Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring and Addressing Reward Confusion in Offline Preference Learning
Paper and Code
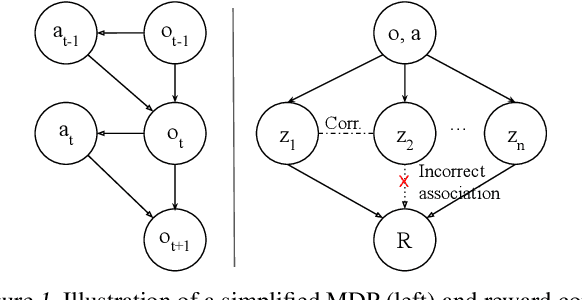
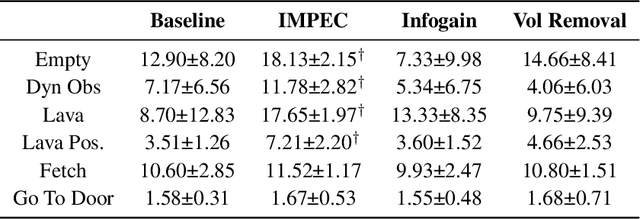
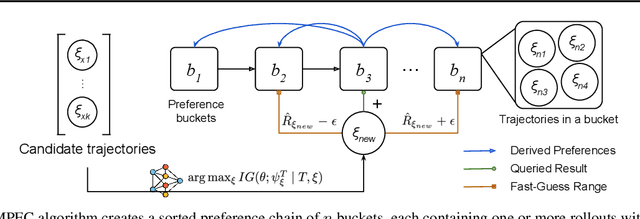
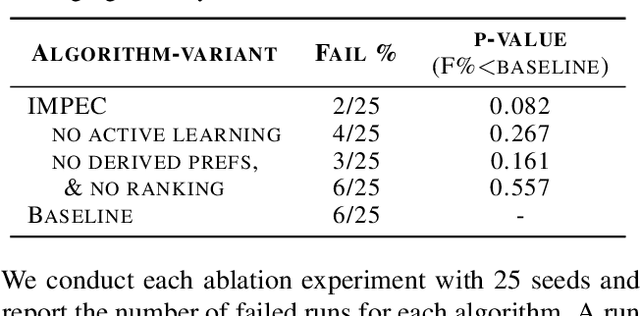
Spurious correlations in a reward model's training data can prevent Reinforcement Learning from Human Feedback (RLHF) from identifying the desired goal and induce unwanted behaviors. This paper shows that offline RLHF is susceptible to reward confusion, especially in the presence of spurious correlations in offline data. We create a benchmark to study this problem and propose a method that can significantly reduce reward confusion by leveraging transitivity of preferences while building a global preference chain with active learning.
View paper on