 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Encoder Inference: Revealing Upstream Encoders In Downstream Machine Learning Services
Paper and Code
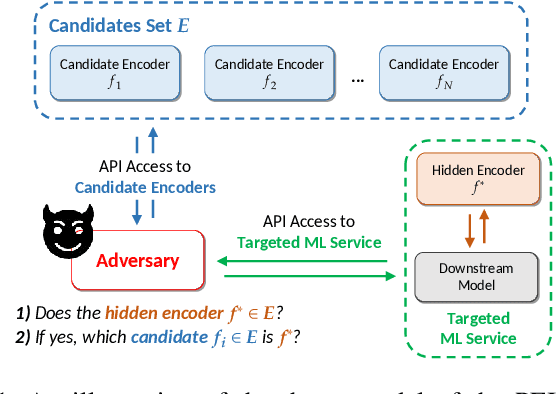

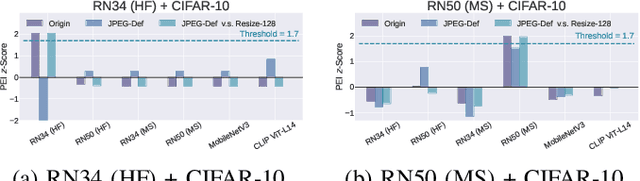
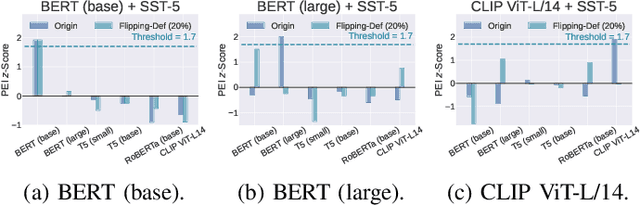
Though pre-trained encoders can be easily accessed online to build downstream machine learning (ML) services quickly, various attacks have been designed to compromise the security and privacy of these encoders. While most attacks target encoders on the upstream side, it remains unknown how an encoder could be threatened when deployed in a downstream ML service. This paper unveils a new vulnerability: the Pre-trained Encoder Inference (PEI) attack, which posts privacy threats toward encoders hidden behind downstream ML services. By only providing API accesses to a targeted downstream service and a set of candidate encoders, the PEI attack can infer which encoder is secretly used by the targeted service based on candidate ones. We evaluate the attack performance of PEI against real-world encoders on three downstream tasks: image classification, text classification, and text-to-image generation. Experiments show that the PEI attack succeeds in revealing the hidden encoder in most cases and seldom makes mistakes even when the hidden encoder is not in the candidate set. We also conducted a case study on one of the most recent vision-language models, LLaVA, to illustrate that the PEI attack is useful in assisting other ML attacks such as adversarial attacks. The code is available at https://github.com/fshp971/encoder-inference.