 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Visualized Framework for Event Cooperation with Generative Agents
Sep 16, 2025Large Language Models (LLMs) have revolutionized the simulation of agent societies, enabling autonomous planning, memory formation, and social interactions. However, existing frameworks often overlook systematic evaluations for event organization and lack visualized integration with physically grounded environments, limiting agents' ability to navigate spaces and interact with items realistically. We develop MiniAgentPro, a visualization platform featuring an intuitive map editor for customizing environments and a simulation player with smooth animations. Based on this tool, we introduce a comprehensive test set comprising eight diverse event scenarios with basic and hard variants to assess agents' ability. Evaluations using GPT-4o demonstrate strong performance in basic settings but highlight coordination challenges in hard variants.
FLEX: A Framework for Learning Robot-Agnostic Force-based Skills Involving Sustained Contact Object Manipulation
Mar 17, 2025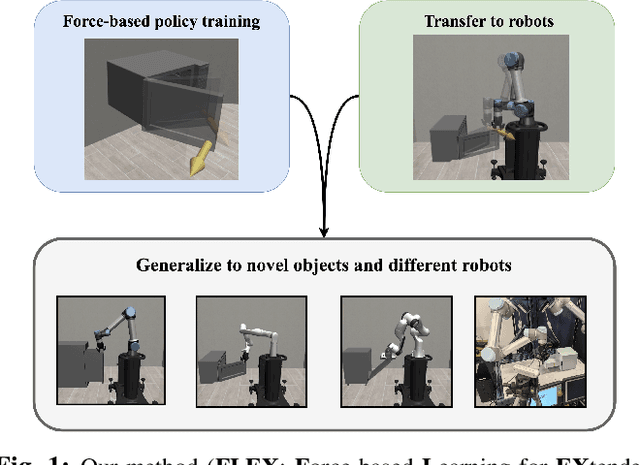
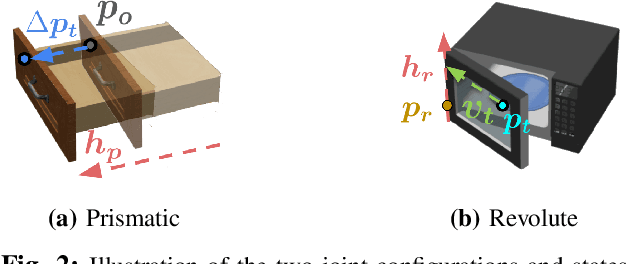
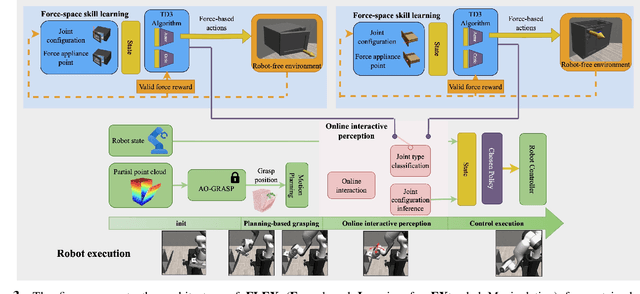
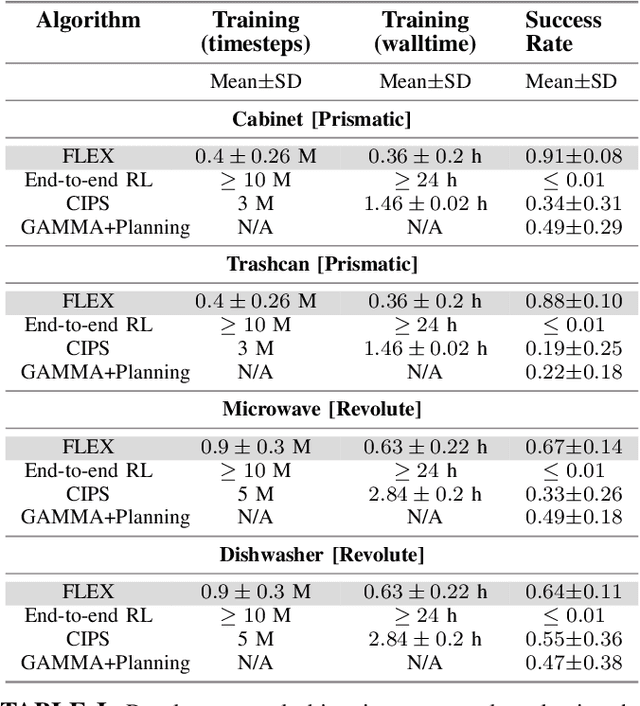
Learning to manipulate objects efficiently, particularly those involving sustained contact (e.g., pushing, sliding) and articulated parts (e.g., drawers, doors), presents significant challenges. Traditional methods, such as robot-centric reinforcement learning (RL), imitation learning, and hybrid techniques, require massive training and often struggle to generalize across different objects and robot platforms. We propose a novel framework for learning object-centric manipulation policies in force space, decoupling the robot from the object. By directly applying forces to selected regions of the object, our method simplifies the action space, reduces unnecessary exploration, and decreases simulation overhead. This approach, trained in simulation on a small set of representative objects, captures object dynamics -- such as joint configurations -- allowing policies to generalize effectively to new, unseen objects. Decoupling these policies from robot-specific dynamics enables direct transfer to different robotic platforms (e.g., Kinova, Panda, UR5) without retraining. Our evaluations demonstrate that the method significantly outperforms baselines, achieving over an order of magnitude improvement in training efficiency compared to other state-of-the-art methods. Additionally, operating in force space enhances policy transferability across diverse robot platforms and object types. We further showcase the applicability of our method in a real-world robotic setting. For supplementary materials and videos, please visit: https://tufts-ai-robotics-group.github.io/FLEX/
LgTS: Dynamic Task Sampling using LLM-generated sub-goals for Reinforcement Learning Agents
Oct 14, 2023



Recent advancements in reasoning abilities of Large Language Models (LLM) has promoted their usage in problems that require high-level planning for robots and artificial agents. However, current techniques that utilize LLMs for such planning tasks make certain key assumptions such as, access to datasets that permit finetuning, meticulously engineered prompts that only provide relevant and essential information to the LLM, and most importantly, a deterministic approach to allow execution of the LLM responses either in the form of existing policies or plan operators. In this work, we propose LgTS (LLM-guided Teacher-Student learning), a novel approach that explores the planning abilities of LLMs to provide a graphical representation of the sub-goals to a reinforcement learning (RL) agent that does not have access to the transition dynamics of the environment. The RL agent uses Teacher-Student learning algorithm to learn a set of successful policies for reaching the goal state from the start state while simultaneously minimizing the number of environmental interactions. Unlike previous methods that utilize LLMs, our approach does not assume access to a propreitary or a fine-tuned LLM, nor does it require pre-trained policies that achieve the sub-goals proposed by the LLM. Through experiments on a gridworld based DoorKey domain and a search-and-rescue inspired domain, we show that generating a graphical structure of sub-goals helps in learning policies for the LLM proposed sub-goals and the Teacher-Student learning algorithm minimizes the number of environment interactions when the transition dynamics are unknown.