 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenign Overfitting in Adversarial Training for Vision Transformers
Apr 21, 2026Despite the remarkable success of Vision Transformers (ViTs) across a wide range of vision tasks, recent studies have revealed that they remain vulnerable to adversarial examples, much like Convolutional Neural Networks (CNNs). A common empirical defense strategy is adversarial training, yet the theoretical underpinnings of its robustness in ViTs remain largely unexplored. In this work, we present the first theoretical analysis of adversarial training under simplified ViT architectures. We show that, when trained under a signal-to-noise ratio that satisfies a certain condition and within a moderate perturbation budget, adversarial training enables ViTs to achieve nearly zero robust training loss and robust generalization error under certain regimes. Remarkably, this leads to strong generalization even in the presence of overfitting, a phenomenon known as \emph{benign overfitting}, previously only observed in CNNs (with adversarial training). Experiments on both synthetic and real-world datasets further validate our theoretical findings.
Understanding and Improving Continuous Adversarial Training for LLMs via In-context Learning Theory
Apr 14, 2026Adversarial training (AT) is an effective defense for large language models (LLMs) against jailbreak attacks, but performing AT on LLMs is costly. To improve the efficiency of AT for LLMs, recent studies propose continuous AT (CAT) that searches for adversarial inputs within the continuous embedding space of LLMs during AT. While CAT has achieved empirical success, its underlying mechanism, i.e., why adversarial perturbations in the embedding space can help LLMs defend against jailbreak prompts synthesized in the input token space, remains unknown. This paper presents the first theoretical analysis of CAT on LLMs based on in-context learning (ICL) theory. For linear transformers trained with adversarial examples from the embedding space on in-context linear regression tasks, we prove a robust generalization bound that has a negative correlation with the perturbation radius in the embedding space. This clearly explains why CAT can defend against jailbreak prompts from the LLM's token space. Further, the robust bound shows that the robustness of an adversarially trained LLM is closely related to the singular values of its embedding matrix. Based on this, we propose to improve LLM CAT by introducing an additional regularization term, which depends on singular values of the LLM's embedding matrix, into the objective function of CAT. Experiments on real-world LLMs demonstrate that our method can help LLMs achieve a better jailbreak robustness-utility tradeoff. The code is available at https://github.com/fshp971/continuous-adv-icl.
RefineRL: Advancing Competitive Programming with Self-Refinement Reinforcement Learning
Apr 01, 2026While large language models (LLMs) have demonstrated strong performance on complex reasoning tasks such as competitive programming (CP), existing methods predominantly focus on single-attempt settings, overlooking their capacity for iterative refinement. In this paper, we present RefineRL, a novel approach designed to unleash the self-refinement capabilities of LLMs for CP problem solving. RefineRL introduces two key innovations: (1) Skeptical-Agent, an iterative self-refinement agent equipped with local execution tools to validate generated solutions against public test cases of CP problems. This agent always maintains a skeptical attitude towards its own outputs and thereby enforces rigorous self-refinement even when validation suggests correctness. (2) A reinforcement learning (RL) solution to incentivize LLMs to self-refine with only standard RLVR data (i.e., problems paired with their verifiable answers). Extensive experiments on Qwen3-4B and Qwen3-4B-2507 demonstrate that our method yields substantial gains: after our RL training, these compact 4B models integrated with the Skeptical-Agent not only outperform much larger 32B models but also approach the single-attempt performance of 235B models. These findings suggest that self-refinement holds considerable promise for scaling LLM reasoning, with significant potential for further advancement.
Accelerating Suffix Jailbreak attacks with Prefix-Shared KV-cache
Mar 12, 2026Suffix jailbreak attacks serve as a systematic method for red-teaming Large Language Models (LLMs) but suffer from prohibitive computational costs, as a large number of candidate suffixes need to be evaluated before identifying a jailbreak suffix. This paper presents Prefix-Shared KV Cache (PSKV), a plug-and-play inference optimization technique tailored for jailbreak suffix generation. Our method is motivated by a key observation that when performing suffix jailbreaking, while a large number of candidate prompts need to be evaluated, they share the same targeted harmful instruction as the prefix. Therefore, instead of performing redundant inference on the duplicated prefix, PSKV maintains a single KV cache for this prefix and shares it with every candidate prompt, enabling the parallel inference of diverse suffixes with minimal memory overhead. This design enables more aggressive batching strategies that would otherwise be limited by memory constraints. Extensive experiments on six widely used suffix attacks across five widely deployed LLMs demonstrate that PSKV reduces inference time by 40\% and peak memory usage by 50\%, while maintaining the original Attack Success Rate (ASR). The code has been submitted and will be released publicly.
Concept-Based Dictionary Learning for Inference-Time Safety in Vision Language Action Models
Feb 02, 2026Vision Language Action (VLA) models close the perception action loop by translating multimodal instructions into executable behaviors, but this very capability magnifies safety risks: jailbreaks that merely yield toxic text in LLMs can trigger unsafe physical actions in embodied systems. Existing defenses alignment, filtering, or prompt hardening intervene too late or at the wrong modality, leaving fused representations exploitable. We introduce a concept-based dictionary learning framework for inference-time safety control. By constructing sparse, interpretable dictionaries from hidden activations, our method identifies harmful concept directions and applies threshold-based interventions to suppress or block unsafe activations. Experiments on Libero-Harm, BadRobot, RoboPair, and IS-Bench show that our approach achieves state-of-the-art defense performance, cutting attack success rates by over 70\% while maintaining task success. Crucially, the framework is plug-in and model-agnostic, requiring no retraining and integrating seamlessly with diverse VLAs. To our knowledge, this is the first inference-time concept-based safety method for embodied systems, advancing both interpretability and safe deployment of VLA models.
Understanding the Impact of Differentially Private Training on Memorization of Long-Tailed Data
Feb 01, 2026Recent research shows that modern deep learning models achieve high predictive accuracy partly by memorizing individual training samples. Such memorization raises serious privacy concerns, motivating the widespread adoption of differentially private training algorithms such as DP-SGD. However, a growing body of empirical work shows that DP-SGD often leads to suboptimal generalization performance, particularly on long-tailed data that contain a large number of rare or atypical samples. Despite these observations, a theoretical understanding of this phenomenon remains largely unexplored, and existing differential privacy analysis are difficult to extend to the nonconvex and nonsmooth neural networks commonly used in practice. In this work, we develop the first theoretical framework for analyzing DP-SGD on long-tailed data from a feature learning perspective. We show that the test error of DP-SGD-trained models on the long-tailed subpopulation is significantly larger than the overall test error over the entire dataset. Our analysis further characterizes the training dynamics of DP-SGD, demonstrating how gradient clipping and noise injection jointly adversely affect the model's ability to memorize informative but underrepresented samples. Finally, we validate our theoretical findings through extensive experiments on both synthetic and real-world datasets.
C^2 ATTACK: Towards Representation Backdoor on CLIP via Concept Confusion
Mar 12, 2025Backdoor attacks pose a significant threat to deep learning models, enabling adversaries to embed hidden triggers that manipulate the behavior of the model during inference. Traditional backdoor attacks typically rely on inserting explicit triggers (e.g., external patches, or perturbations) into input data, but they often struggle to evade existing defense mechanisms. To address this limitation, we investigate backdoor attacks through the lens of the reasoning process in deep learning systems, drawing insights from interpretable AI. We conceptualize backdoor activation as the manipulation of learned concepts within the model's latent representations. Thus, existing attacks can be seen as implicit manipulations of these activated concepts during inference. This raises interesting questions: why not manipulate the concepts explicitly? This idea leads to our novel backdoor attack framework, Concept Confusion Attack (C^2 ATTACK), which leverages internal concepts in the model's reasoning as "triggers" without introducing explicit external modifications. By avoiding the use of real triggers and directly activating or deactivating specific concepts in latent spaces, our approach enhances stealth, making detection by existing defenses significantly harder. Using CLIP as a case study, experimental results demonstrate the effectiveness of C^2 ATTACK, achieving high attack success rates while maintaining robustness against advanced defenses.
"Short-length" Adversarial Training Helps LLMs Defend "Long-length" Jailbreak Attacks: Theoretical and Empirical Evidence
Feb 06, 2025Jailbreak attacks against large language models (LLMs) aim to induce harmful behaviors in LLMs through carefully crafted adversarial prompts. To mitigate attacks, one way is to perform adversarial training (AT)-based alignment, i.e., training LLMs on some of the most adversarial prompts to help them learn how to behave safely under attacks. During AT, the length of adversarial prompts plays a critical role in the robustness of aligned LLMs. This paper focuses on adversarial suffix jailbreak attacks and unveils that to defend against a jailbreak attack with an adversarial suffix of length $\Theta(M)$, it is enough to align LLMs on prompts with adversarial suffixes of length $\Theta(\sqrt{M})$. Theoretically, we analyze the adversarial in-context learning of linear transformers on linear regression tasks and prove a robust generalization bound for trained transformers. The bound depends on the term $\Theta(\sqrt{M_{\text{test}}}/M_{\text{train}})$, where $M_{\text{train}}$ and $M_{\text{test}}$ are the number of adversarially perturbed in-context samples during training and testing. Empirically, we conduct AT on popular open-source LLMs and evaluate their robustness against jailbreak attacks of different adversarial suffix lengths. Results confirm a positive correlation between the attack success rate and the ratio of the square root of the adversarial suffix during jailbreaking to the length during AT. Our findings show that it is practical to defend "long-length" jailbreak attacks via efficient "short-length" AT. The code is available at https://github.com/fshp971/adv-icl.
Pre-trained Encoder Inference: Revealing Upstream Encoders In Downstream Machine Learning Services
Aug 05, 2024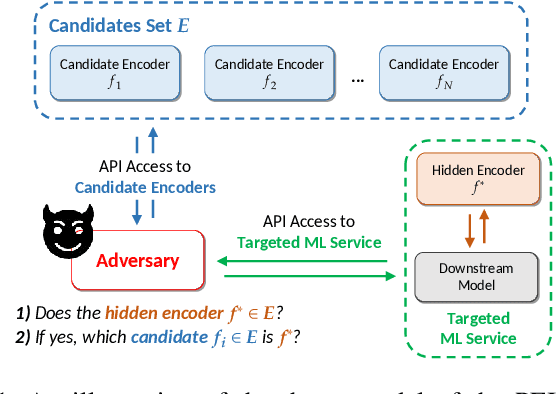

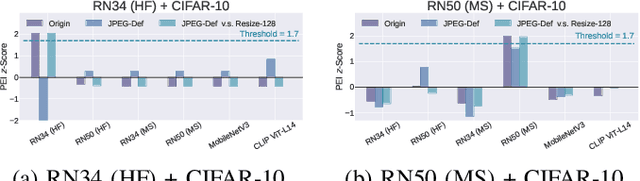
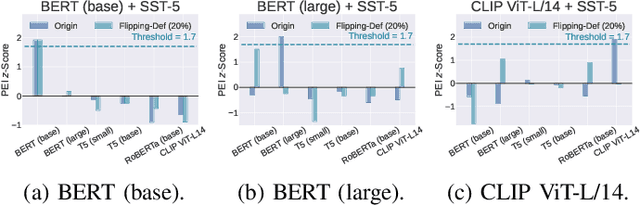
Though pre-trained encoders can be easily accessed online to build downstream machine learning (ML) services quickly, various attacks have been designed to compromise the security and privacy of these encoders. While most attacks target encoders on the upstream side, it remains unknown how an encoder could be threatened when deployed in a downstream ML service. This paper unveils a new vulnerability: the Pre-trained Encoder Inference (PEI) attack, which posts privacy threats toward encoders hidden behind downstream ML services. By only providing API accesses to a targeted downstream service and a set of candidate encoders, the PEI attack can infer which encoder is secretly used by the targeted service based on candidate ones. We evaluate the attack performance of PEI against real-world encoders on three downstream tasks: image classification, text classification, and text-to-image generation. Experiments show that the PEI attack succeeds in revealing the hidden encoder in most cases and seldom makes mistakes even when the hidden encoder is not in the candidate set. We also conducted a case study on one of the most recent vision-language models, LLaVA, to illustrate that the PEI attack is useful in assisting other ML attacks such as adversarial attacks. The code is available at https://github.com/fshp971/encoder-inference.
Theoretical Analysis of Robust Overfitting for Wide DNNs: An NTK Approach
Oct 09, 2023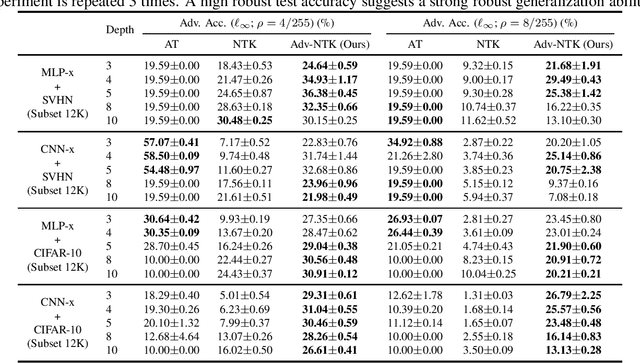

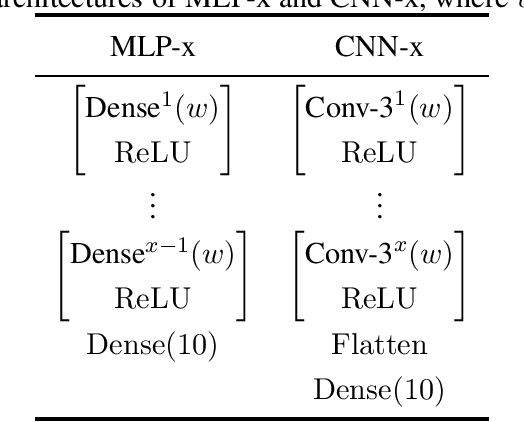
Adversarial training (AT) is a canonical method for enhancing the robustness of deep neural networks (DNNs). However, recent studies empirically demonstrated that it suffers from robust overfitting, i.e., a long time AT can be detrimental to the robustness of DNNs. This paper presents a theoretical explanation of robust overfitting for DNNs. Specifically, we non-trivially extend the neural tangent kernel (NTK) theory to AT and prove that an adversarially trained wide DNN can be well approximated by a linearized DNN. Moreover, for squared loss, closed-form AT dynamics for the linearized DNN can be derived, which reveals a new AT degeneration phenomenon: a long-term AT will result in a wide DNN degenerates to that obtained without AT and thus cause robust overfitting. Based on our theoretical results, we further design a method namely Adv-NTK, the first AT algorithm for infinite-width DNNs. Experiments on real-world datasets show that Adv-NTK can help infinite-width DNNs enhance comparable robustness to that of their finite-width counterparts, which in turn justifies our theoretical findings. The code is available at https://github.com/fshp971/adv-ntk.