 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnapPix: Efficient-Coding--Inspired In-Sensor Compression for Edge Vision
Apr 06, 2025Energy-efficient image acquisition on the edge is crucial for enabling remote sensing applications where the sensor node has weak compute capabilities and must transmit data to a remote server/cloud for processing. To reduce the edge energy consumption, this paper proposes a sensor-algorithm co-designed system called SnapPix, which compresses raw pixels in the analog domain inside the sensor. We use coded exposure (CE) as the in-sensor compression strategy as it offers the flexibility to sample, i.e., selectively expose pixels, both spatially and temporally. SNAPPIX has three contributions. First, we propose a task-agnostic strategy to learn the sampling/exposure pattern based on the classic theory of efficient coding. Second, we co-design the downstream vision model with the exposure pattern to address the pixel-level non-uniformity unique to CE-compressed images. Finally, we propose lightweight augmentations to the image sensor hardware to support our in-sensor CE compression. Evaluating on action recognition and video reconstruction, SnapPix outperforms state-of-the-art video-based methods at the same speed while reducing the energy by up to 15.4x. We have open-sourced the code at: https://github.com/horizon-research/SnapPix.
CORE4D: A 4D Human-Object-Human Interaction Dataset for Collaborative Object REarrangement
Jun 27, 2024Understanding how humans cooperatively rearrange household objects is critical for VR/AR and human-robot interaction. However, in-depth studies on modeling these behaviors are under-researched due to the lack of relevant datasets. We fill this gap by presenting CORE4D, a novel large-scale 4D human-object-human interaction dataset focusing on collaborative object rearrangement, which encompasses diverse compositions of various object geometries, collaboration modes, and 3D scenes. With 1K human-object-human motion sequences captured in the real world, we enrich CORE4D by contributing an iterative collaboration retargeting strategy to augment motions to a variety of novel objects. Leveraging this approach, CORE4D comprises a total of 11K collaboration sequences spanning 3K real and virtual object shapes. Benefiting from extensive motion patterns provided by CORE4D, we benchmark two tasks aiming at generating human-object interaction: human-object motion forecasting and interaction synthesis. Extensive experiments demonstrate the effectiveness of our collaboration retargeting strategy and indicate that CORE4D has posed new challenges to existing human-object interaction generation methodologies. Our dataset and code are available at https://github.com/leolyliu/CORE4D-Instructions.
Fast Learning Radiance Fields by Shooting Much Fewer Rays
Aug 14, 2022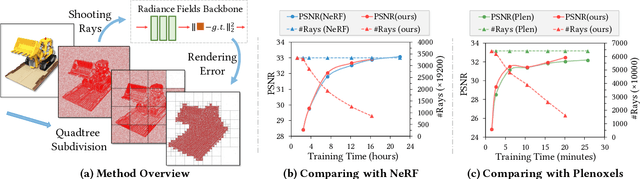


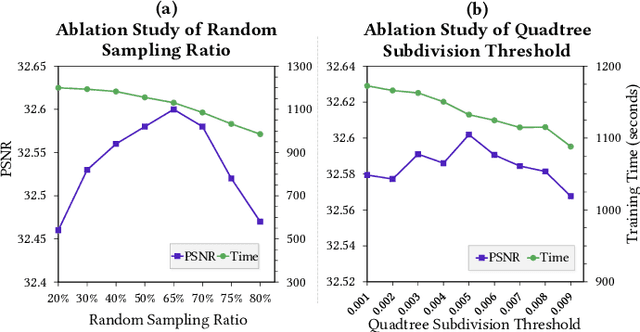
Learning radiance fields has shown remarkable results for novel view synthesis. The learning procedure usually costs lots of time, which motivates the latest methods to speed up the learning procedure by learning without neural networks or using more efficient data structures. However, these specially designed approaches do not work for most of radiance fields based methods. To resolve this issue, we introduce a general strategy to speed up the learning procedure for almost all radiance fields based methods. Our key idea is to reduce the redundancy by shooting much fewer rays in the multi-view volume rendering procedure which is the base for almost all radiance fields based methods. We find that shooting rays at pixels with dramatic color change not only significantly reduces the training burden but also barely affects the accuracy of the learned radiance fields. In addition, we also adaptively subdivide each view into a quadtree according to the average rendering error in each node in the tree, which makes us dynamically shoot more rays in more complex regions with larger rendering error. We evaluate our method with different radiance fields based methods under the widely used benchmarks. Experimental results show that our method achieves comparable accuracy to the state-of-the-art with much faster training.