 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Analysis of Submodular Information Measures for Targeted Data Subset Selection
Feb 21, 2024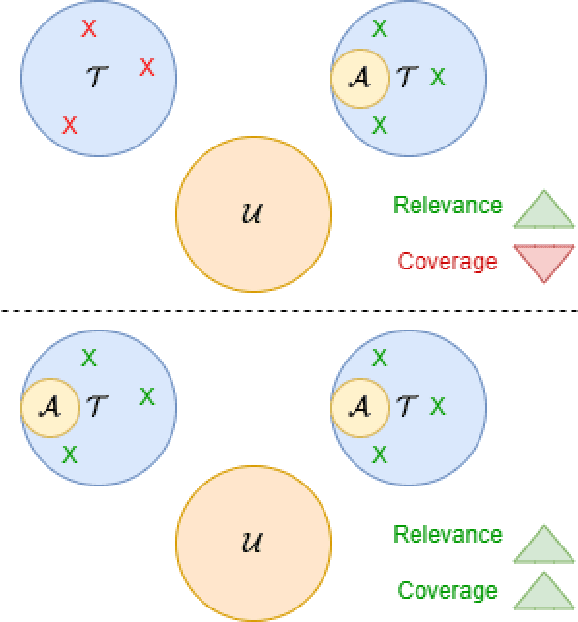
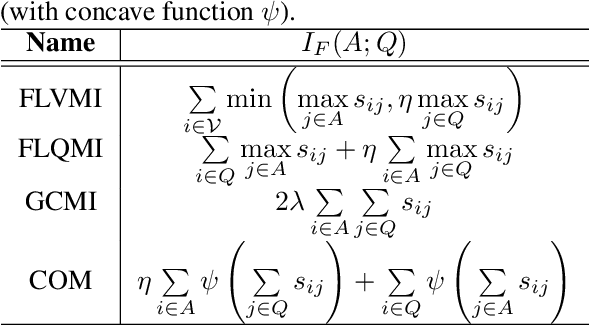
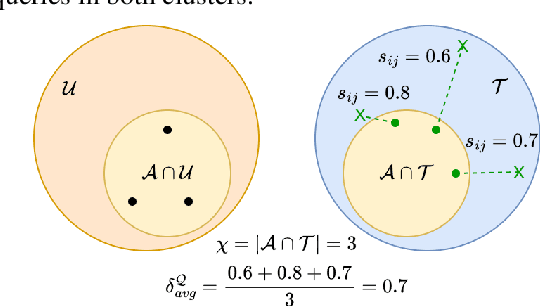
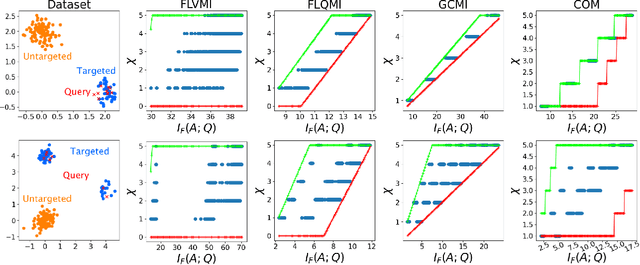
With increasing volume of data being used across machine learning tasks, the capability to target specific subsets of data becomes more important. To aid in this capability, the recently proposed Submodular Mutual Information (SMI) has been effectively applied across numerous tasks in literature to perform targeted subset selection with the aid of a exemplar query set. However, all such works are deficient in providing theoretical guarantees for SMI in terms of its sensitivity to a subset's relevance and coverage of the targeted data. For the first time, we provide such guarantees by deriving similarity-based bounds on quantities related to relevance and coverage of the targeted data. With these bounds, we show that the SMI functions, which have empirically shown success in multiple applications, are theoretically sound in achieving good query relevance and query coverage.
STENCIL: Submodular Mutual Information Based Weak Supervision for Cold-Start Active Learning
Feb 21, 2024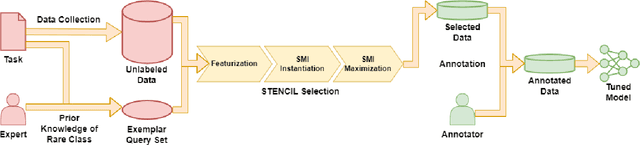

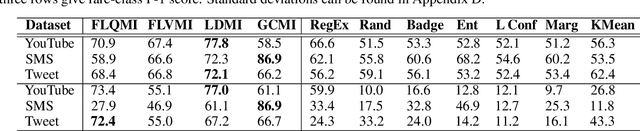
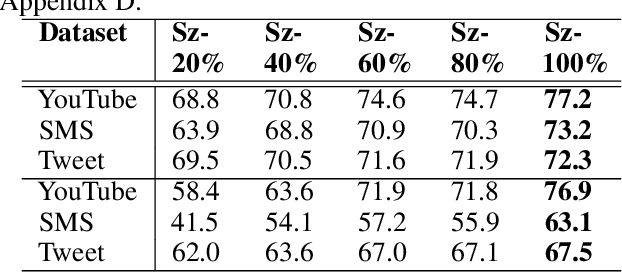
As supervised fine-tuning of pre-trained models within NLP applications increases in popularity, larger corpora of annotated data are required, especially with increasing parameter counts in large language models. Active learning, which attempts to mine and annotate unlabeled instances to improve model performance maximally fast, is a common choice for reducing the annotation cost; however, most methods typically ignore class imbalance and either assume access to initial annotated data or require multiple rounds of active learning selection before improving rare classes. We present STENCIL, which utilizes a set of text exemplars and the recently proposed submodular mutual information to select a set of weakly labeled rare-class instances that are then strongly labeled by an annotator. We show that STENCIL improves overall accuracy by $10\%-24\%$ and rare-class F-1 score by $17\%-40\%$ on multiple text classification datasets over common active learning methods within the class-imbalanced cold-start setting.
Beyond Active Learning: Leveraging the Full Potential of Human Interaction via Auto-Labeling, Human Correction, and Human Verification
Jun 02, 2023



Active Learning (AL) is a human-in-the-loop framework to interactively and adaptively label data instances, thereby enabling significant gains in model performance compared to random sampling. AL approaches function by selecting the hardest instances to label, often relying on notions of diversity and uncertainty. However, we believe that these current paradigms of AL do not leverage the full potential of human interaction granted by automated label suggestions. Indeed, we show that for many classification tasks and datasets, most people verifying if an automatically suggested label is correct take $3\times$ to $4\times$ less time than they do changing an incorrect suggestion to the correct label (or labeling from scratch without any suggestion). Utilizing this result, we propose CLARIFIER (aCtive LeARnIng From tIEred haRdness), an Interactive Learning framework that admits more effective use of human interaction by leveraging the reduced cost of verification. By targeting the hard (uncertain) instances with existing AL methods, the intermediate instances with a novel label suggestion scheme using submodular mutual information functions on a per-class basis, and the easy (confident) instances with highest-confidence auto-labeling, CLARIFIER can improve over the performance of existing AL approaches on multiple datasets -- particularly on those that have a large number of classes -- by almost 1.5$\times$ to 2$\times$ in terms of relative labeling cost.
STREAMLINE: Streaming Active Learning for Realistic Multi-Distributional Settings
May 18, 2023



Deep neural networks have consistently shown great performance in several real-world use cases like autonomous vehicles, satellite imaging, etc., effectively leveraging large corpora of labeled training data. However, learning unbiased models depends on building a dataset that is representative of a diverse range of realistic scenarios for a given task. This is challenging in many settings where data comes from high-volume streams, with each scenario occurring in random interleaved episodes at varying frequencies. We study realistic streaming settings where data instances arrive in and are sampled from an episodic multi-distributional data stream. Using submodular information measures, we propose STREAMLINE, a novel streaming active learning framework that mitigates scenario-driven slice imbalance in the working labeled data via a three-step procedure of slice identification, slice-aware budgeting, and data selection. We extensively evaluate STREAMLINE on real-world streaming scenarios for image classification and object detection tasks. We observe that STREAMLINE improves the performance on infrequent yet critical slices of the data over current baselines by up to $5\%$ in terms of accuracy on our image classification tasks and by up to $8\%$ in terms of mAP on our object detection tasks.
Transfer Reinforcement Learning for Differing Action Spaces via Q-Network Representations
Feb 15, 2022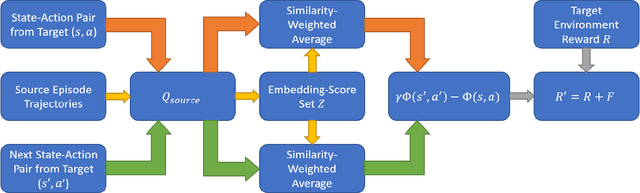

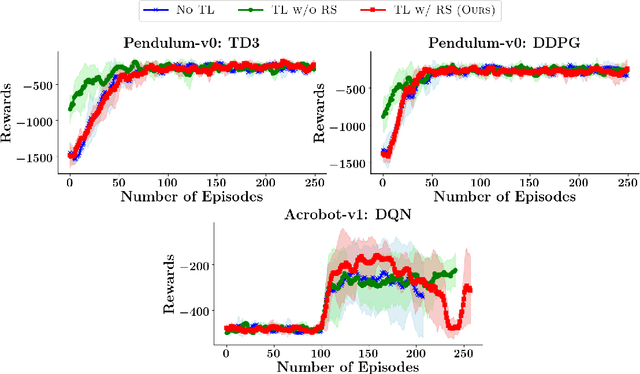
Transfer learning approaches in reinforcement learning aim to assist agents in learning their target domains by leveraging the knowledge learned from other agents that have been trained on similar source domains. For example, recent research focus within this space has been placed on knowledge transfer between tasks that have different transition dynamics and reward functions; however, little focus has been placed on knowledge transfer between tasks that have different action spaces. In this paper, we approach the task of transfer learning between domains that differ in action spaces. We present a reward shaping method based on source embedding similarity that is applicable to domains with both discrete and continuous action spaces. The efficacy of our approach is evaluated on transfer to restricted action spaces in the Acrobot-v1 and Pendulum-v0 domains. A comparison with two baselines shows that our method does not outperform these baselines in these continuous action spaces but does show an improvement in these discrete action spaces. We conclude our analysis with future directions for this work.
SIMILAR: Submodular Information Measures Based Active Learning In Realistic Scenarios
Jul 01, 2021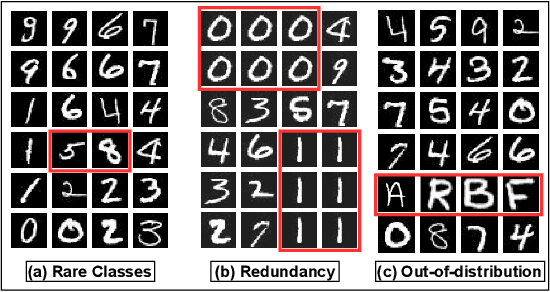

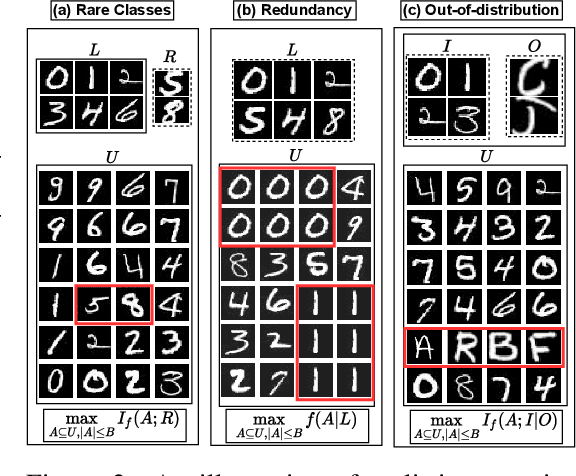
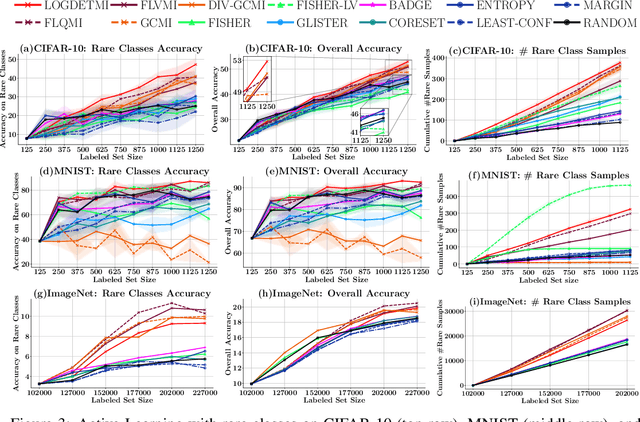
Active learning has proven to be useful for minimizing labeling costs by selecting the most informative samples. However, existing active learning methods do not work well in realistic scenarios such as imbalance or rare classes, out-of-distribution data in the unlabeled set, and redundancy. In this work, we propose SIMILAR (Submodular Information Measures based actIve LeARning), a unified active learning framework using recently proposed submodular information measures (SIM) as acquisition functions. We argue that SIMILAR not only works in standard active learning, but also easily extends to the realistic settings considered above and acts as a one-stop solution for active learning that is scalable to large real-world datasets. Empirically, we show that SIMILAR significantly outperforms existing active learning algorithms by as much as ~5% - 18% in the case of rare classes and ~5% - 10% in the case of out-of-distribution data on several image classification tasks like CIFAR-10, MNIST, and ImageNet.
Effective Evaluation of Deep Active Learning on Image Classification Tasks
Jun 30, 2021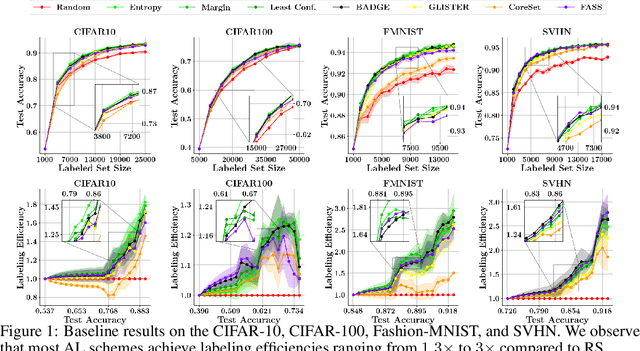
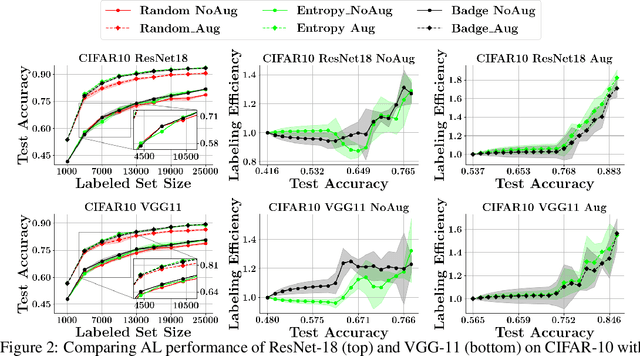
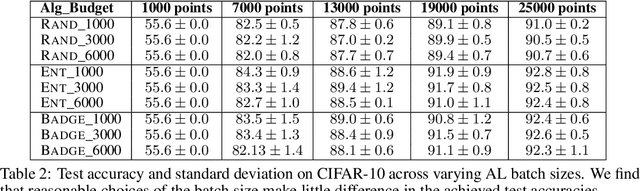
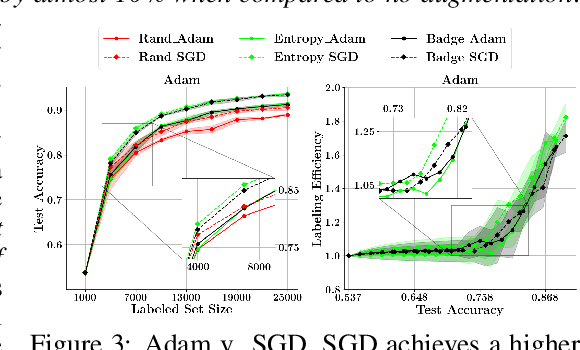
With the goal of making deep learning more label-efficient, a growing number of papers have been studying active learning (AL) for deep models. However, there are a number of issues in the prevalent experimental settings, mainly stemming from a lack of unified implementation and benchmarking. Issues in the current literature include sometimes contradictory observations on the performance of different AL algorithms, unintended exclusion of important generalization approaches such as data augmentation and SGD for optimization, a lack of study of evaluation facets like the labeling efficiency of AL, and little or no clarity on the scenarios in which AL outperforms random sampling (RS). In this work, we present a unified re-implementation of state-of-the-art AL algorithms in the context of image classification, and we carefully study these issues as facets of effective evaluation. On the positive side, we show that AL techniques are 2x to 4x more label-efficient compared to RS with the use of data augmentation. Surprisingly, when data augmentation is included, there is no longer a consistent gain in using BADGE, a state-of-the-art approach, over simple uncertainty sampling. We then do a careful analysis of how existing approaches perform with varying amounts of redundancy and number of examples per class. Finally, we provide several insights for AL practitioners to consider in future work, such as the effect of the AL batch size, the effect of initialization, the importance of retraining a new model at every round, and other insights.