 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne size does not fit all: Investigating strategies for differentially-private learning across NLP tasks
Dec 15, 2021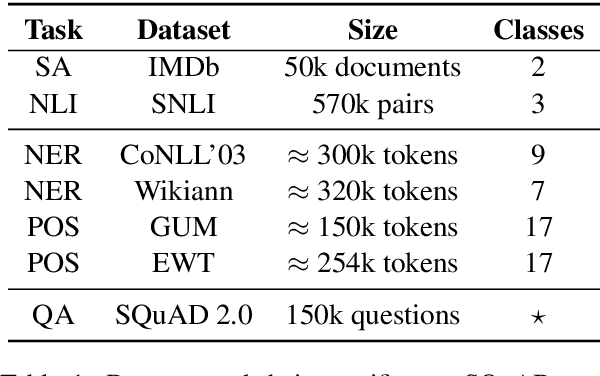
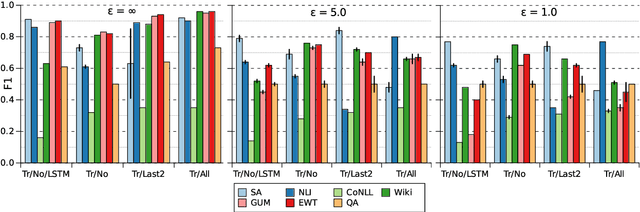
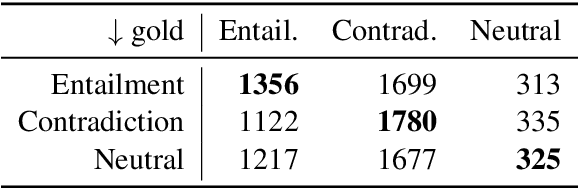
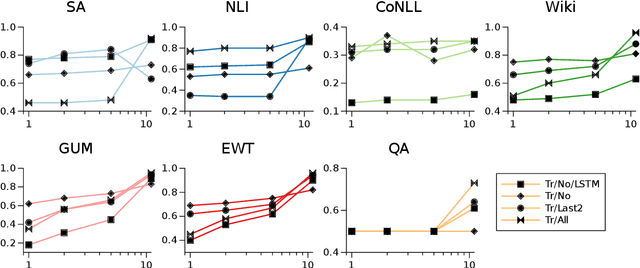
Preserving privacy in training modern NLP models comes at a cost. We know that stricter privacy guarantees in differentially-private stochastic gradient descent (DP-SGD) generally degrade model performance. However, previous research on the efficiency of DP-SGD in NLP is inconclusive or even counter-intuitive. In this short paper, we provide a thorough analysis of different privacy preserving strategies on seven downstream datasets in five different `typical' NLP tasks with varying complexity using modern neural models. We show that unlike standard non-private approaches to solving NLP tasks, where bigger is usually better, privacy-preserving strategies do not exhibit a winning pattern, and each task and privacy regime requires a special treatment to achieve adequate performance.