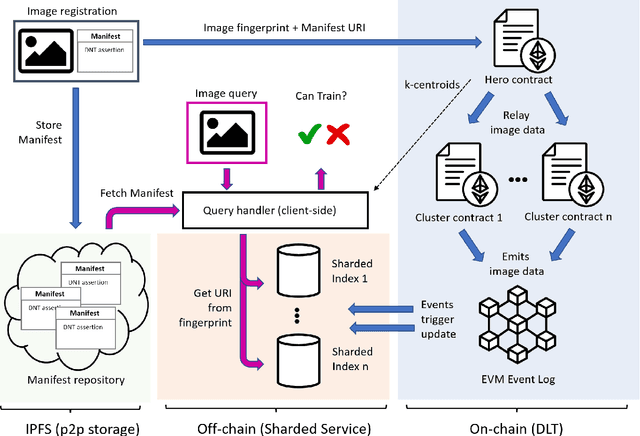
We present DECORAIT; a decentralized registry through which content creators may assert their right to opt in or out of AI training as well as receive reward for their contributions. Generative AI (GenAI) enables images to be synthesized using AI models trained on vast amounts of data scraped from public sources. Model and content creators who may wish to share their work openly without sanctioning its use for training are thus presented with a data governance challenge. Further, establishing the provenance of GenAI training data is important to creatives to ensure fair recognition and reward for their such use. We report a prototype of DECORAIT, which explores hierarchical clustering and a combination of on/off-chain storage to create a scalable decentralized registry to trace the provenance of GenAI training data in order to determine training consent and reward creatives who contribute that data. DECORAIT combines distributed ledger technology (DLT) with visual fingerprinting, leveraging the emerging C2PA (Coalition for Content Provenance and Authenticity) standard to create a secure, open registry through which creatives may express consent and data ownership for GenAI.
ALADIN-NST: Self-supervised disentangled representation learning of artistic style through Neural Style Transfer
Apr 12, 2023


Representation learning aims to discover individual salient features of a domain in a compact and descriptive form that strongly identifies the unique characteristics of a given sample respective to its domain. Existing works in visual style representation literature have tried to disentangle style from content during training explicitly. A complete separation between these has yet to be fully achieved. Our paper aims to learn a representation of visual artistic style more strongly disentangled from the semantic content depicted in an image. We use Neural Style Transfer (NST) to measure and drive the learning signal and achieve state-of-the-art representation learning on explicitly disentangled metrics. We show that strongly addressing the disentanglement of style and content leads to large gains in style-specific metrics, encoding far less semantic information and achieving state-of-the-art accuracy in downstream multimodal applications.