 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Evaluation of Deep Active Learning on Image Classification Tasks
Jun 30, 2021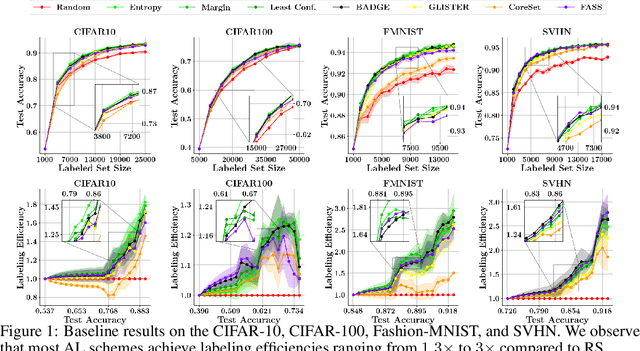
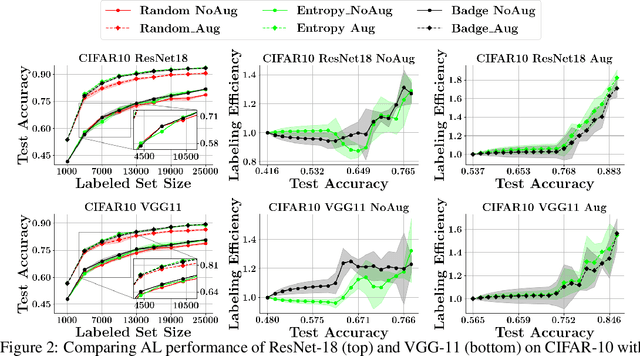
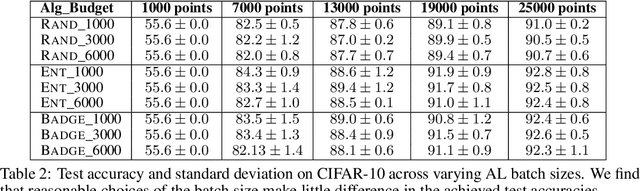
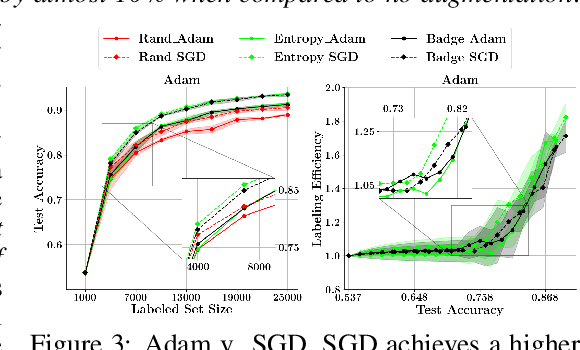
With the goal of making deep learning more label-efficient, a growing number of papers have been studying active learning (AL) for deep models. However, there are a number of issues in the prevalent experimental settings, mainly stemming from a lack of unified implementation and benchmarking. Issues in the current literature include sometimes contradictory observations on the performance of different AL algorithms, unintended exclusion of important generalization approaches such as data augmentation and SGD for optimization, a lack of study of evaluation facets like the labeling efficiency of AL, and little or no clarity on the scenarios in which AL outperforms random sampling (RS). In this work, we present a unified re-implementation of state-of-the-art AL algorithms in the context of image classification, and we carefully study these issues as facets of effective evaluation. On the positive side, we show that AL techniques are 2x to 4x more label-efficient compared to RS with the use of data augmentation. Surprisingly, when data augmentation is included, there is no longer a consistent gain in using BADGE, a state-of-the-art approach, over simple uncertainty sampling. We then do a careful analysis of how existing approaches perform with varying amounts of redundancy and number of examples per class. Finally, we provide several insights for AL practitioners to consider in future work, such as the effect of the AL batch size, the effect of initialization, the importance of retraining a new model at every round, and other insights.