 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-BERT: Learning Better Tabular Representations Through Cross-Table Pre-training
Paper and Code


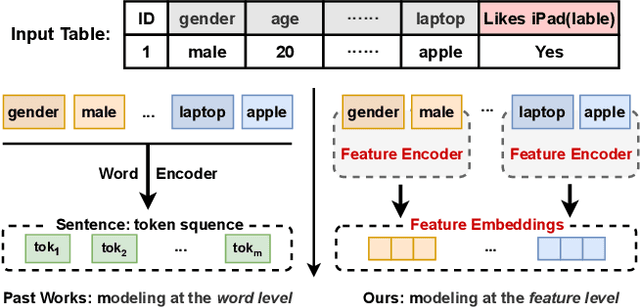
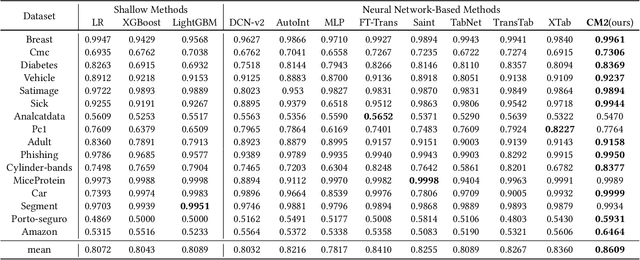
Tabular data -- also known as structured data -- is one of the most common data forms in existence, thanks to the stable development and scaled deployment of database systems in the last few decades. At present however, despite the blast brought by large pre-trained models in other domains such as ChatGPT or SAM, how can we extract common knowledge across tables at a scale that may eventually lead to generalizable representation for tabular data remains a full blank. Indeed, there have been a few works around this topic. Most (if not all) of them are limited in the scope of a single table or fixed form of a schema. In this work, we first identify the crucial research challenges behind tabular data pre-training, particularly towards the cross-table scenario. We position the contribution of this work in two folds: (i)-we collect and curate nearly 2k high-quality tabular datasets, each of which is guaranteed to possess clear semantics, clean labels, and other necessary meta information. (ii)-we propose a novel framework that allows cross-table pre-training dubbed as CT-BERT. Noticeably, in light of pioneering the scaled cross-table training, CT-BERT is fully compatible with both supervised and self-supervised schemes, where the specific instantiation of CT-BERT is very much dependent on the downstream tasks. We further propose and implement a contrastive-learning-based and masked table modeling (MTM) objective into CT-BERT, that is inspired from computer vision and natural language processing communities but sophistically tailored to tables. The extensive empirical results on 15 datasets demonstrate CT-BERT's state-of-the-art performance, where both its supervised and self-supervised setups significantly outperform the prior approaches.