 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Forgetting Any Data at Any Time: A Theoretically Certified Unlearning Framework for Vertical Federated Learning
Feb 24, 2025



Privacy concerns in machine learning are heightened by regulations such as the GDPR, which enforces the "right to be forgotten" (RTBF), driving the emergence of machine unlearning as a critical research field. Vertical Federated Learning (VFL) enables collaborative model training by aggregating a sample's features across distributed parties while preserving data privacy at each source. This paradigm has seen widespread adoption in healthcare, finance, and other privacy-sensitive domains. However, existing VFL systems lack robust mechanisms to comply with RTBF requirements, as unlearning methodologies for VFL remain underexplored. In this work, we introduce the first VFL framework with theoretically guaranteed unlearning capabilities, enabling the removal of any data at any time. Unlike prior approaches -- which impose restrictive assumptions on model architectures or data types for removal -- our solution is model- and data-agnostic, offering universal compatibility. Moreover, our framework supports asynchronous unlearning, eliminating the need for all parties to be simultaneously online during the forgetting process. These advancements address critical gaps in current VFL systems, ensuring compliance with RTBF while maintaining operational flexibility.We make all our implementations publicly available at https://github.com/wangln19/vertical-federated-unlearning.
Knowledge-inspired Subdomain Adaptation for Cross-Domain Knowledge Transfer
Aug 17, 2023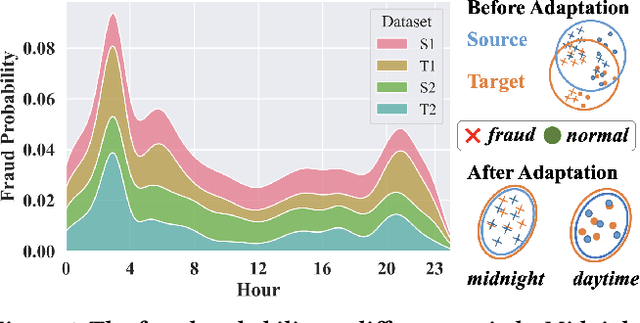
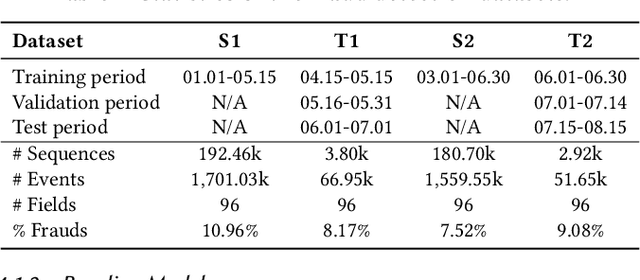
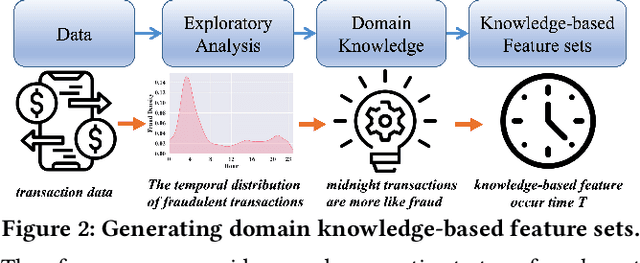
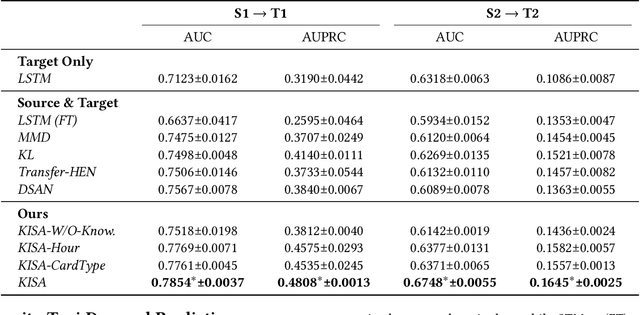
Most state-of-the-art deep domain adaptation techniques align source and target samples in a global fashion. That is, after alignment, each source sample is expected to become similar to any target sample. However, global alignment may not always be optimal or necessary in practice. For example, consider cross-domain fraud detection, where there are two types of transactions: credit and non-credit. Aligning credit and non-credit transactions separately may yield better performance than global alignment, as credit transactions are unlikely to exhibit patterns similar to non-credit transactions. To enable such fine-grained domain adaption, we propose a novel Knowledge-Inspired Subdomain Adaptation (KISA) framework. In particular, (1) We provide the theoretical insight that KISA minimizes the shared expected loss which is the premise for the success of domain adaptation methods. (2) We propose the knowledge-inspired subdomain division problem that plays a crucial role in fine-grained domain adaption. (3) We design a knowledge fusion network to exploit diverse domain knowledge. Extensive experiments demonstrate that KISA achieves remarkable results on fraud detection and traffic demand prediction tasks.