 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference time LLM alignment in single and multidomain preference spectrum
Oct 24, 2024
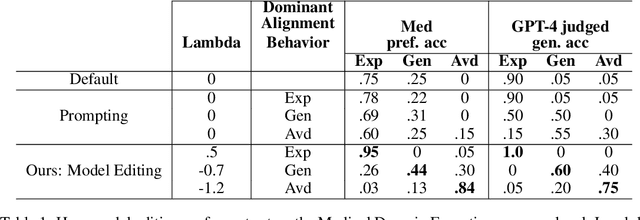
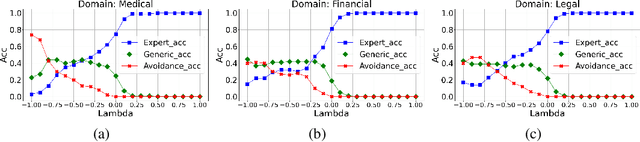
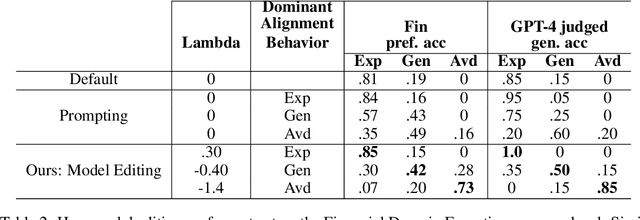
Aligning Large Language Models (LLM) to address subjectivity and nuanced preference levels requires adequate flexibility and control, which can be a resource-intensive and time-consuming procedure. Existing training-time alignment methods require full re-training when a change is needed and inference-time ones typically require access to the reward model at each inference step. To address these limitations, we introduce inference-time model alignment method that learns encoded representations of preference dimensions, called \textit{Alignment Vectors} (AV). These representations are computed by subtraction of the base model from the aligned model as in model editing enabling dynamically adjusting the model behavior during inference through simple linear operations. Even though the preference dimensions can span various granularity levels, here we focus on three gradual response levels across three specialized domains: medical, legal, and financial, exemplifying its practical potential. This new alignment paradigm introduces adjustable preference knobs during inference, allowing users to tailor their LLM outputs while reducing the inference cost by half compared to the prompt engineering approach. Additionally, we find that AVs are transferable across different fine-tuning stages of the same model, demonstrating their flexibility. AVs also facilitate multidomain, diverse preference alignment, making the process 12x faster than the retraining approach.
Seeing Through AI's Lens: Enhancing Human Skepticism Towards LLM-Generated Fake News
Jun 20, 2024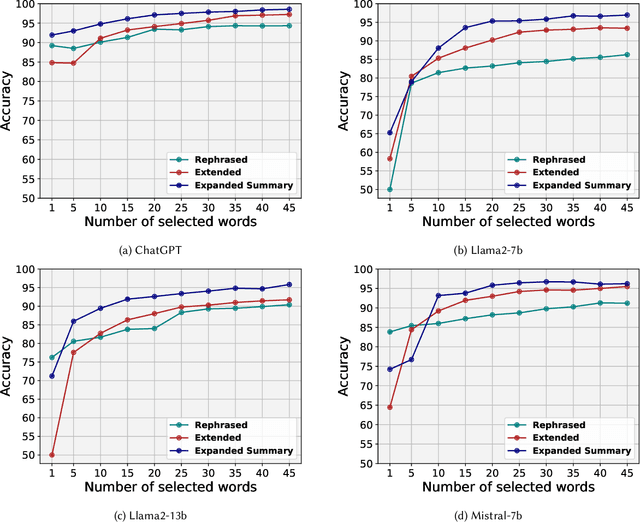


LLMs offer valuable capabilities, yet they can be utilized by malicious users to disseminate deceptive information and generate fake news. The growing prevalence of LLMs poses difficulties in crafting detection approaches that remain effective across various text domains. Additionally, the absence of precautionary measures for AI-generated news on online social platforms is concerning. Therefore, there is an urgent need to improve people's ability to differentiate between news articles written by humans and those produced by LLMs. By providing cues in human-written and LLM-generated news, we can help individuals increase their skepticism towards fake LLM-generated news. This paper aims to elucidate simple markers that help individuals distinguish between articles penned by humans and those created by LLMs. To achieve this, we initially collected a dataset comprising 39k news articles authored by humans or generated by four distinct LLMs with varying degrees of fake. We then devise a metric named Entropy-Shift Authorship Signature (ESAS) based on the information theory and entropy principles. The proposed ESAS ranks terms or entities, like POS tagging, within news articles based on their relevance in discerning article authorship. We demonstrate the effectiveness of our metric by showing the high accuracy attained by a basic method, i.e., TF-IDF combined with logistic regression classifier, using a small set of terms with the highest ESAS score. Consequently, we introduce and scrutinize these top ESAS-ranked terms to aid individuals in strengthening their skepticism towards LLM-generated fake news.
HU at SemEval-2024 Task 8A: Can Contrastive Learning Learn Embeddings to Detect Machine-Generated Text?
Feb 19, 2024

This paper describes our system developed for SemEval-2024 Task 8, "Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection." Machine-generated texts have been one of the main concerns due to the use of large language models (LLM) in fake text generation, phishing, cheating in exams, or even plagiarizing copyright materials. A lot of systems have been developed to detect machine-generated text. Nonetheless, the majority of these systems rely on the text-generating model, a limitation that is impractical in real-world scenarios, as it's often impossible to know which specific model the user has used for text generation. In this work, we propose a single model based on contrastive learning, which uses ~40% of the baseline's parameters (149M vs. 355M) but shows a comparable performance on the test dataset (21st out of 137 participants). Our key finding is that even without an ensemble of multiple models, a single base model can have comparable performance with the help of data augmentation and contrastive learning.
The Looming Threat of Fake and LLM-generated LinkedIn Profiles: Challenges and Opportunities for Detection and Prevention
Jul 21, 2023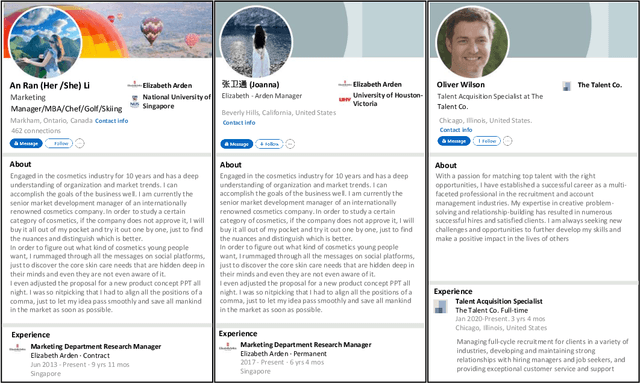

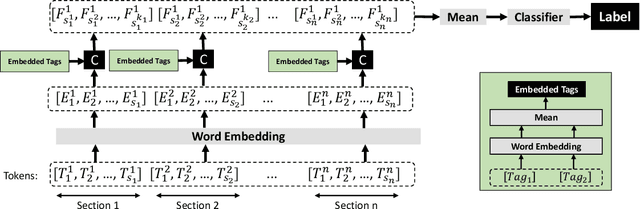

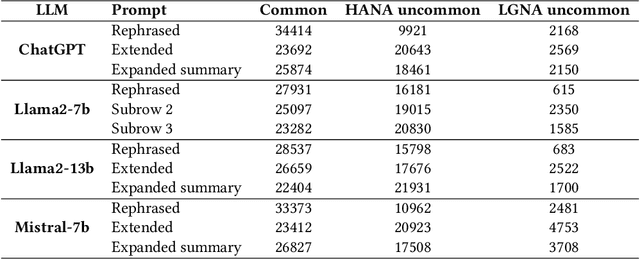
In this paper, we present a novel method for detecting fake and Large Language Model (LLM)-generated profiles in the LinkedIn Online Social Network immediately upon registration and before establishing connections. Early fake profile identification is crucial to maintaining the platform's integrity since it prevents imposters from acquiring the private and sensitive information of legitimate users and from gaining an opportunity to increase their credibility for future phishing and scamming activities. This work uses textual information provided in LinkedIn profiles and introduces the Section and Subsection Tag Embedding (SSTE) method to enhance the discriminative characteristics of these data for distinguishing between legitimate profiles and those created by imposters manually or by using an LLM. Additionally, the dearth of a large publicly available LinkedIn dataset motivated us to collect 3600 LinkedIn profiles for our research. We will release our dataset publicly for research purposes. This is, to the best of our knowledge, the first large publicly available LinkedIn dataset for fake LinkedIn account detection. Within our paradigm, we assess static and contextualized word embeddings, including GloVe, Flair, BERT, and RoBERTa. We show that the suggested method can distinguish between legitimate and fake profiles with an accuracy of about 95% across all word embeddings. In addition, we show that SSTE has a promising accuracy for identifying LLM-generated profiles, despite the fact that no LLM-generated profiles were employed during the training phase, and can achieve an accuracy of approximately 90% when only 20 LLM-generated profiles are added to the training set. It is a significant finding since the proliferation of several LLMs in the near future makes it extremely challenging to design a single system that can identify profiles created with various LLMs.
SafeWebUH at SemEval-2023 Task 11: Learning Annotator Disagreement in Derogatory Text: Comparison of Direct Training vs Aggregation
May 01, 2023

Subjectivity and difference of opinion are key social phenomena, and it is crucial to take these into account in the annotation and detection process of derogatory textual content. In this paper, we use four datasets provided by SemEval-2023 Task 11 and fine-tune a BERT model to capture the disagreement in the annotation. We find individual annotator modeling and aggregation lowers the Cross-Entropy score by an average of 0.21, compared to the direct training on the soft labels. Our findings further demonstrate that annotator metadata contributes to the average 0.029 reduction in the Cross-Entropy score.
Deception Detection with Feature-Augmentation by soft Domain Transfer
May 01, 2023In this era of information explosion, deceivers use different domains or mediums of information to exploit the users, such as News, Emails, and Tweets. Although numerous research has been done to detect deception in all these domains, information shortage in a new event necessitates these domains to associate with each other to battle deception. To form this association, we propose a feature augmentation method by harnessing the intermediate layer representation of neural models. Our approaches provide an improvement over the self-domain baseline models by up to 6.60%. We find Tweets to be the most helpful information provider for Fake News and Phishing Email detection, whereas News helps most in Tweet Rumor detection. Our analysis provides a useful insight for domain knowledge transfer which can help build a stronger deception detection system than the existing literature.