 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1SPU: 1-step Speech Processing Unit
Nov 10, 2023Recent studies have made some progress in refining end-to-end (E2E) speech recognition encoders by applying Connectionist Temporal Classification (CTC) loss to enhance named entity recognition within transcriptions. However, these methods have been constrained by their exclusive use of the ASCII character set, allowing only a limited array of semantic labels. We propose 1SPU, a 1-step Speech Processing Unit which can recognize speech events (e.g: speaker change) or an NL event (Intent, Emotion) while also transcribing vocal content. It extends the E2E automatic speech recognition (ASR) system's vocabulary by adding a set of unused placeholder symbols, conceptually akin to the <pad> tokens used in sequence modeling. These placeholders are then assigned to represent semantic events (in form of tags) and are integrated into the transcription process as distinct tokens. We demonstrate notable improvements on the SLUE benchmark and yields results that are on par with those for the SLURP dataset. Additionally, we provide a visual analysis of the system's proficiency in accurately pinpointing meaningful tokens over time, illustrating the enhancement in transcription quality through the utilization of supplementary semantic tags.
Automatic Data Expansion for Customer-care Spoken Language Understanding
Sep 27, 2018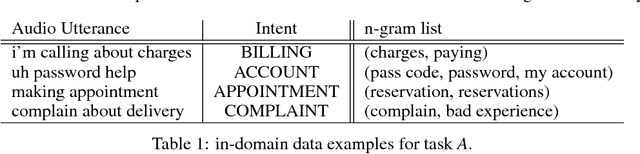
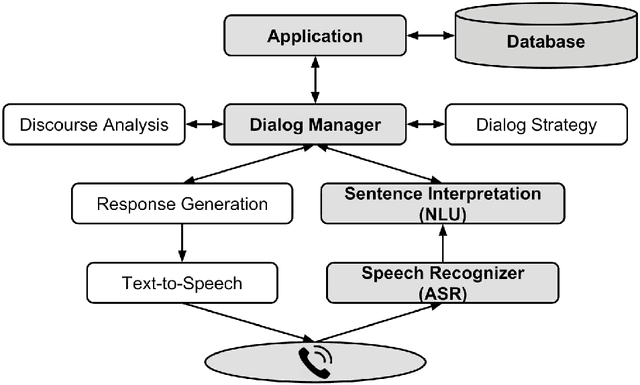
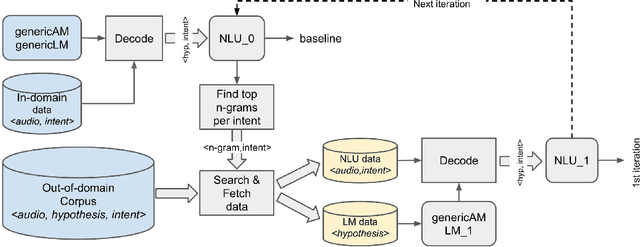
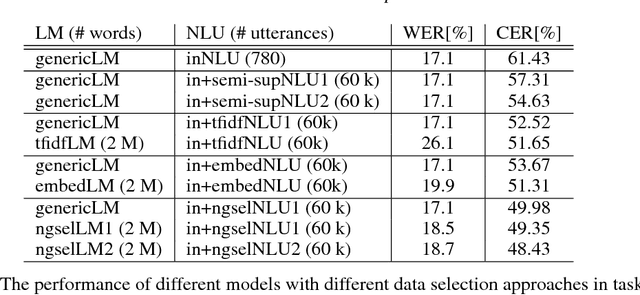
Spoken language understanding (SLU) systems are widely used in handling of customer-care calls.A traditional SLU system consists of an acoustic model (AM) and a language model (LM) that areused to decode the utterance and a natural language understanding (NLU) model that predicts theintent. While AM can be shared across different domains, LM and NLU models need to be trainedspecifically for every new task. However, preparing enough data to train these models is prohibitivelyexpensive. In this paper, we introduce an efficient method to expand the limited in-domain data. Theprocess starts with training a preliminary NLU model based on logistic regression on the in-domaindata. Since the features are based onn= 1,2-grams, we can detect the most informative n-gramsfor each intent class. Using these n-grams, we find the samples in the out-of-domain corpus that1) contain the desired n-gram and/or 2) have similar intent label. The ones which meet the firstconstraint are used to train a new LM model and the ones that meet both constraints are used to train anew NLU model. Our results on two divergent experimental setups show that the proposed approachreduces by 30% the absolute classification error rate (CER) comparing to the preliminary modelsand it significantly outperforms the traditional data expansion algorithms such as the ones based onsemi-supervised learning, TF-IDF and embedding vectors.