 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn analysis of observation length requirements for machine understanding of human behaviors in spoken language
Paper and Code
Nov 29, 2019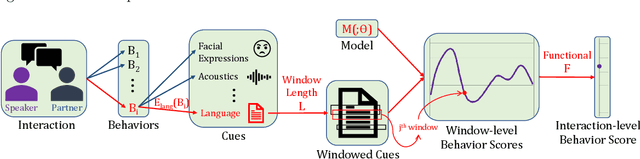


Machine learning-based human behavior modeling, often at the level of characterizing an entire clinical encounter such as a therapy session, has been shown to be useful across a range of domains in psychological research and practice from relationship and family studies to cancer care. Existing approaches typically first quantify the target behavior construct based on cues in an observation window, such as a fixed number of words, and then aggregate it over all the windows in that session. During this process, a sufficiently long window is employed so that adequate information is gathered to accurately estimate the construct. The link between behavior modeling and the observation length, however, has not been well studied, especially for spoken language. In this paper, we analyze the effect of observation window length on the quality of behavior quantification and present a framework for determining appropriate windows for a wide range of behaviors. Our analysis method employs two levels of evaluations: (a) extrinsic similarity between machine predictions and human expert annotations, and (b) intrinsic consistency between intra-machine and intra-human behavior relations. We apply our analysis on a dataset of real-life married couple interactions that are annotated for a large and diverse set of behavior codes and test the robustness of our findings to different machine learning models. We find that negative constructs such as blame can be accurately identified from short expressions while those pertaining to positive affect such as satisfaction tend to require slightly longer observation windows. Behaviors that describe more complex personality traits such as negotiation and avoidance are found to require very long observations and are difficult to quantify from language alone. Our findings are in agreement with similar work on acoustic cues, thin slices and human emotion perception.