 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Degeneracy in Self-supervised Learning of Elevation Angle Estimation for 2D Forward-Looking Sonar
Aug 01, 2023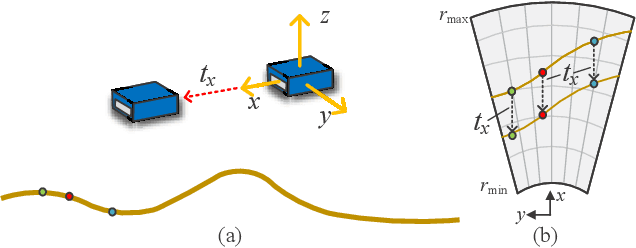
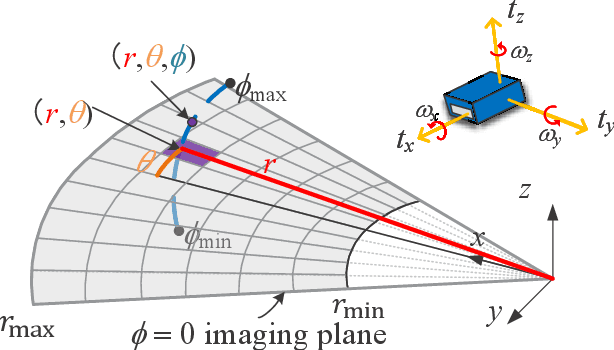
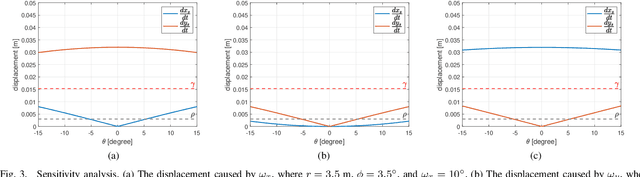
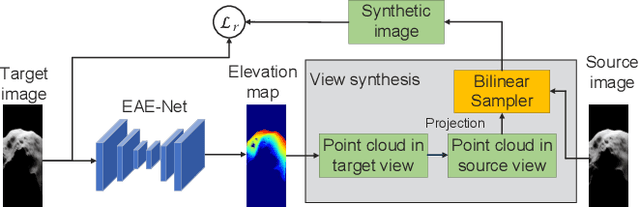
2D forward-looking sonar is a crucial sensor for underwater robotic perception. A well-known problem in this field is estimating missing information in the elevation direction during sonar imaging. There are demands to estimate 3D information per image for 3D mapping and robot navigation during fly-through missions. Recent learning-based methods have demonstrated their strengths, but there are still drawbacks. Supervised learning methods have achieved high-quality results but may require further efforts to acquire 3D ground-truth labels. The existing self-supervised method requires pretraining using synthetic images with 3D supervision. This study aims to realize stable self-supervised learning of elevation angle estimation without pretraining using synthetic images. Failures during self-supervised learning may be caused by motion degeneracy problems. We first analyze the motion field of 2D forward-looking sonar, which is related to the main supervision signal. We utilize a modern learning framework and prove that if the training dataset is built with effective motions, the network can be trained in a self-supervised manner without the knowledge of synthetic data. Both simulation and real experiments validate the proposed method.
2D Forward Looking Sonar Simulation with Ground Echo Modeling
Apr 17, 2023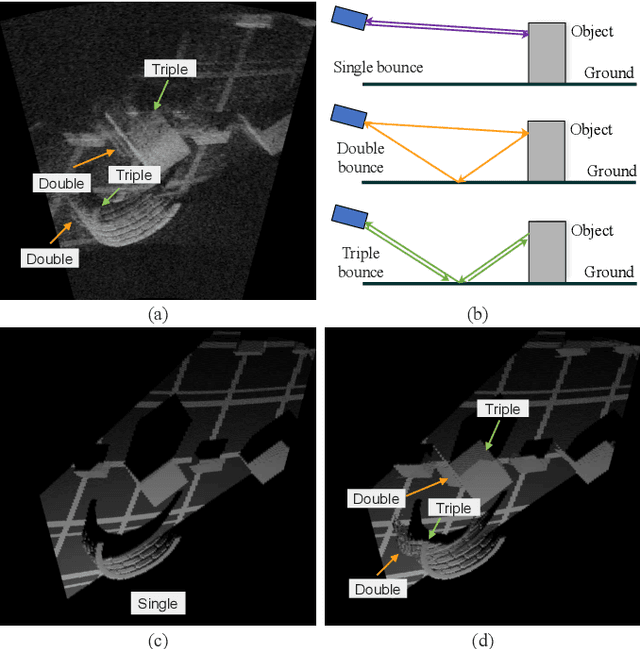

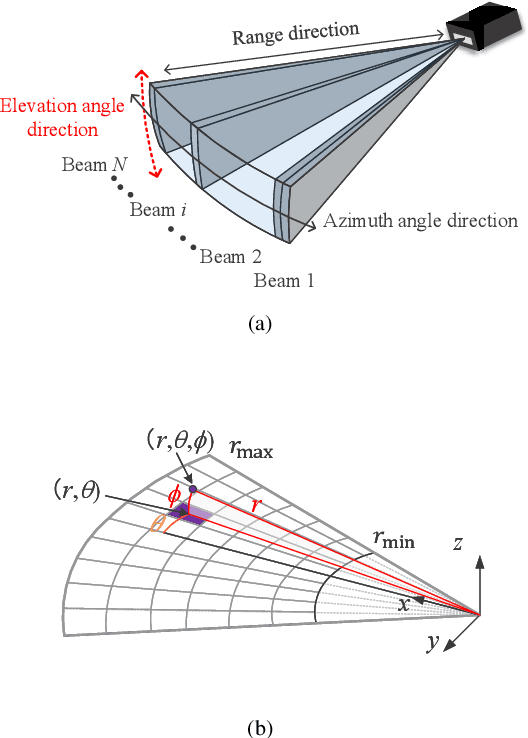
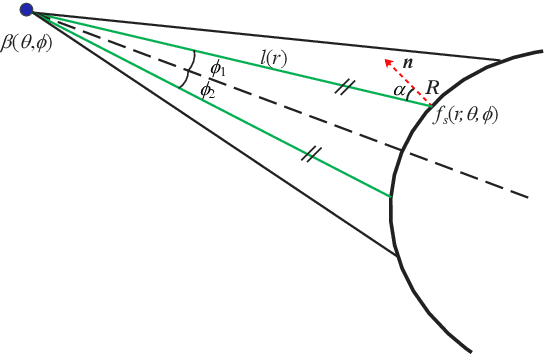
Imaging sonar produces clear images in underwater environments, independent of water turbidity and lighting conditions. The next generation 2D forward looking sonars are compact in size and able to generate high-resolution images which facilitate underwater robotics research. Considering the difficulties and expenses of implementing experiments in underwater environments, tremendous work has been focused on sonar image simulation. However, sonar artifacts like multi-path reflection were not sufficiently discussed, which cannot be ignored in water tank environments. In this paper, we focus on the influence of echoes from the flat ground. We propose a method to simulate the ground echo effect physically in acoustic images. We model the multi-bounce situations using the single-bounce framework for computation efficiency. We compare the real image captured in the water tank with the synthetic images to validate the proposed methods.
Learning Pseudo Front Depth for 2D Forward-Looking Sonar-based Multi-view Stereo
Jul 30, 2022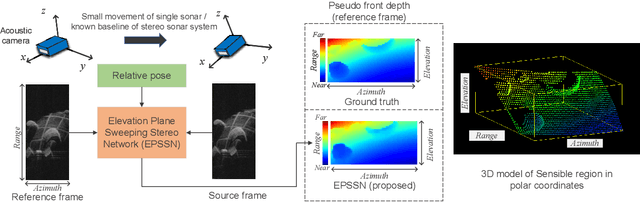
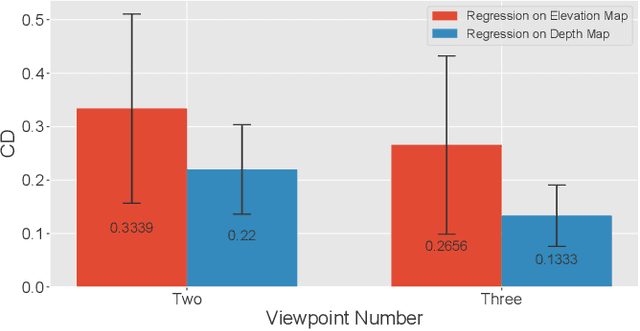
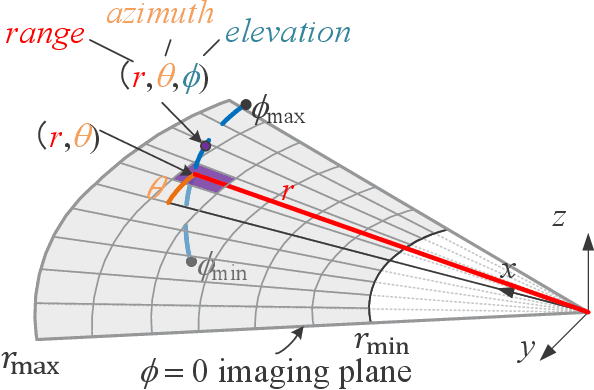
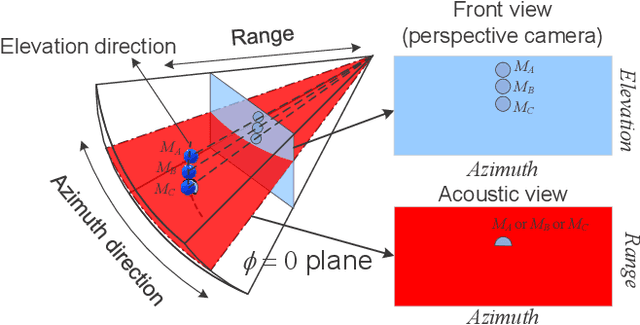
Retrieving the missing dimension information in acoustic images from 2D forward-looking sonar is a well-known problem in the field of underwater robotics. There are works attempting to retrieve 3D information from a single image which allows the robot to generate 3D maps with fly-through motion. However, owing to the unique image formulation principle, estimating 3D information from a single image faces severe ambiguity problems. Classical methods of multi-view stereo can avoid the ambiguity problems, but may require a large number of viewpoints to generate an accurate model. In this work, we propose a novel learning-based multi-view stereo method to estimate 3D information. To better utilize the information from multiple frames, an elevation plane sweeping method is proposed to generate the depth-azimuth-elevation cost volume. The volume after regularization can be considered as a probabilistic volumetric representation of the target. Instead of performing regression on the elevation angles, we use pseudo front depth from the cost volume to represent the 3D information which can avoid the 2D-3D problem in acoustic imaging. High-accuracy results can be generated with only two or three images. Synthetic datasets were generated to simulate various underwater targets. We also built the first real dataset with accurate ground truth in a large scale water tank. Experimental results demonstrate the superiority of our method, compared to other state-of-the-art methods.
Three-dimensional Human Tracking of a Mobile Robot by Fusion of Tracking Results of Two Cameras
Jul 03, 2020
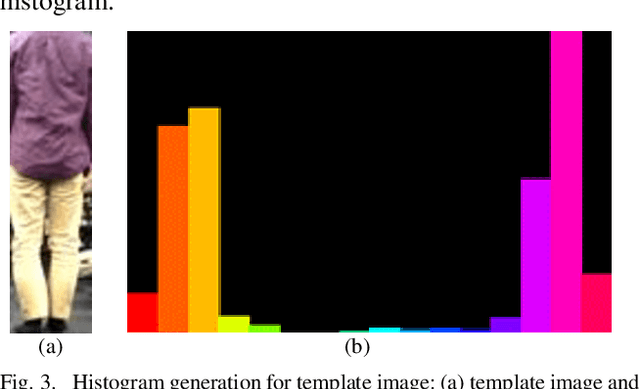


This paper proposes a process that uses two cameras to obtain three-dimensional (3D) information of a target object for human tracking. Results of human detection and tracking from two cameras are integrated to obtain the 3D information. OpenPose is used for human detection. In the case of a general processing a stereo camera, a range image of the entire scene is acquired as precisely as possible, and then the range image is processed. However, there are problems such as incorrect matching and computational cost for the calibration process. A new stereo vision framework is proposed to cope with the problems. The effectiveness of the proposed framework and the method is verified through target-tracking experiments.
SLAM using ICP and graph optimization considering physical properties of environment
Jul 01, 2020

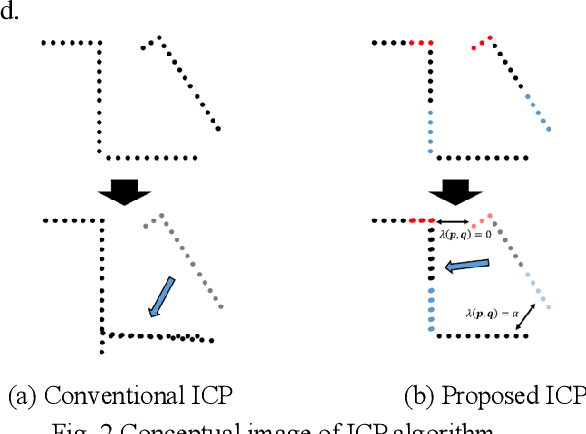

This paper describes a novel SLAM (simultaneous localization and mapping) scheme based on scan matching in an environment including various physical properties.
Expandable YOLO: 3D Object Detection from RGB-D Images
Jun 26, 2020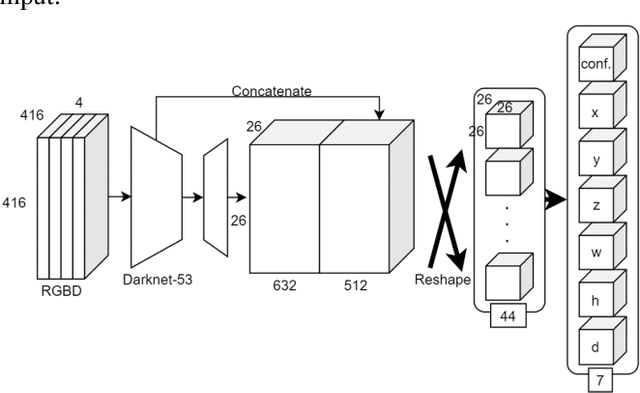


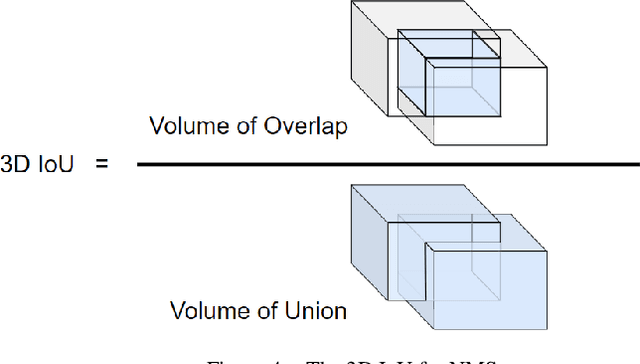
This paper aims at constructing a light-weight object detector that inputs a depth and a color image from a stereo camera. Specifically, by extending the network architecture of YOLOv3 to 3D in the middle, it is possible to output in the depth direction. In addition, Intersection over Uninon (IoU) in 3D space is introduced to confirm the accuracy of region extraction results. In the field of deep learning, object detectors that use distance information as input are actively studied for utilizing automated driving. However, the conventional detector has a large network structure, and the real-time property is impaired. The effectiveness of the detector constructed as described above is verified using datasets. As a result of this experiment, the proposed model is able to output 3D bounding boxes and detect people whose part of the body is hidden. Further, the processing speed of the model is 44.35 fps.
Anomaly Detection Based on Deep Learning Using Video for Prevention of Industrial Accidents
May 28, 2020
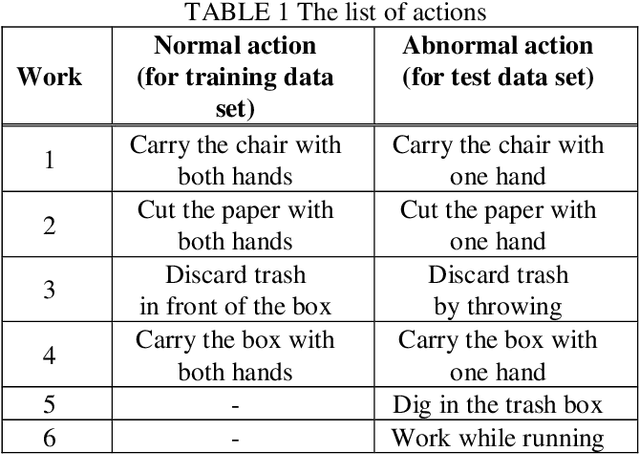
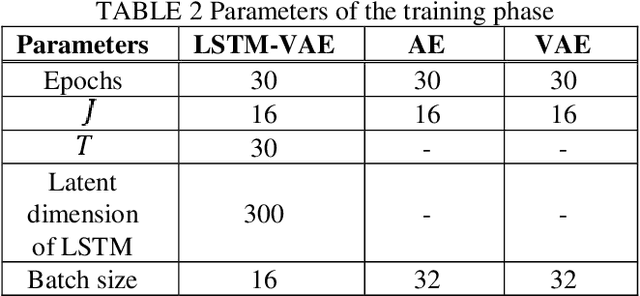
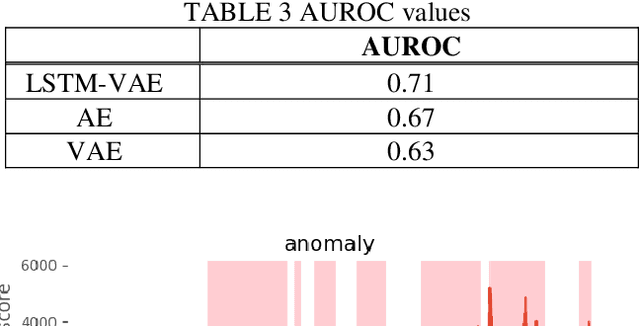
This paper proposes an anomaly detection method for the prevention of industrial accidents using machine learning technology.