 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMAUG: End-to-End Full-Stack Simulation Infrastructure for Deep Learning Workloads
Paper and Code
Dec 11, 2019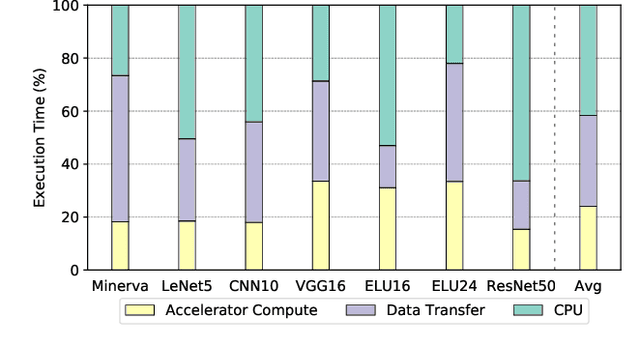
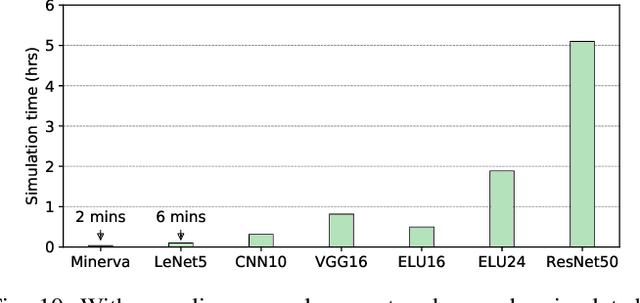
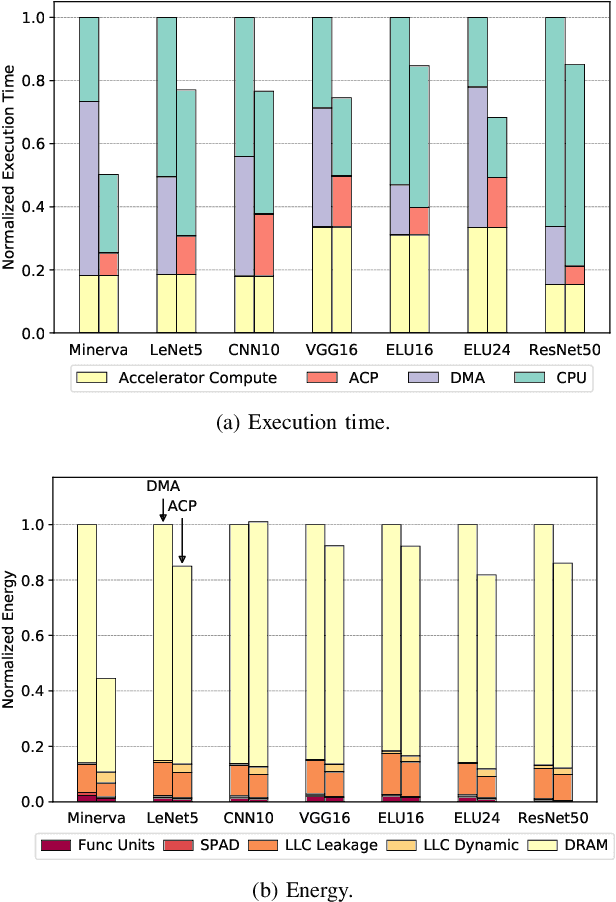
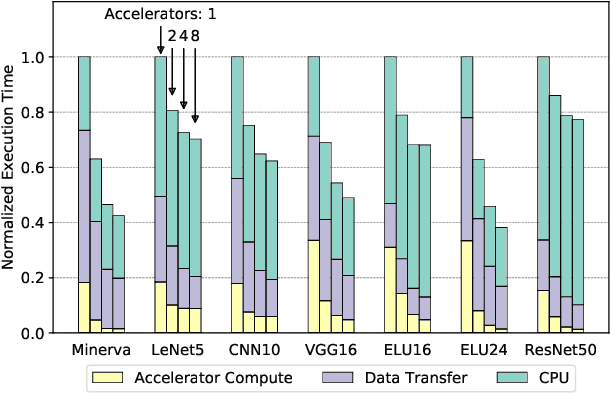
In recent years, there has been tremendous advances in hardware acceleration of deep neural networks. However, most of the research has focused on optimizing accelerator microarchitecture for higher performance and energy efficiency on a per-layer basis. We find that for overall single-batch inference latency, the accelerator may only make up 25-40%, with the rest spent on data movement and in the deep learning software framework. Thus far, it has been very difficult to study end-to-end DNN performance during early stage design (before RTL is available) because there are no existing DNN frameworks that support end-to-end simulation with easy custom hardware accelerator integration. To address this gap in research infrastructure, we present SMAUG, the first DNN framework that is purpose-built for simulation of end-to-end deep learning applications. SMAUG offers researchers a wide range of capabilities for evaluating DNN workloads, from diverse network topologies to easy accelerator modeling and SoC integration. To demonstrate the power and value of SMAUG, we present case studies that show how we can optimize overall performance and energy efficiency for up to 1.8-5x speedup over a baseline system, without changing any part of the accelerator microarchitecture, as well as show how SMAUG can tune an SoC for a camera-powered deep learning pipeline.