 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-module GRPO: Composing Policy Gradients and Prompt Optimization for Language Model Programs
Aug 06, 2025Group Relative Policy Optimization (GRPO) has proven to be an effective tool for post-training language models (LMs). However, AI systems are increasingly expressed as modular programs that mix together multiple LM calls with distinct prompt templates and other tools, and it is not clear how best to leverage GRPO to improve these systems. We begin to address this challenge by defining mmGRPO, a simple multi-module generalization of GRPO that groups LM calls by module across rollouts and handles variable-length and interrupted trajectories. We find that mmGRPO, composed with automatic prompt optimization, improves accuracy by 11% on average across classification, many-hop search, and privacy-preserving delegation tasks against the post-trained LM, and by 5% against prompt optimization on its own. We open-source mmGRPO in DSPy as the dspy.GRPO optimizer.
Optimizing Decomposition for Optimal Claim Verification
Mar 19, 2025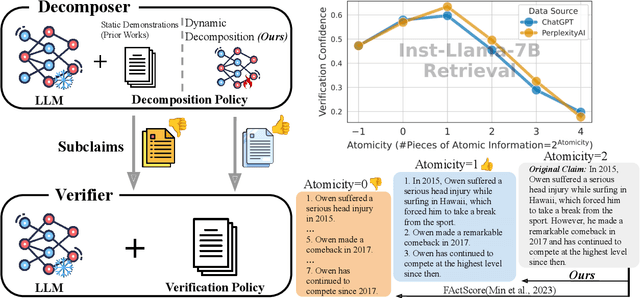
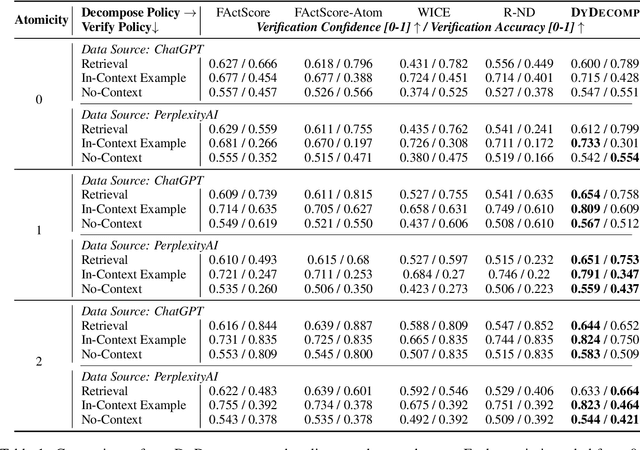
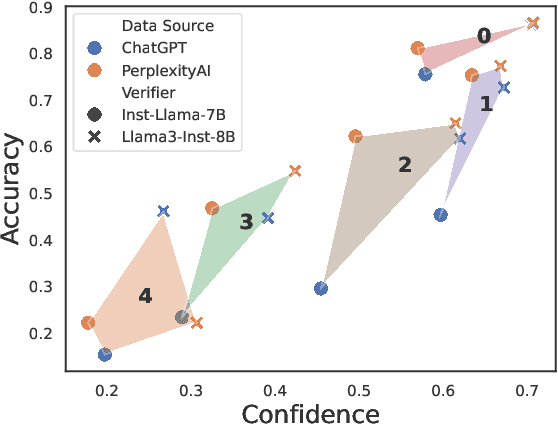
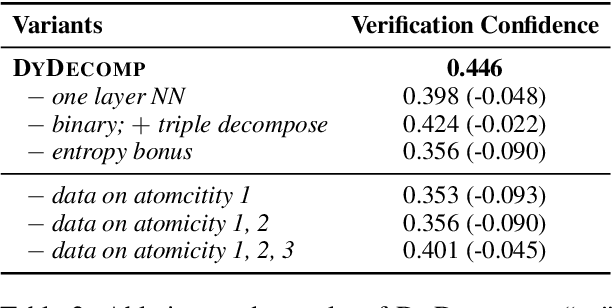
Current research on the \textit{Decompose-Then-Verify} paradigm for evaluating the factuality of long-form text typically treats decomposition and verification in isolation, overlooking their interactions and potential misalignment. We find that existing decomposition policies, typically hand-crafted demonstrations, do not align well with downstream verifiers in terms of atomicity -- a novel metric quantifying information density -- leading to suboptimal verification results. We formulate finding the optimal decomposition policy for optimal verification as a bilevel optimization problem. To approximate a solution for this strongly NP-hard problem, we propose dynamic decomposition, a reinforcement learning framework that leverages verifier feedback to learn a policy for dynamically decomposing claims to verifier-preferred atomicity. Experimental results show that dynamic decomposition outperforms existing decomposition policies, improving verification confidence by 0.07 and accuracy by 0.12 (on a 0-1 scale) on average across varying verifiers, datasets, and atomcities of input claims.
TOWER: Tree Organized Weighting for Evaluating Complex Instructions
Oct 08, 2024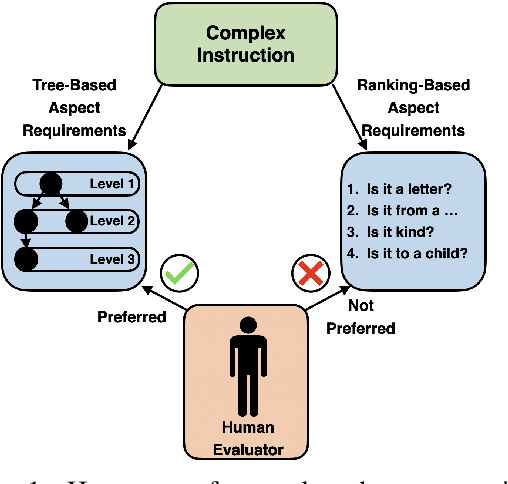
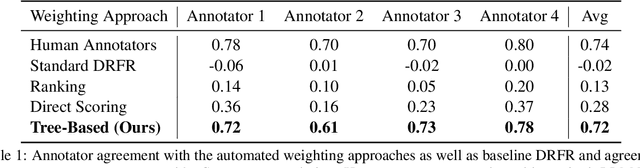
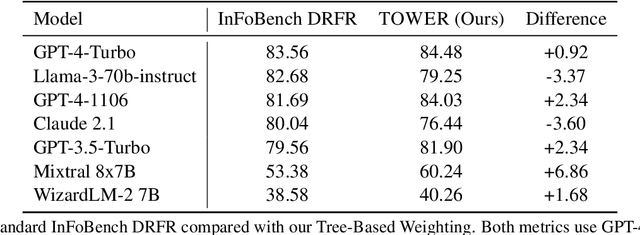
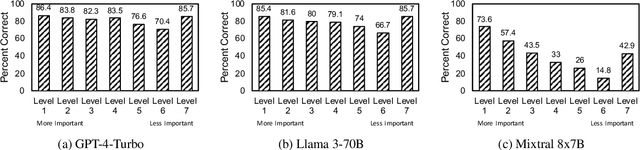
Evaluating the ability of large language models (LLMs) to follow complex human-written instructions is essential for their deployment in real-world applications. While benchmarks like Chatbot Arena use human judges to assess model performance, they are resource-intensive and time-consuming. Alternative methods using LLMs as judges, such as AlpacaEval, MT Bench, WildBench, and InFoBench offer improvements but still do not capture that certain complex instruction aspects are more important than others to follow. To address this gap, we propose a novel evaluation metric, \textsc{TOWER}, that incorporates human-judged importance into the assessment of complex instruction following. We show that human annotators agree with tree-based representations of these complex instructions nearly as much as they agree with other human annotators. We release tree-based annotations of the InFoBench dataset and the corresponding evaluation code to facilitate future research.
Explaining Tree Model Decisions in Natural Language for Network Intrusion Detection
Oct 30, 2023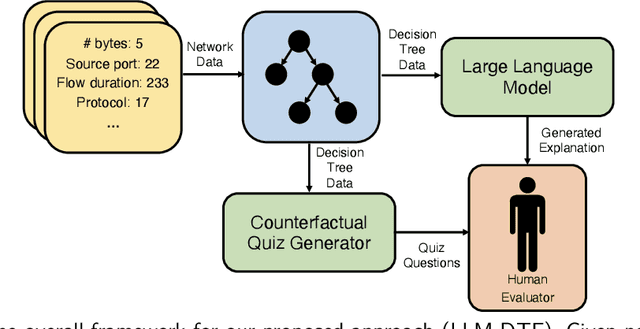

Network intrusion detection (NID) systems which leverage machine learning have been shown to have strong performance in practice when used to detect malicious network traffic. Decision trees in particular offer a strong balance between performance and simplicity, but require users of NID systems to have background knowledge in machine learning to interpret. In addition, they are unable to provide additional outside information as to why certain features may be important for classification. In this work, we explore the use of large language models (LLMs) to provide explanations and additional background knowledge for decision tree NID systems. Further, we introduce a new human evaluation framework for decision tree explanations, which leverages automatically generated quiz questions that measure human evaluators' understanding of decision tree inference. Finally, we show LLM generated decision tree explanations correlate highly with human ratings of readability, quality, and use of background knowledge while simultaneously providing better understanding of decision boundaries.
Embedding Mental Health Discourse for Community Recommendation
Jul 08, 2023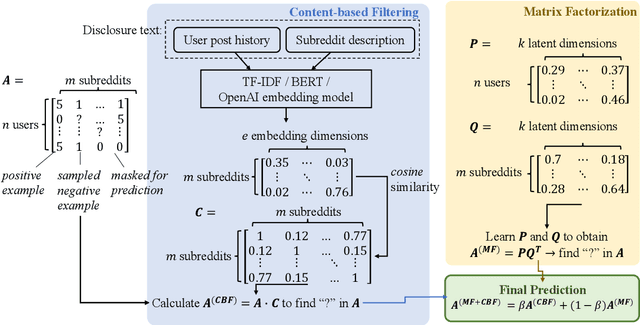
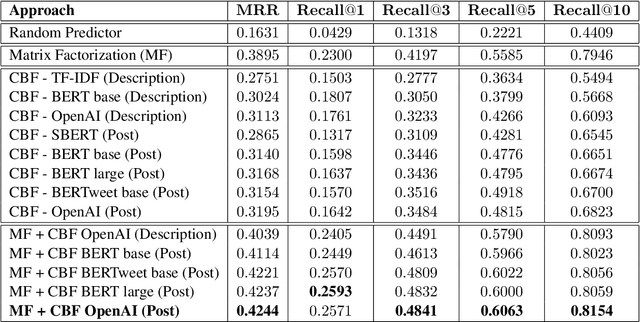
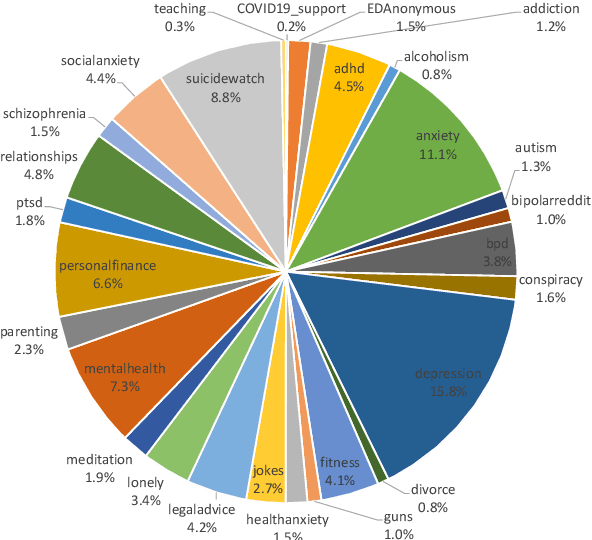
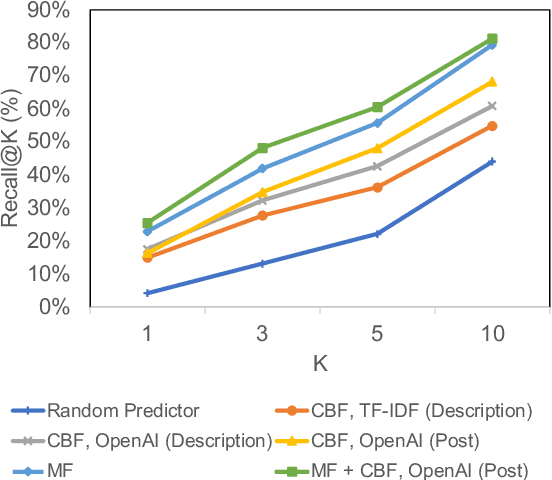
Our paper investigates the use of discourse embedding techniques to develop a community recommendation system that focuses on mental health support groups on social media. Social media platforms provide a means for users to anonymously connect with communities that cater to their specific interests. However, with the vast number of online communities available, users may face difficulties in identifying relevant groups to address their mental health concerns. To address this challenge, we explore the integration of discourse information from various subreddit communities using embedding techniques to develop an effective recommendation system. Our approach involves the use of content-based and collaborative filtering techniques to enhance the performance of the recommendation system. Our findings indicate that the proposed approach outperforms the use of each technique separately and provides interpretability in the recommendation process.
Large Language Models are Built-in Autoregressive Search Engines
May 16, 2023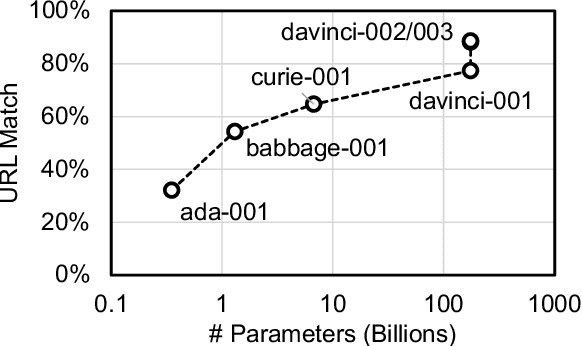
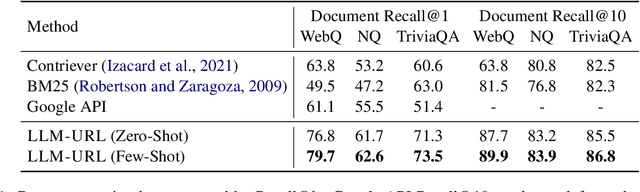
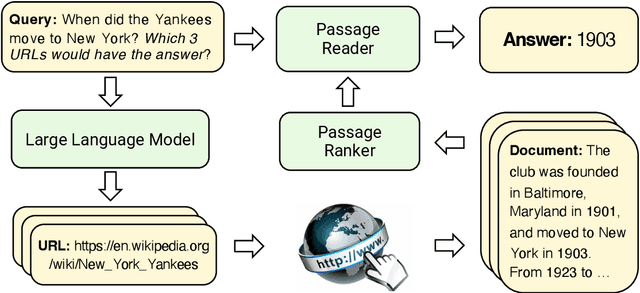
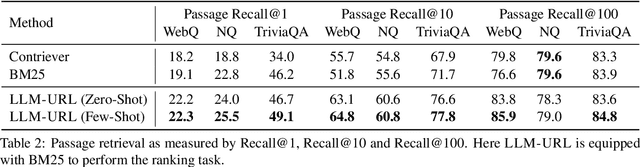
Document retrieval is a key stage of standard Web search engines. Existing dual-encoder dense retrievers obtain representations for questions and documents independently, allowing for only shallow interactions between them. To overcome this limitation, recent autoregressive search engines replace the dual-encoder architecture by directly generating identifiers for relevant documents in the candidate pool. However, the training cost of such autoregressive search engines rises sharply as the number of candidate documents increases. In this paper, we find that large language models (LLMs) can follow human instructions to directly generate URLs for document retrieval. Surprisingly, when providing a few {Query-URL} pairs as in-context demonstrations, LLMs can generate Web URLs where nearly 90\% of the corresponding documents contain correct answers to open-domain questions. In this way, LLMs can be thought of as built-in search engines, since they have not been explicitly trained to map questions to document identifiers. Experiments demonstrate that our method can consistently achieve better retrieval performance than existing retrieval approaches by a significant margin on three open-domain question answering benchmarks, under both zero and few-shot settings. The code for this work can be found at \url{https://github.com/Ziems/llm-url}.
CodeDSI: Differentiable Code Search
Oct 01, 2022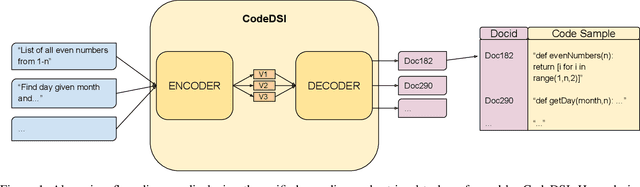
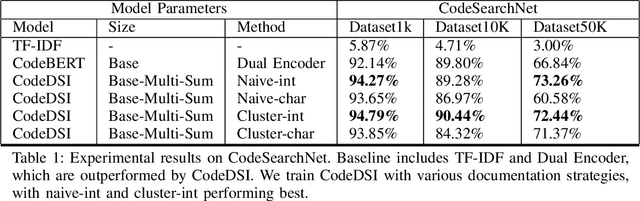
Reimplementing solutions to previously solved software engineering problems is not only inefficient but also introduces inadequate and error-prone code. Many existing methods achieve impressive performance on this issue by using autoregressive text-generation models trained on code. However, these methods are not without their flaws. The generated code from these models can be buggy, lack documentation, and introduce vulnerabilities that may go unnoticed by developers. An alternative to code generation -- neural code search -- is a field of machine learning where a model takes natural language queries as input and, in turn, relevant code samples from a database are returned. Due to the nature of this pre-existing database, code samples can be documented, tested, licensed, and checked for vulnerabilities before being used by developers in production. In this work, we present CodeDSI, an end-to-end unified approach to code search. CodeDSI is trained to directly map natural language queries to their respective code samples, which can be retrieved later. In an effort to improve the performance of code search, we have investigated docid representation strategies, impact of tokenization on docid structure, and dataset sizes on overall code search performance. Our results demonstrate CodeDSI strong performance, exceeding conventional robust baselines by 2-6% across varying dataset sizes.
Security Vulnerability Detection Using Deep Learning Natural Language Processing
May 06, 2021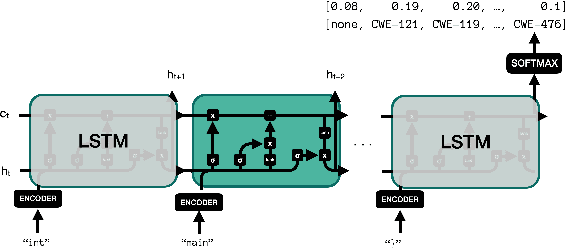
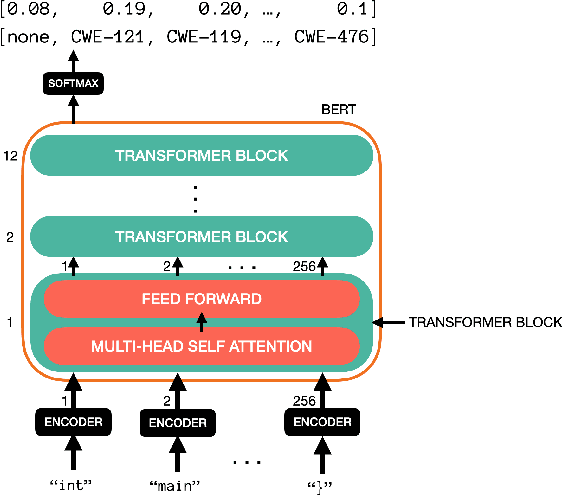
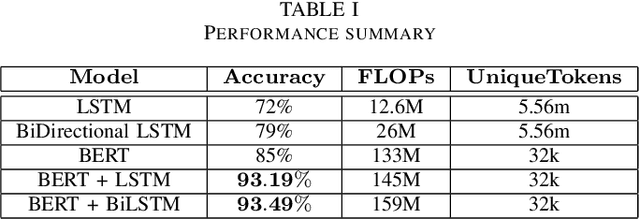
Detecting security vulnerabilities in software before they are exploited has been a challenging problem for decades. Traditional code analysis methods have been proposed, but are often ineffective and inefficient. In this work, we model software vulnerability detection as a natural language processing (NLP) problem with source code treated as texts, and address the automated software venerability detection with recent advanced deep learning NLP models assisted by transfer learning on written English. For training and testing, we have preprocessed the NIST NVD/SARD databases and built a dataset of over 100,000 files in $C$ programming language with 123 types of vulnerabilities. The extensive experiments generate the best performance of over 93\% accuracy in detecting security vulnerabilities.
Automated Primary Hyperparathyroidism Screening with Neural Networks
May 06, 2021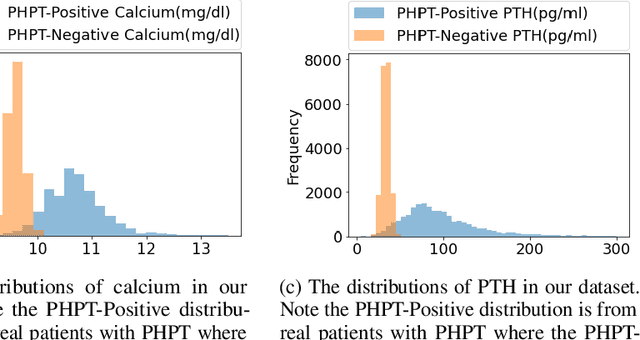
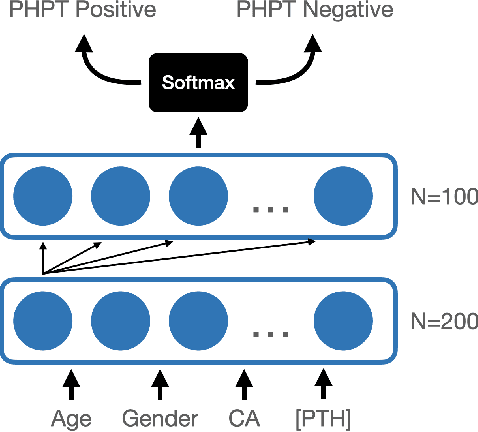
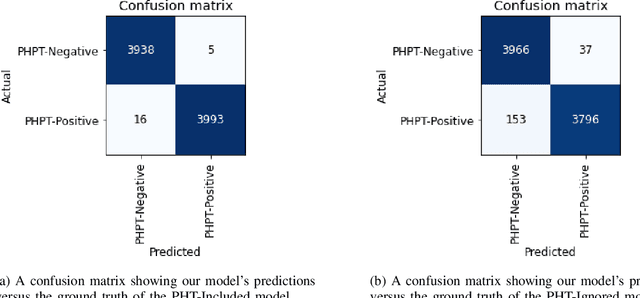
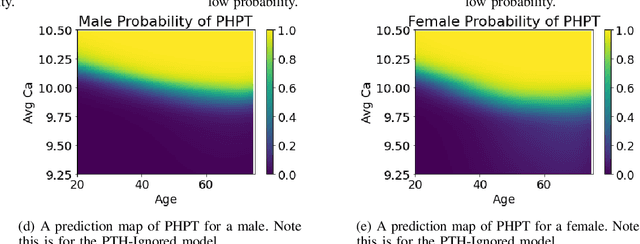
Primary Hyperparathyroidism(PHPT) is a relatively common disease, affecting about one in every 1,000 adults. However, screening for PHPT can be difficult, meaning it often goes undiagnosed for long periods of time. While looking at specific blood test results independently can help indicate whether a patient has PHPT, often these blood result levels can all be within their respective normal ranges despite the patient having PHPT. Based on the clinic data from the real world, in this work, we propose a novel approach to screening PHPT with neural network (NN) architecture, achieving over 97\% accuracy with common blood values as inputs. Further, we propose a second model achieving over 99\% accuracy with additional lab test values as inputs. Moreover, compared to traditional PHPT screening methods, our NN models can reduce the false negatives of traditional screening methods by 99\%.