 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTENCIL: Submodular Mutual Information Based Weak Supervision for Cold-Start Active Learning
Paper and Code
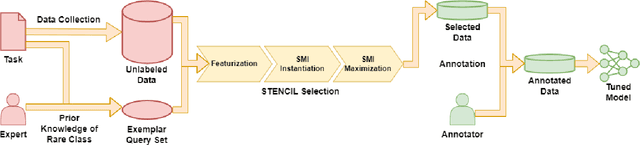

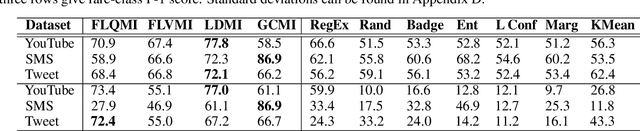
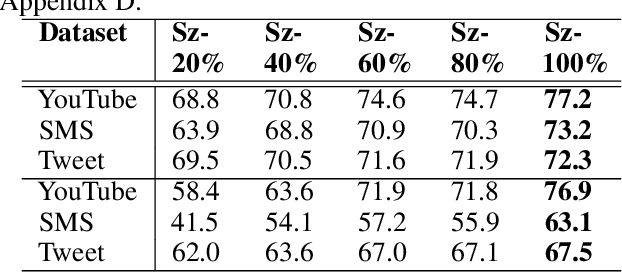
As supervised fine-tuning of pre-trained models within NLP applications increases in popularity, larger corpora of annotated data are required, especially with increasing parameter counts in large language models. Active learning, which attempts to mine and annotate unlabeled instances to improve model performance maximally fast, is a common choice for reducing the annotation cost; however, most methods typically ignore class imbalance and either assume access to initial annotated data or require multiple rounds of active learning selection before improving rare classes. We present STENCIL, which utilizes a set of text exemplars and the recently proposed submodular mutual information to select a set of weakly labeled rare-class instances that are then strongly labeled by an annotator. We show that STENCIL improves overall accuracy by $10\%-24\%$ and rare-class F-1 score by $17\%-40\%$ on multiple text classification datasets over common active learning methods within the class-imbalanced cold-start setting.