 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARE-RL: Capability-Aware Reinforcement Learning for Mitigating Cross-Domain Conflicts
May 30, 2026Reinforcement learning (RL) with verifiable rewards has achieved strong progress in reasoning-oriented LLMs, but extending it to multi-domain RL remains challenging due to reward unreliability in non-verifiable tasks and capability interference across domains. We propose CARE-RL to combine protocol-aware reward generation with capability-aware optimization for mitigating cross-domain conflicts. For non-verifiable tasks, the Protocol-Aware Generative Reward Model (PA-GRM) constructs prompt-level evaluation protocols and schemas before producing trace-conditioned rewards, enabling task-adaptive yet comparable evaluation of open-ended responses. For multi-domain optimization, Direction-Aware Capability Subspace Projection (DACSP) extracts historical capability directions from previous RL stages and modulates later updates by amplifying aligned components, suppressing conflicting components, and preserving orthogonal updates. Experiments across math, chat, and instruction-following benchmarks show that CARE-RL consistently outperforms standard multi-domain RL baselines, achieving Total Avg scores of 47.9 and 50.7 on Qwen2.5-7B and Qwen3-4B, respectively.
Planner-Centric Reinforcement Learning for Deep Research with Structure-Aware Reward
May 29, 2026Deep research tasks require LLMs to plan what to investigate, retrieve evidence, and synthesize long-form answers across multiple branches of inquiry. Existing training paradigms either rely on short-form verifiable QA as a proxy or optimize monolithic long trajectories, which makes planning and execution difficult to disentangle and yields weak credit assignment for the planning process. We propose DecomposeR, a planner-centric deep research framework that represents research plans as typed directed acyclic graphs (DAGs), allowing planning to be made explicit, structured, and rewardable. We train a Qwen3-8B model in two stages: planner reinforcement learning (RL) first learns graph structure and query decomposition to improve research planning, and answerer reinforcement learning (RL) then learns branch-level execution and final synthesis conditioned on the learned plan. By assigning rewards to explicit planner tokens and structured components rather than to a flat trajectory, DecomposeR enables finer-grained optimization of planning while reducing the ambiguity of end-to-end training. Experiments show that DecomposeR-8B improves over strong comparable open baselines by 5.1-8.0 points on popular long-form benchmarks due to improved planning and answering capabilities.
Automatic Configuration of LLM Post-Training Pipelines
Mar 19, 2026LLM post-training pipelines that combine supervised fine-tuning and reinforcement learning are difficult to configure under realistic compute budgets: the configuration space is high-dimensional and heterogeneous, stages are strongly coupled, and each end-to-end evaluation is expensive. We propose AutoPipe, a budget-aware two-stage framework for configuration selection in LLM post-training. Offline, AutoPipe learns a dataset-conditioned learning-to-rank surrogate from historical runs, capturing within-dataset preferences and providing transferable guidance toward promising regions of the configuration space. Online, for a new dataset, AutoPipe uses the offline guidance to steer Bayesian optimization and models dataset-specific deviations with a Gaussian-process residual surrogate. To reduce evaluation cost, each trial is early-stopped and scored by a learned predictor that maps early training signals to a low-cost proxy for final post-training performance. Experiments on biomedical reasoning tasks show that AutoPipe consistently outperforms offline-only baselines and achieves comparable performance with the strongest online HPO baselines while using less than 10\% of their computational cost.
Towards Autonomous Memory Agents
Feb 25, 2026Recent memory agents improve LLMs by extracting experiences and conversation history into an external storage. This enables low-overhead context assembly and online memory update without expensive LLM training. However, existing solutions remain passive and reactive; memory growth is bounded by information that happens to be available, while memory agents seldom seek external inputs in uncertainties. We propose autonomous memory agents that actively acquire, validate, and curate knowledge at a minimum cost. U-Mem materializes this idea via (i) a cost-aware knowledge-extraction cascade that escalates from cheap self/teacher signals to tool-verified research and, only when needed, expert feedback, and (ii) semantic-aware Thompson sampling to balance exploration and exploitation over memories and mitigate cold-start bias. On both verifiable and non-verifiable benchmarks, U-Mem consistently beats prior memory baselines and can surpass RL-based optimization, improving HotpotQA (Qwen2.5-7B) by 14.6 points and AIME25 (Gemini-2.5-flash) by 7.33 points.
AutoPINN: When AutoML Meets Physics-Informed Neural Networks
Dec 08, 2022

Physics-Informed Neural Networks (PINNs) have recently been proposed to solve scientific and engineering problems, where physical laws are introduced into neural networks as prior knowledge. With the embedded physical laws, PINNs enable the estimation of critical parameters, which are unobservable via physical tools, through observable variables. For example, Power Electronic Converters (PECs) are essential building blocks for the green energy transition. PINNs have been applied to estimate the capacitance, which is unobservable during PEC operations, using current and voltage, which can be observed easily during operations. The estimated capacitance facilitates self-diagnostics of PECs. Existing PINNs are often manually designed, which is time-consuming and may lead to suboptimal performance due to a large number of design choices for neural network architectures and hyperparameters. In addition, PINNs are often deployed on different physical devices, e.g., PECs, with limited and varying resources. Therefore, it requires designing different PINN models under different resource constraints, making it an even more challenging task for manual design. To contend with the challenges, we propose Automated Physics-Informed Neural Networks (AutoPINN), a framework that enables the automated design of PINNs by combining AutoML and PINNs. Specifically, we first tailor a search space that allows finding high-accuracy PINNs for PEC internal parameter estimation. We then propose a resource-aware search strategy to explore the search space to find the best PINN model under different resource constraints. We experimentally demonstrate that AutoPINN is able to find more accurate PINN models than human-designed, state-of-the-art PINN models using fewer resources.
Joint Neural Architecture and Hyperparameter Search for Correlated Time Series Forecasting
Nov 29, 2022Sensors in cyber-physical systems often capture interconnected processes and thus emit correlated time series (CTS), the forecasting of which enables important applications. The key to successful CTS forecasting is to uncover the temporal dynamics of time series and the spatial correlations among time series. Deep learning-based solutions exhibit impressive performance at discerning these aspects. In particular, automated CTS forecasting, where the design of an optimal deep learning architecture is automated, enables forecasting accuracy that surpasses what has been achieved by manual approaches. However, automated CTS solutions remain in their infancy and are only able to find optimal architectures for predefined hyperparameters and scale poorly to large-scale CTS. To overcome these limitations, we propose SEARCH, a joint, scalable framework, to automatically devise effective CTS forecasting models. Specifically, we encode each candidate architecture and accompanying hyperparameters into a joint graph representation. We introduce an efficient Architecture-Hyperparameter Comparator (AHC) to rank all architecture-hyperparameter pairs, and we then further evaluate the top-ranked pairs to select a final result. Extensive experiments on six benchmark datasets demonstrate that SEARCH not only eliminates manual efforts but also is capable of better performance than manually designed and existing automatically designed CTS models. In addition, it shows excellent scalability to large CTS.
AutoCTS: Automated Correlated Time Series Forecasting -- Extended Version
Dec 21, 2021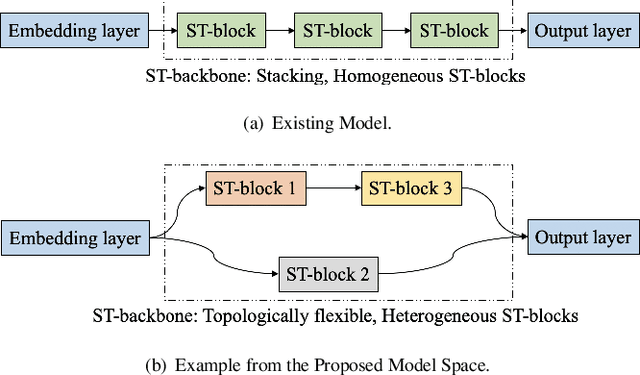
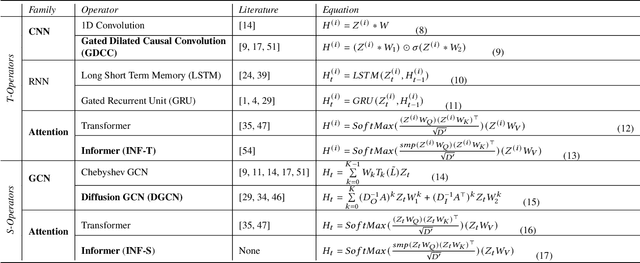
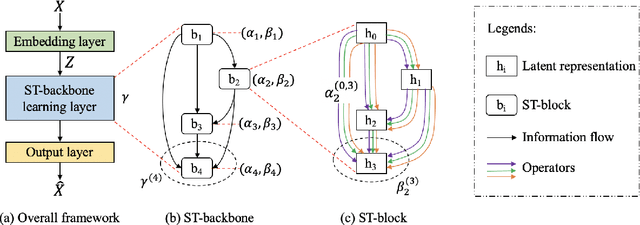

Correlated time series (CTS) forecasting plays an essential role in many cyber-physical systems, where multiple sensors emit time series that capture interconnected processes. Solutions based on deep learning that deliver state-of-the-art CTS forecasting performance employ a variety of spatio-temporal (ST) blocks that are able to model temporal dependencies and spatial correlations among time series. However, two challenges remain. First, ST-blocks are designed manually, which is time consuming and costly. Second, existing forecasting models simply stack the same ST-blocks multiple times, which limits the model potential. To address these challenges, we propose AutoCTS that is able to automatically identify highly competitive ST-blocks as well as forecasting models with heterogeneous ST-blocks connected using diverse topologies, as opposed to the same ST-blocks connected using simple stacking. Specifically, we design both a micro and a macro search space to model possible architectures of ST-blocks and the connections among heterogeneous ST-blocks, and we provide a search strategy that is able to jointly explore the search spaces to identify optimal forecasting models. Extensive experiments on eight commonly used CTS forecasting benchmark datasets justify our design choices and demonstrate that AutoCTS is capable of automatically discovering forecasting models that outperform state-of-the-art human-designed models. This is an extended version of ``AutoCTS: Automated Correlated Time Series Forecasting'', to appear in PVLDB 2022.