 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Reinforcement Learning for Differing Action Spaces via Q-Network Representations
Paper and Code
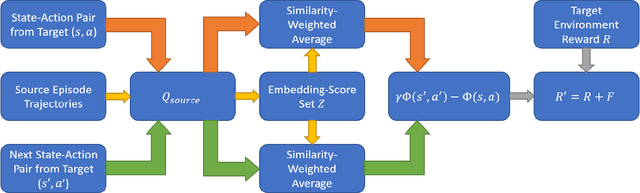

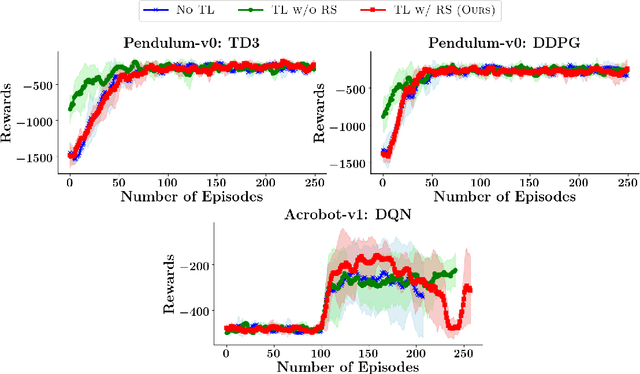
Transfer learning approaches in reinforcement learning aim to assist agents in learning their target domains by leveraging the knowledge learned from other agents that have been trained on similar source domains. For example, recent research focus within this space has been placed on knowledge transfer between tasks that have different transition dynamics and reward functions; however, little focus has been placed on knowledge transfer between tasks that have different action spaces. In this paper, we approach the task of transfer learning between domains that differ in action spaces. We present a reward shaping method based on source embedding similarity that is applicable to domains with both discrete and continuous action spaces. The efficacy of our approach is evaluated on transfer to restricted action spaces in the Acrobot-v1 and Pendulum-v0 domains. A comparison with two baselines shows that our method does not outperform these baselines in these continuous action spaces but does show an improvement in these discrete action spaces. We conclude our analysis with future directions for this work.