 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Analysis of Submodular Information Measures for Targeted Data Subset Selection
Feb 21, 2024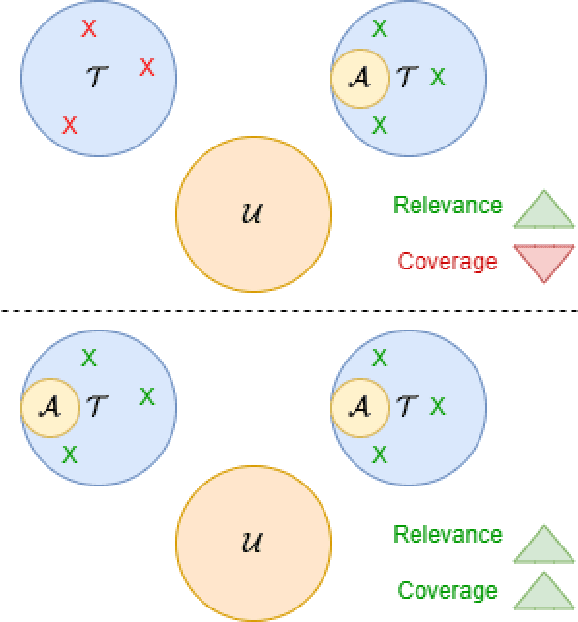
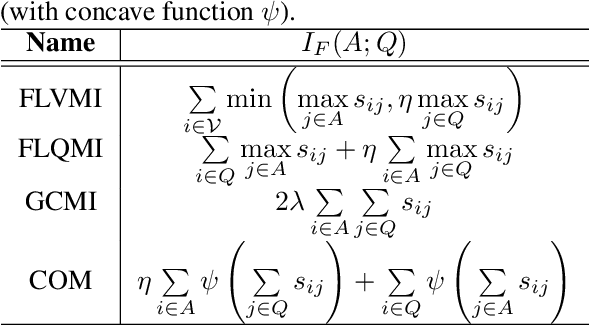
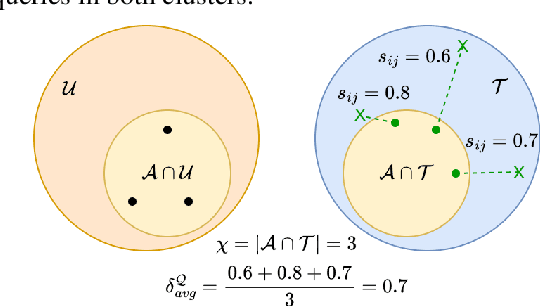
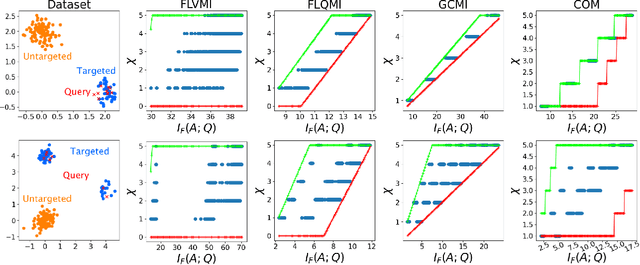
With increasing volume of data being used across machine learning tasks, the capability to target specific subsets of data becomes more important. To aid in this capability, the recently proposed Submodular Mutual Information (SMI) has been effectively applied across numerous tasks in literature to perform targeted subset selection with the aid of a exemplar query set. However, all such works are deficient in providing theoretical guarantees for SMI in terms of its sensitivity to a subset's relevance and coverage of the targeted data. For the first time, we provide such guarantees by deriving similarity-based bounds on quantities related to relevance and coverage of the targeted data. With these bounds, we show that the SMI functions, which have empirically shown success in multiple applications, are theoretically sound in achieving good query relevance and query coverage.