 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Cross-Architecture Knowledge Transfer for Large-Scale Online User Response Prediction
Feb 02, 2026Deploying new architectures in large-scale user response prediction systems incurs high model switching costs due to expensive retraining on massive historical data and performance degradation under data retention constraints. Existing knowledge distillation methods struggle with architectural heterogeneity and the prohibitive cost of transferring large embedding tables. We propose CrossAdapt, a two-stage framework for efficient cross-architecture knowledge transfer. The offline stage enables rapid embedding transfer via dimension-adaptive projections without iterative training, combined with progressive network distillation and strategic sampling to reduce computational cost. The online stage introduces asymmetric co-distillation, where students update frequently while teachers update infrequently, together with a distribution-aware adaptation mechanism that dynamically balances historical knowledge preservation and fast adaptation to evolving data. Experiments on three public datasets show that CrossAdapt achieves 0.27-0.43% AUC improvements while reducing training time by 43-71%. Large-scale deployment on Tencent WeChat Channels (~10M daily samples) further demonstrates its effectiveness, significantly mitigating AUC degradation, LogLoss increase, and prediction bias compared to standard distillation baselines.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
Effect of Selection Format on LLM Performance
Mar 10, 2025This paper investigates a critical aspect of large language model (LLM) performance: the optimal formatting of classification task options in prompts. Through an extensive experimental study, we compared two selection formats -- bullet points and plain English -- to determine their impact on model performance. Our findings suggest that presenting options via bullet points generally yields better results, although there are some exceptions. Furthermore, our research highlights the need for continued exploration of option formatting to drive further improvements in model performance.
Interpretable Droplet Digital PCR Assay for Trustworthy Molecular Diagnostics
Jan 16, 2025



Accurate molecular quantification is essential for advancing research and diagnostics in fields such as infectious diseases, cancer biology, and genetic disorders. Droplet digital PCR (ddPCR) has emerged as a gold standard for achieving absolute quantification. While computational ddPCR technologies have advanced significantly, achieving automatic interpretation and consistent adaptability across diverse operational environments remains a challenge. To address these limitations, we introduce the intelligent interpretable droplet digital PCR (I2ddPCR) assay, a comprehensive framework integrating front-end predictive models (for droplet segmentation and classification) with GPT-4o multimodal large language model (MLLM, for context-aware explanations and recommendations) to automate and enhance ddPCR image analysis. This approach surpasses the state-of-the-art models, affording 99.05% accuracy in processing complex ddPCR images containing over 300 droplets per image with varying signal-to-noise ratios (SNRs). By combining specialized neural networks and large language models, the I2ddPCR assay offers a robust and adaptable solution for absolute molecular quantification, achieving a sensitivity capable of detecting low-abundance targets as low as 90.32 copies/{\mu}L. Furthermore, it improves model's transparency through detailed explanation and troubleshooting guidance, empowering users to make informed decisions. This innovative framework has the potential to benefit molecular diagnostics, disease research, and clinical applications, especially in resource-constrained settings.
Efficient User Sequence Learning for Online Services via Compressed Graph Neural Networks
Jun 05, 2024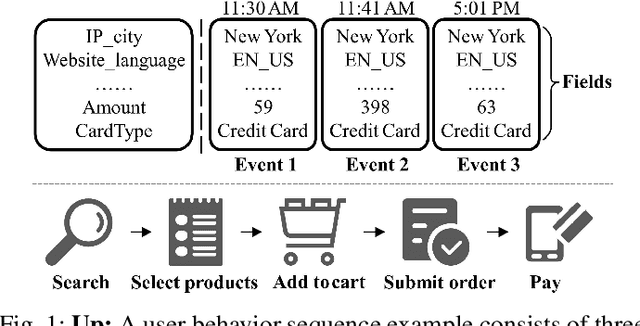
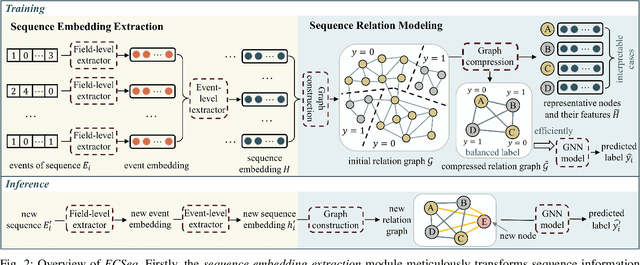
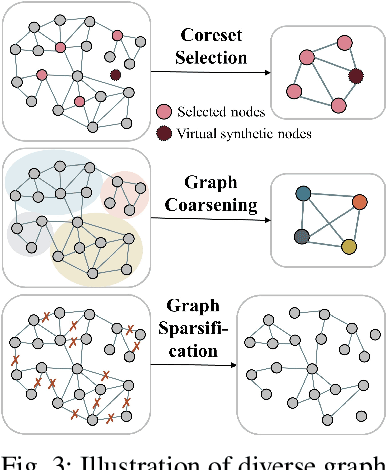
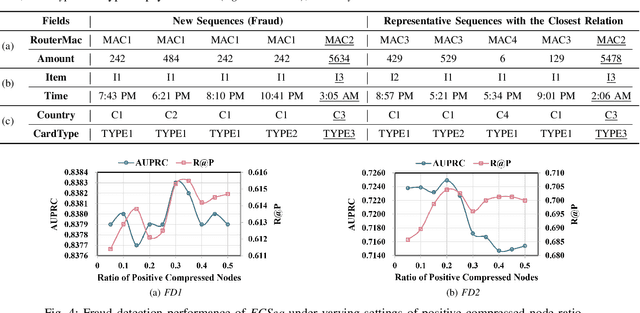
Learning representations of user behavior sequences is crucial for various online services, such as online fraudulent transaction detection mechanisms. Graph Neural Networks (GNNs) have been extensively applied to model sequence relationships, and extract information from similar sequences. While user behavior sequence data volume is usually huge for online applications, directly applying GNN models may lead to substantial computational overhead during both the training and inference stages and make it challenging to meet real-time requirements for online services. In this paper, we leverage graph compression techniques to alleviate the efficiency issue. Specifically, we propose a novel unified framework called ECSeq, to introduce graph compression techniques into relation modeling for user sequence representation learning. The key module of ECSeq is sequence relation modeling, which explores relationships among sequences to enhance sequence representation learning, and employs graph compression algorithms to achieve high efficiency and scalability. ECSeq also exhibits plug-and-play characteristics, seamlessly augmenting pre-trained sequence representation models without modifications. Empirical experiments on both sequence classification and regression tasks demonstrate the effectiveness of ECSeq. Specifically, with an additional training time of tens of seconds in total on 100,000+ sequences and inference time preserved within $10^{-4}$ seconds/sample, ECSeq improves the prediction R@P$_{0.9}$ of the widely used LSTM by $\sim 5\%$.
Graph Contrastive Learning with Cohesive Subgraph Awareness
Jan 31, 2024



Graph contrastive learning (GCL) has emerged as a state-of-the-art strategy for learning representations of diverse graphs including social and biomedical networks. GCL widely uses stochastic graph topology augmentation, such as uniform node dropping, to generate augmented graphs. However, such stochastic augmentations may severely damage the intrinsic properties of a graph and deteriorate the following representation learning process. We argue that incorporating an awareness of cohesive subgraphs during the graph augmentation and learning processes has the potential to enhance GCL performance. To this end, we propose a novel unified framework called CTAug, to seamlessly integrate cohesion awareness into various existing GCL mechanisms. In particular, CTAug comprises two specialized modules: topology augmentation enhancement and graph learning enhancement. The former module generates augmented graphs that carefully preserve cohesion properties, while the latter module bolsters the graph encoder's ability to discern subgraph patterns. Theoretical analysis shows that CTAug can strictly improve existing GCL mechanisms. Empirical experiments verify that CTAug can achieve state-of-the-art performance for graph representation learning, especially for graphs with high degrees. The code is available at https://doi.org/10.5281/zenodo.10594093, or https://github.com/wuyucheng2002/CTAug.