 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Design and Scaling of Hybrid Architectures
Mar 26, 2024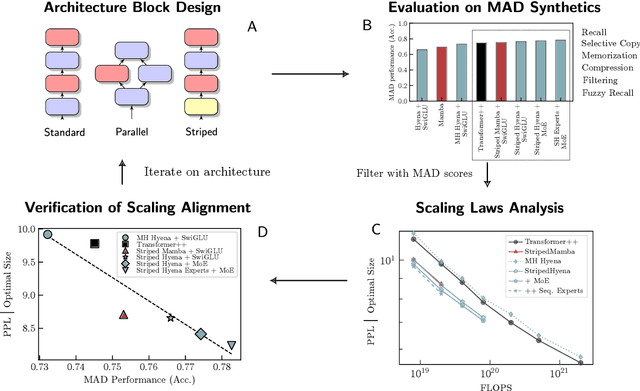
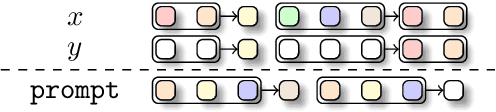
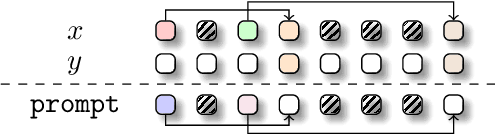

The development of deep learning architectures is a resource-demanding process, due to a vast design space, long prototyping times, and high compute costs associated with at-scale model training and evaluation. We set out to simplify this process by grounding it in an end-to-end mechanistic architecture design (MAD) pipeline, encompassing small-scale capability unit tests predictive of scaling laws. Through a suite of synthetic token manipulation tasks such as compression and recall, designed to probe capabilities, we identify and test new hybrid architectures constructed from a variety of computational primitives. We experimentally validate the resulting architectures via an extensive compute-optimal and a new state-optimal scaling law analysis, training over 500 language models between 70M to 7B parameters. Surprisingly, we find MAD synthetics to correlate with compute-optimal perplexity, enabling accurate evaluation of new architectures via isolated proxy tasks. The new architectures found via MAD, based on simple ideas such as hybridization and sparsity, outperform state-of-the-art Transformer, convolutional, and recurrent architectures (Transformer++, Hyena, Mamba) in scaling, both at compute-optimal budgets and in overtrained regimes. Overall, these results provide evidence that performance on curated synthetic tasks can be predictive of scaling laws, and that an optimal architecture should leverage specialized layers via a hybrid topology.
Generative artificial intelligence for de novo protein design
Oct 15, 2023Engineering new molecules with desirable functions and properties has the potential to extend our ability to engineer proteins beyond what nature has so far evolved. Advances in the so-called "de novo" design problem have recently been brought forward by developments in artificial intelligence. Generative architectures, such as language models and diffusion processes, seem adept at generating novel, yet realistic proteins that display desirable properties and perform specified functions. State-of-the-art design protocols now achieve experimental success rates nearing 20%, thus widening the access to de novo designed proteins. Despite extensive progress, there are clear field-wide challenges, for example in determining the best in silico metrics to prioritise designs for experimental testing, and in designing proteins that can undergo large conformational changes or be regulated by post-translational modifications and other cellular processes. With an increase in the number of models being developed, this review provides a framework to understand how these tools fit into the overall process of de novo protein design. Throughout, we highlight the power of incorporating biochemical knowledge to improve performance and interpretability.