 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNews Reporter: A Multi-lingual LLM Framework for Broadcast T.V News
Oct 10, 2024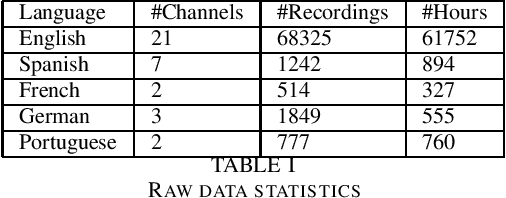
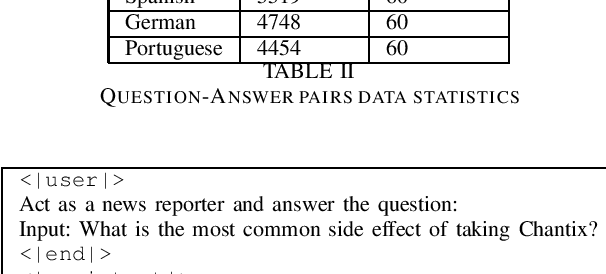


Large Language Models (LLMs) have fast become an essential tools to many conversational chatbots due to their ability to provide coherent answers for varied queries. Datasets used to train these LLMs are often a mix of generic and synthetic samples, thus lacking the verification needed to provide correct and verifiable answers for T.V. News. We collect and share a large collection of QA pairs extracted from transcripts of news recordings from various news-channels across the United States. Resultant QA pairs are then used to fine-tune an off-the-shelf LLM model. Our model surpasses base models of similar size on several open LLM benchmarks. We further integrate and propose a RAG method to improve contextualization of our answers and also point it to a verifiable news recording.