 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Investigation of Representation Learning for Imitation
Paper and Code
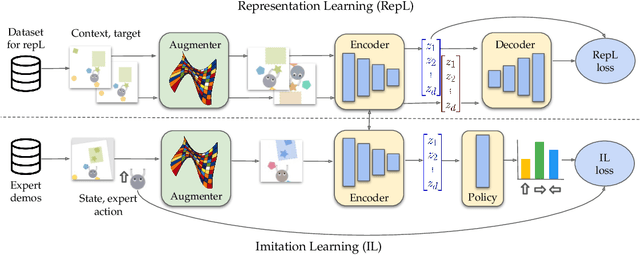
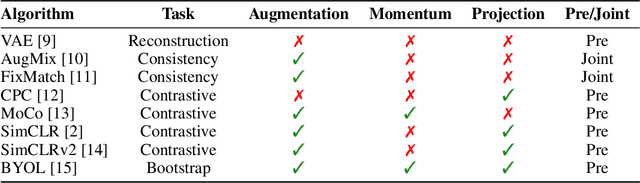

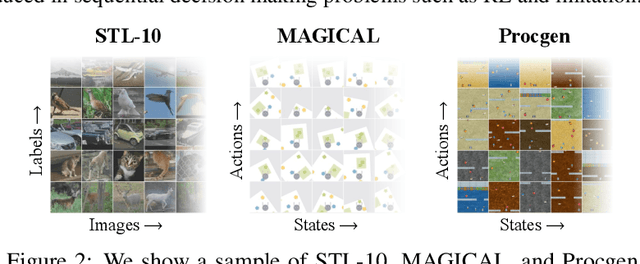
Imitation learning often needs a large demonstration set in order to handle the full range of situations that an agent might find itself in during deployment. However, collecting expert demonstrations can be expensive. Recent work in vision, reinforcement learning, and NLP has shown that auxiliary representation learning objectives can reduce the need for large amounts of expensive, task-specific data. Our Empirical Investigation of Representation Learning for Imitation (EIRLI) investigates whether similar benefits apply to imitation learning. We propose a modular framework for constructing representation learning algorithms, then use our framework to evaluate the utility of representation learning for imitation across several environment suites. In the settings we evaluate, we find that existing algorithms for image-based representation learning provide limited value relative to a well-tuned baseline with image augmentations. To explain this result, we investigate differences between imitation learning and other settings where representation learning has provided significant benefit, such as image classification. Finally, we release a well-documented codebase which both replicates our findings and provides a modular framework for creating new representation learning algorithms out of reusable components.