 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROMPT-SAW: Leveraging Relation-Aware Graphs for Textual Prompt Compression
Paper and Code
Mar 30, 2024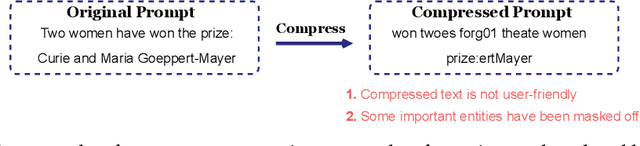
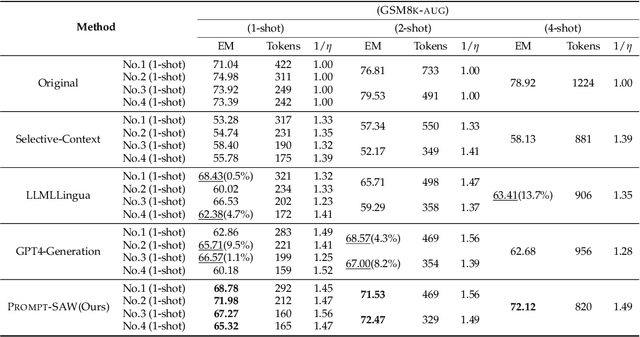
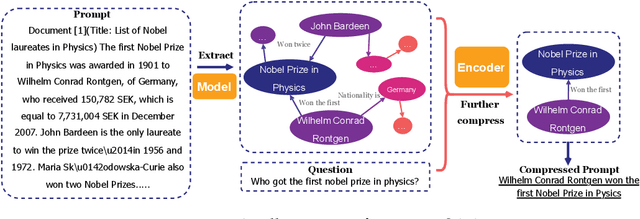
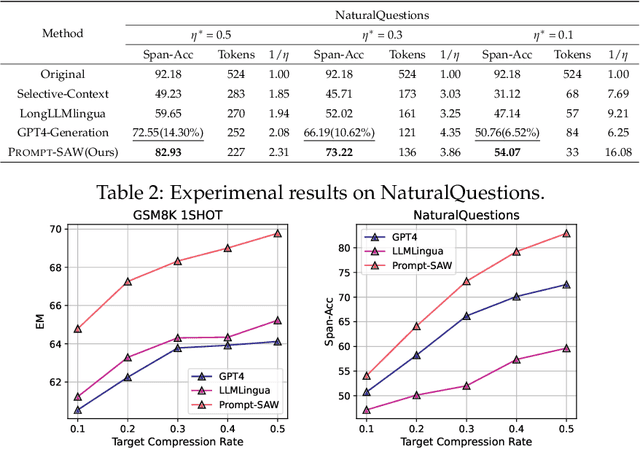
Large language models (LLMs) have shown exceptional abilities for multiple different natural language processing tasks. While prompting is a crucial tool for LLM inference, we observe that there is a significant cost associated with exceedingly lengthy prompts. Existing attempts to compress lengthy prompts lead to sub-standard results in terms of readability and interpretability of the compressed prompt, with a detrimental impact on prompt utility. To address this, we propose PROMPT-SAW: Prompt compresSion via Relation AWare graphs, an effective strategy for prompt compression over task-agnostic and task-aware prompts. PROMPT-SAW uses the prompt's textual information to build a graph, later extracts key information elements in the graph to come up with the compressed prompt. We also propose GSM8K-AUG, i.e., an extended version of the existing GSM8k benchmark for task-agnostic prompts in order to provide a comprehensive evaluation platform. Experimental evaluation using benchmark datasets shows that prompts compressed by PROMPT-SAW are not only better in terms of readability, but they also outperform the best-performing baseline models by up to 14.3 and 13.7 respectively for task-aware and task-agnostic settings while compressing the original prompt text by 33.0 and 56.7.