 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeDSI: Differentiable Code Search
Oct 01, 2022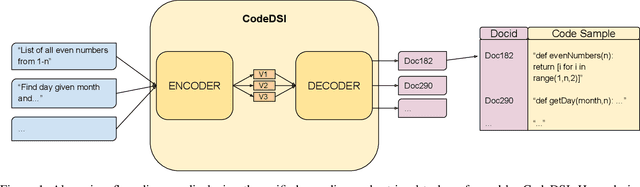
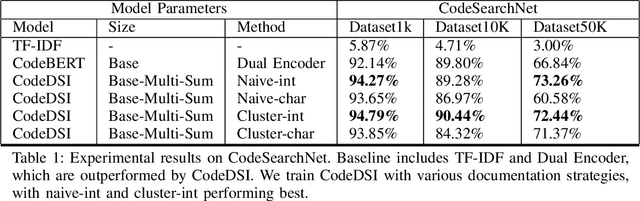
Reimplementing solutions to previously solved software engineering problems is not only inefficient but also introduces inadequate and error-prone code. Many existing methods achieve impressive performance on this issue by using autoregressive text-generation models trained on code. However, these methods are not without their flaws. The generated code from these models can be buggy, lack documentation, and introduce vulnerabilities that may go unnoticed by developers. An alternative to code generation -- neural code search -- is a field of machine learning where a model takes natural language queries as input and, in turn, relevant code samples from a database are returned. Due to the nature of this pre-existing database, code samples can be documented, tested, licensed, and checked for vulnerabilities before being used by developers in production. In this work, we present CodeDSI, an end-to-end unified approach to code search. CodeDSI is trained to directly map natural language queries to their respective code samples, which can be retrieved later. In an effort to improve the performance of code search, we have investigated docid representation strategies, impact of tokenization on docid structure, and dataset sizes on overall code search performance. Our results demonstrate CodeDSI strong performance, exceeding conventional robust baselines by 2-6% across varying dataset sizes.