 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Generation with Answer Set Programming
Feb 06, 2024



Machine learning models that automate decision-making are increasingly being used in consequential areas such as loan approvals, pretrial bail approval, hiring, and many more. Unfortunately, most of these models are black-boxes, i.e., they are unable to reveal how they reach these prediction decisions. A need for transparency demands justification for such predictions. An affected individual might also desire explanations to understand why a decision was made. Ethical and legal considerations may further require informing the individual of changes in the input attribute that could be made to produce a desirable outcome. This paper focuses on the latter problem of automatically generating counterfactual explanations. We propose a framework Counterfactual Generation with s(CASP) (CFGS) that utilizes answer set programming (ASP) and the s(CASP) goal-directed ASP system to automatically generate counterfactual explanations from rules generated by rule-based machine learning (RBML) algorithms. In our framework, we show how counterfactual explanations are computed and justified by imagining worlds where some or all factual assumptions are altered/changed. More importantly, we show how we can navigate between these worlds, namely, go from our original world/scenario where we obtain an undesired outcome to the imagined world/scenario where we obtain a desired/favourable outcome.
Counterfactual Explanation Generation with s(CASP)
Oct 23, 2023


Machine learning models that automate decision-making are increasingly being used in consequential areas such as loan approvals, pretrial bail, hiring, and many more. Unfortunately, most of these models are black-boxes, i.e., they are unable to reveal how they reach these prediction decisions. A need for transparency demands justification for such predictions. An affected individual might desire explanations to understand why a decision was made. Ethical and legal considerations may further require informing the individual of changes in the input attribute that could be made to produce a desirable outcome. This paper focuses on the latter problem of automatically generating counterfactual explanations. Our approach utilizes answer set programming and the s(CASP) goal-directed ASP system. Answer Set Programming (ASP) is a well-known knowledge representation and reasoning paradigm. s(CASP) is a goal-directed ASP system that executes answer-set programs top-down without grounding them. The query-driven nature of s(CASP) allows us to provide justifications as proof trees, which makes it possible to analyze the generated counterfactual explanations. We show how counterfactual explanations are computed and justified by imagining multiple possible worlds where some or all factual assumptions are untrue and, more importantly, how we can navigate between these worlds. We also show how our algorithm can be used to find the Craig Interpolant for a class of answer set programs for a failing query.
FOLD-RM: A Scalable and Efficient Inductive Learning Algorithm for Multi-Category Classification of Mixed Data
Feb 25, 2022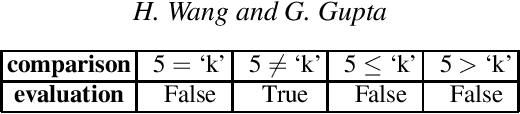

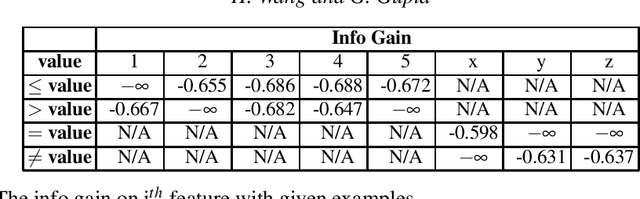
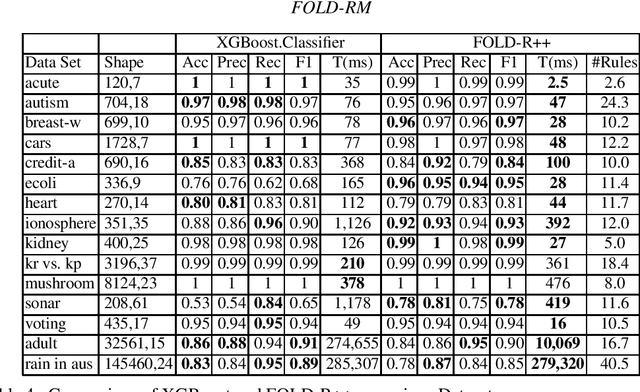
FOLD-RM is an automated inductive learning algorithm for learning default rules for mixed (numerical and categorical) data. It generates an (explainable) answer set programming (ASP) rule set for multi-category classification tasks while maintaining efficiency and scalability. The FOLD-RM algorithm is competitive in performance with the widely-used XGBoost algorithm, however, unlike XGBoost, the FOLD-RM algorithm produces an explainable model. FOLD-RM outperforms XGBoost on some datasets, particularly large ones. FOLD-RM also provides human-friendly explanations for predictions.
An ASP-based Approach to Answering Natural Language Questions for Texts
Dec 21, 2021
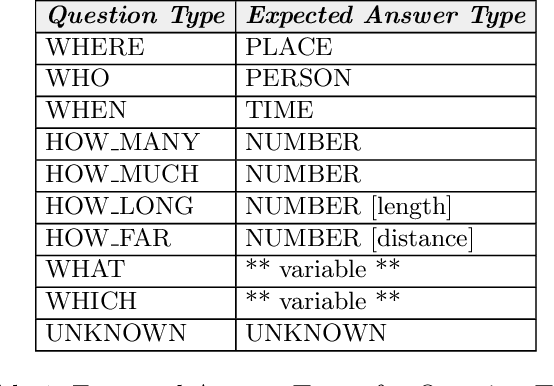
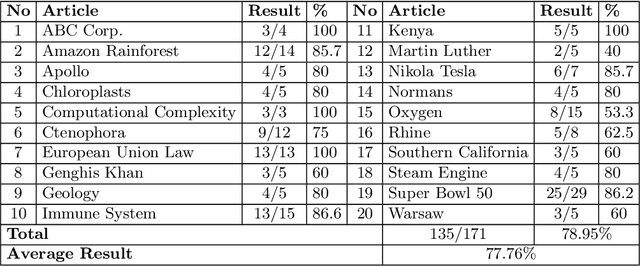
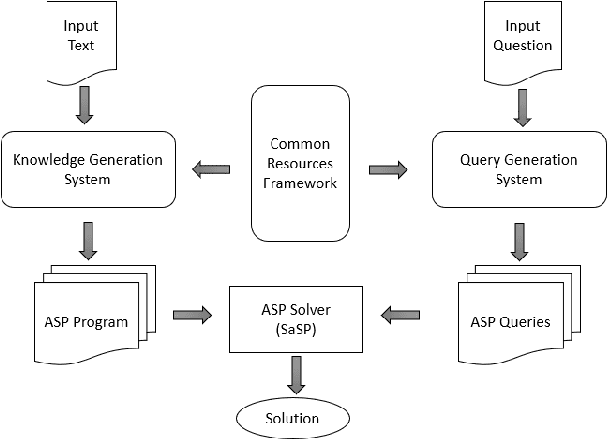
An approach based on answer set programming (ASP) is proposed in this paper for representing knowledge generated from natural language texts. Knowledge in a text is modeled using a Neo Davidsonian-like formalism, which is then represented as an answer set program. Relevant commonsense knowledge is additionally imported from resources such as WordNet and represented in ASP. The resulting knowledge-base can then be used to perform reasoning with the help of an ASP system. This approach can facilitate many natural language tasks such as automated question answering, text summarization, and automated question generation. ASP-based representation of techniques such as default reasoning, hierarchical knowledge organization, preferences over defaults, etc., are used to model commonsense reasoning methods required to accomplish these tasks. In this paper, we describe the CASPR system that we have developed to automate the task of answering natural language questions given English text. CASPR can be regarded as a system that answers questions by "understanding" the text and has been tested on the SQuAD data set, with promising results.
A Clustering and Demotion Based Algorithm for Inductive Learning of Default Theories
Sep 26, 2021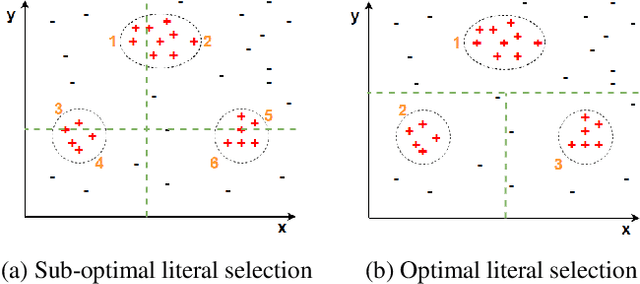
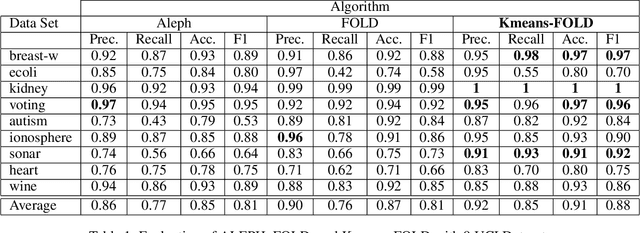
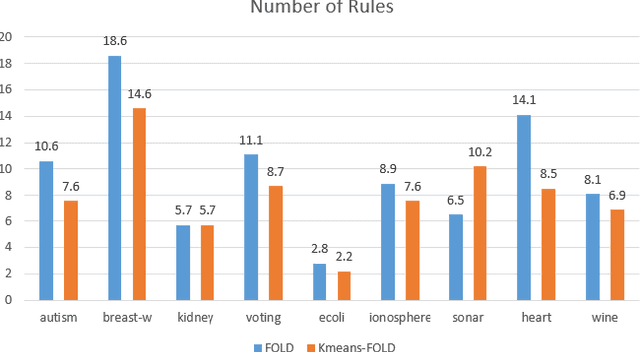
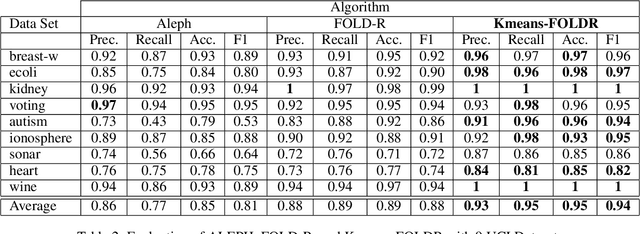
We present a clustering- and demotion-based algorithm called Kmeans-FOLD to induce nonmonotonic logic programs from positive and negative examples. Our algorithm improves upon-and is inspired by-the FOLD algorithm. The FOLD algorithm itself is an improvement over the FOIL algorithm. Our algorithm generates a more concise logic program compared to the FOLD algorithm. Our algorithm uses the K-means based clustering method to cluster the input positive samples before applying the FOLD algorithm. Positive examples that are covered by the partially learned program in intermediate steps are not discarded as in the FOLD algorithm, rather they are demoted, i.e., their weights are reduced in subsequent iterations of the algorithm. Our experiments on the UCI dataset show that a combination of K-Means clustering and our demotion strategy produces significant improvement for datasets with more than one cluster of positive examples. The resulting induced program is also more concise and therefore easier to understand compared to the FOLD and ALEPH systems, two state of the art inductive logic programming (ILP) systems.
Knowledge-driven Natural Language Understanding of English Text and its Applications
Jan 27, 2021Understanding the meaning of a text is a fundamental challenge of natural language understanding (NLU) research. An ideal NLU system should process a language in a way that is not exclusive to a single task or a dataset. Keeping this in mind, we have introduced a novel knowledge driven semantic representation approach for English text. By leveraging the VerbNet lexicon, we are able to map syntax tree of the text to its commonsense meaning represented using basic knowledge primitives. The general purpose knowledge represented from our approach can be used to build any reasoning based NLU system that can also provide justification. We applied this approach to construct two NLU applications that we present here: SQuARE (Semantic-based Question Answering and Reasoning Engine) and StaCACK (Stateful Conversational Agent using Commonsense Knowledge). Both these systems work by "truly understanding" the natural language text they process and both provide natural language explanations for their responses while maintaining high accuracy.
SQuARE: Semantics-based Question Answering and Reasoning Engine
Sep 22, 2020



Understanding the meaning of a text is a fundamental challenge of natural language understanding (NLU) and from its early days, it has received significant attention through question answering (QA) tasks. We introduce a general semantics-based framework for natural language QA and also describe the SQuARE system, an application of this framework. The framework is based on the denotational semantics approach widely used in programming language research. In our framework, valuation function maps syntax tree of the text to its commonsense meaning represented using basic knowledge primitives (the semantic algebra) coded using answer set programming (ASP). We illustrate an application of this framework by using VerbNet primitives as our semantic algebra and a novel algorithm based on partial tree matching that generates an answer set program that represents the knowledge in the text. A question posed against that text is converted into an ASP query using the same framework and executed using the s(CASP) goal-directed ASP system. Our approach is based purely on (commonsense) reasoning. SQuARE achieves 100% accuracy on all the five datasets of bAbI QA tasks that we have tested. The significance of our work is that, unlike other machine learning based approaches, ours is based on "understanding" the text and does not require any training. SQuARE can also generate an explanation for an answer while maintaining high accuracy.
* In Proceedings ICLP 2020, arXiv:2009.09158
White-box Induction From SVM Models: Explainable AI with Logic Programming
Aug 09, 2020We focus on the problem of inducing logic programs that explain models learned by the support vector machine (SVM) algorithm. The top-down sequential covering inductive logic programming (ILP) algorithms (e.g., FOIL) apply hill-climbing search using heuristics from information theory. A major issue with this class of algorithms is getting stuck in a local optimum. In our new approach, however, the data-dependent hill-climbing search is replaced with a model-dependent search where a globally optimal SVM model is trained first, then the algorithm looks into support vectors as the most influential data points in the model, and induces a clause that would cover the support vector and points that are most similar to that support vector. Instead of defining a fixed hypothesis search space, our algorithm makes use of SHAP, an example-specific interpreter in explainable AI, to determine a relevant set of features. This approach yields an algorithm that captures SVM model's underlying logic and outperforms %GG: the FOIL algorithm --> other ILP algorithms other ILP algorithms in terms of the number of induced clauses and classification evaluation metrics. This paper is under consideration for publication in the journal of "Theory and practice of logic programming".
Induction of Non-monotonic Logic Programs To Explain Statistical Learning Models
Sep 18, 2019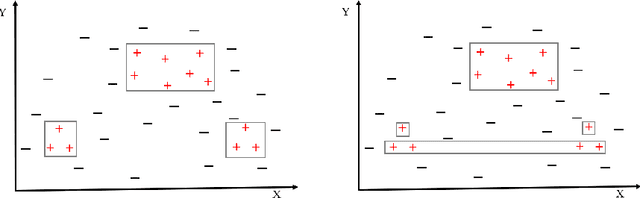

We present a fast and scalable algorithm to induce non-monotonic logic programs from statistical learning models. We reduce the problem of search for best clauses to instances of the High-Utility Itemset Mining (HUIM) problem. In the HUIM problem, feature values and their importance are treated as transactions and utilities respectively. We make use of TreeExplainer, a fast and scalable implementation of the Explainable AI tool SHAP, to extract locally important features and their weights from ensemble tree models. Our experiments with UCI standard benchmarks suggest a significant improvement in terms of classification evaluation metrics and running time of the training algorithm compared to ALEPH, a state-of-the-art Inductive Logic Programming (ILP) system.
* In Proceedings ICLP 2019, arXiv:1909.07646. arXiv admin note: substantial text overlap with arXiv:1808.00629, arXiv:1905.11226, arXiv:1802.06462, arXiv:1707.02693
Induction of Non-Monotonic Rules From Statistical Learning Models Using High-Utility Itemset Mining
May 29, 2019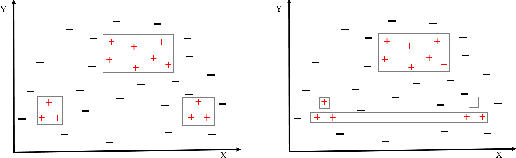

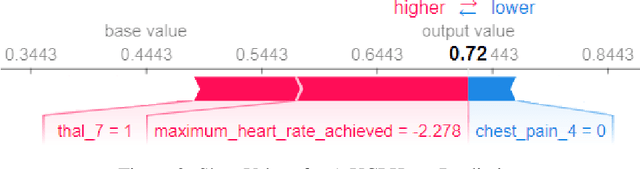
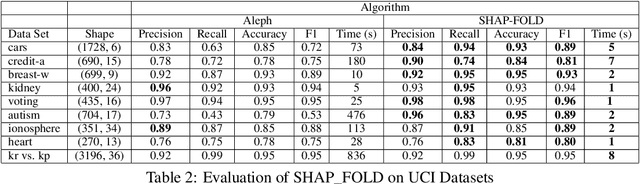
We present a fast and scalable algorithm to induce non-monotonic logic programs from statistical learning models. We reduce the problem of search for best clauses to instances of the High-Utility Itemset Mining (HUIM) problem. In the HUIM problem, feature values and their importance are treated as transactions and utilities respectively. We make use of TreeExplainer, a fast and scalable implementation of the Explainable AI tool SHAP, to extract locally important features and their weights from ensemble tree models. Our experiments with UCI standard benchmarks suggest a significant improvement in terms of classification evaluation metrics and running time of the training algorithm compared to ALEPH, a state-of-the-art Inductive Logic Programming (ILP) system.