 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing interpretation methods in mental state decoding analyses with deep learning models
Paper and Code
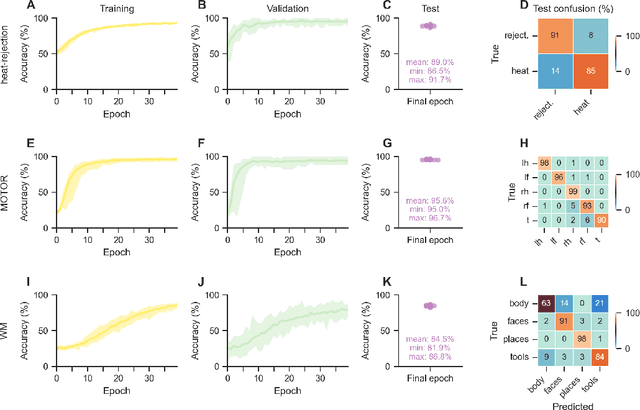
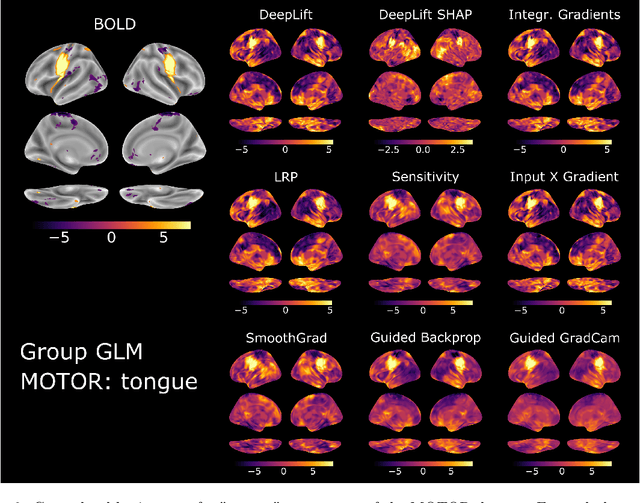
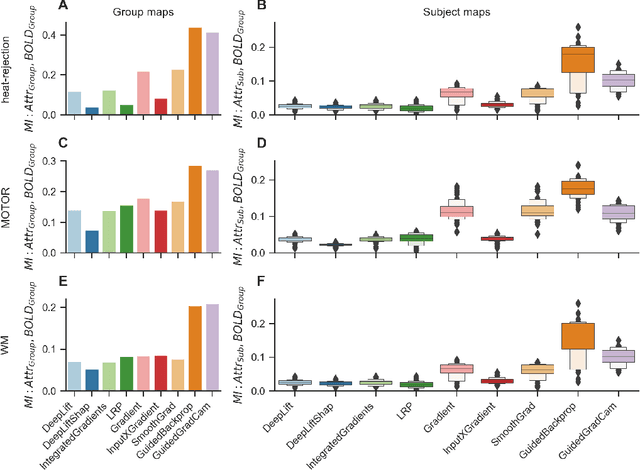
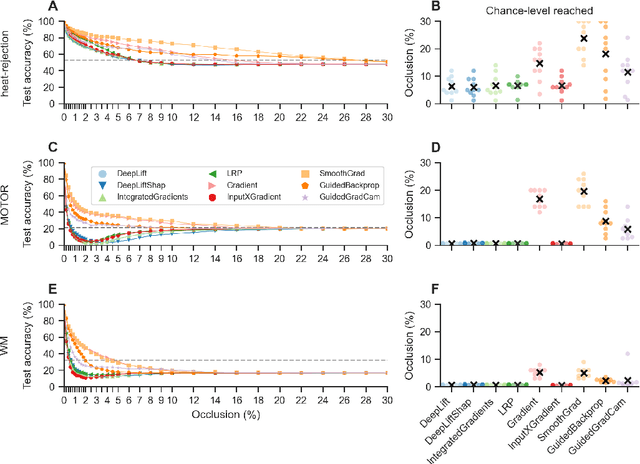
Deep learning (DL) methods find increasing application in mental state decoding, where researchers seek to understand the mapping between mental states (such as accepting or rejecting a gamble) and brain activity, by identifying those brain regions (and networks) whose activity allows to accurately identify (i.e., decode) these states. Once DL models have been trained to accurately decode a set of mental states, neuroimaging researchers often make use of interpretation methods from explainable artificial intelligence research to understand their learned mappings between mental states and brain activity. Here, we compare the explanations of prominent interpretation methods for the mental state decoding decisions of DL models trained on three functional Magnetic Resonance Imaging (fMRI) datasets. We find that interpretation methods that capture the model's decision process well, by producing faithful explanations, generally produce explanations that are less in line with the results of standard analyses of the fMRI data, when compared to the explanations of interpretation methods with less explanation faithfulness. Specifically, we find that interpretation methods that focus on how sensitively a model's decoding decision changes with the values of the input produce explanations that better match with the results of a standard general linear model analysis of the fMRI data, while interpretation methods that focus on identifying the specific contribution of an input feature's value to the decoding decision produce overall more faithful explanations that align less well with the results of standard analyses of the fMRI data.