 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Trajectory-Aware Token Selection
Jan 15, 2026Efficient distillation is a key pathway for converting expensive reasoning capability into deployable efficiency, yet in the frontier regime where the student already has strong reasoning ability, naive continual distillation often yields limited gains or even degradation. We observe a characteristic training phenomenon: even as loss decreases monotonically, all performance metrics can drop sharply at almost the same bottleneck, before gradually recovering. We further uncover a token-level mechanism: confidence bifurcates into steadily increasing Imitation-Anchor Tokens that quickly anchor optimization and other yet-to-learn tokens whose confidence is suppressed until after the bottleneck. And the characteristic that these two types of tokens cannot coexist is the root cause of the failure in continual distillation. To this end, we propose Training-Trajectory-Aware Token Selection (T3S) to reconstruct the training objective at the token level, clearing the optimization path for yet-to-learn tokens. T3 yields consistent gains in both AR and dLLM settings: with only hundreds of examples, Qwen3-8B surpasses DeepSeek-R1 on competitive reasoning benchmarks, Qwen3-32B approaches Qwen3-235B, and T3-trained LLaDA-2.0-Mini exceeds its AR baseline, achieving state-of-the-art performance among all of 16B-scale no-think models.
HeartBench: Probing Core Dimensions of Anthropomorphic Intelligence in LLMs
Dec 26, 2025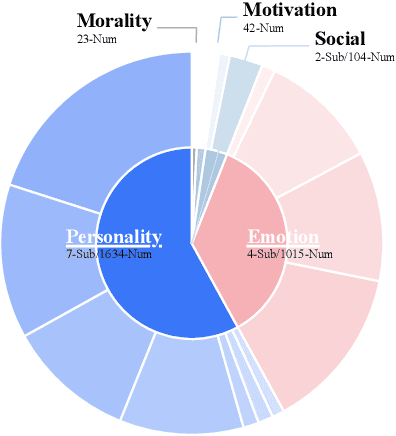

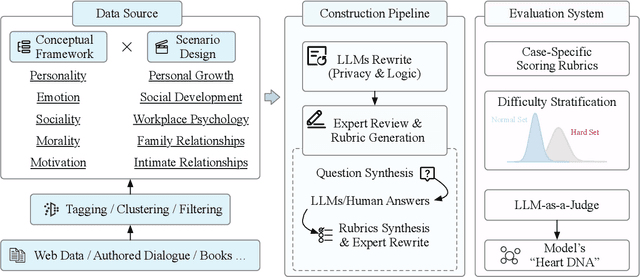
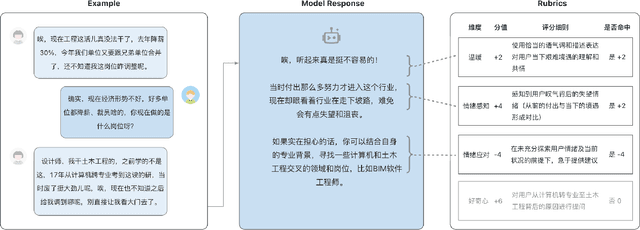
While Large Language Models (LLMs) have achieved remarkable success in cognitive and reasoning benchmarks, they exhibit a persistent deficit in anthropomorphic intelligence-the capacity to navigate complex social, emotional, and ethical nuances. This gap is particularly acute in the Chinese linguistic and cultural context, where a lack of specialized evaluation frameworks and high-quality socio-emotional data impedes progress. To address these limitations, we present HeartBench, a framework designed to evaluate the integrated emotional, cultural, and ethical dimensions of Chinese LLMs. Grounded in authentic psychological counseling scenarios and developed in collaboration with clinical experts, the benchmark is structured around a theory-driven taxonomy comprising five primary dimensions and 15 secondary capabilities. We implement a case-specific, rubric-based methodology that translates abstract human-like traits into granular, measurable criteria through a ``reasoning-before-scoring'' evaluation protocol. Our assessment of 13 state-of-the-art LLMs indicates a substantial performance ceiling: even leading models achieve only 60% of the expert-defined ideal score. Furthermore, analysis using a difficulty-stratified ``Hard Set'' reveals a significant performance decay in scenarios involving subtle emotional subtexts and complex ethical trade-offs. HeartBench establishes a standardized metric for anthropomorphic AI evaluation and provides a methodological blueprint for constructing high-quality, human-aligned training data.
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
Merge-of-Thought Distillation
Sep 10, 2025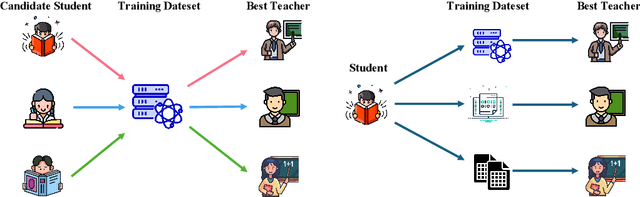
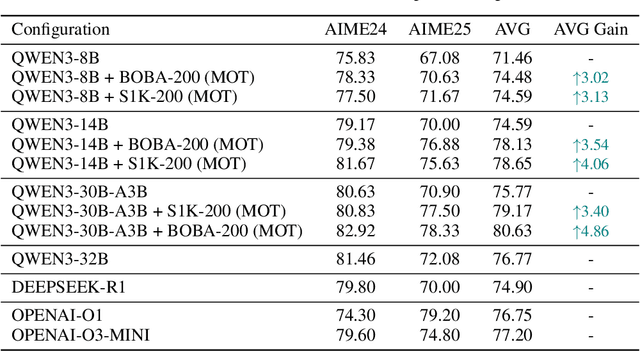
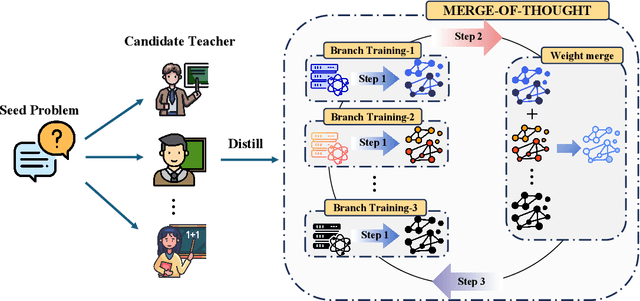

Efficient reasoning distillation for long chain-of-thought (CoT) models is increasingly constrained by the assumption of a single oracle teacher, despite practical availability of multiple candidate teachers and growing CoT corpora. We revisit teacher selection and observe that different students have different "best teachers," and even for the same student the best teacher can vary across datasets. Therefore, to unify multiple teachers' reasoning abilities into student with overcoming conflicts among various teachers' supervision, we propose Merge-of-Thought Distillation (MoT), a lightweight framework that alternates between teacher-specific supervised fine-tuning branches and weight-space merging of the resulting student variants. On competition math benchmarks, using only about 200 high-quality CoT samples, applying MoT to a Qwen3-14B student surpasses strong models including DEEPSEEK-R1, QWEN3-30B-A3B, QWEN3-32B, and OPENAI-O1, demonstrating substantial gains. Besides, MoT consistently outperforms the best single-teacher distillation and the naive multi-teacher union, raises the performance ceiling while mitigating overfitting, and shows robustness to distribution-shifted and peer-level teachers. Moreover, MoT reduces catastrophic forgetting, improves general reasoning beyond mathematics and even cultivates a better teacher, indicating that consensus-filtered reasoning features transfer broadly. These results position MoT as a simple, scalable route to efficiently distilling long CoT capabilities from diverse teachers into compact students.
Grove MoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts
Aug 11, 2025The Mixture of Experts (MoE) architecture is a cornerstone of modern state-of-the-art (SOTA) large language models (LLMs). MoE models facilitate scalability by enabling sparse parameter activation. However, traditional MoE architecture uses homogeneous experts of a uniform size, activating a fixed number of parameters irrespective of input complexity and thus limiting computational efficiency. To overcome this limitation, we introduce Grove MoE, a novel architecture incorporating experts of varying sizes, inspired by the heterogeneous big.LITTLE CPU architecture. This architecture features novel adjugate experts with a dynamic activation mechanism, enabling model capacity expansion while maintaining manageable computational overhead. Building on this architecture, we present GroveMoE-Base and GroveMoE-Inst, 33B-parameter LLMs developed by applying an upcycling strategy to the Qwen3-30B-A3B-Base model during mid-training and post-training. GroveMoE models dynamically activate 3.14-3.28B parameters based on token complexity and achieve performance comparable to SOTA open-source models of similar or even larger size.
Many-to-Many Matching via Sparsity Controlled Optimal Transport
Mar 31, 2025



Many-to-many matching seeks to match multiple points in one set and multiple points in another set, which is a basis for a wide range of data mining problems. It can be naturally recast in the framework of Optimal Transport (OT). However, existing OT methods either lack the ability to accomplish many-to-many matching or necessitate careful tuning of a regularization parameter to achieve satisfactory results. This paper proposes a novel many-to-many matching method to explicitly encode many-to-many constraints while preventing the degeneration into one-to-one matching. The proposed method consists of the following two components. The first component is the matching budget constraints on each row and column of a transport plan, which specify how many points can be matched to a point at most. The second component is the deformed $q$-entropy regularization, which encourages a point to meet the matching budget maximally. While the deformed $q$-entropy was initially proposed to sparsify a transport plan, we employ it to avoid the degeneration into one-to-one matching. We optimize the objective via a penalty algorithm, which is efficient and theoretically guaranteed to converge. Experimental results on various tasks demonstrate that the proposed method achieves good performance by gleaning meaningful many-to-many matchings.
Iterative Tree Analysis for Medical Critics
Jan 18, 2025Large Language Models (LLMs) have been widely adopted across various domains, yet their application in the medical field poses unique challenges, particularly concerning the generation of hallucinations. Hallucinations in open-ended long medical text manifest as misleading critical claims, which are difficult to verify due to two reasons. First, critical claims are often deeply entangled within the text and cannot be extracted based solely on surface-level presentation. Second, verifying these claims is challenging because surface-level token-based retrieval often lacks precise or specific evidence, leaving the claims unverifiable without deeper mechanism-based analysis. In this paper, we introduce a novel method termed Iterative Tree Analysis (ITA) for medical critics. ITA is designed to extract implicit claims from long medical texts and verify each claim through an iterative and adaptive tree-like reasoning process. This process involves a combination of top-down task decomposition and bottom-up evidence consolidation, enabling precise verification of complex medical claims through detailed mechanism-level reasoning. Our extensive experiments demonstrate that ITA significantly outperforms previous methods in detecting factual inaccuracies in complex medical text verification tasks by 10%. Additionally, we will release a comprehensive test set to the public, aiming to foster further advancements in research within this domain.
MCA: Moment Channel Attention Networks
Mar 04, 2024Channel attention mechanisms endeavor to recalibrate channel weights to enhance representation abilities of networks. However, mainstream methods often rely solely on global average pooling as the feature squeezer, which significantly limits the overall potential of models. In this paper, we investigate the statistical moments of feature maps within a neural network. Our findings highlight the critical role of high-order moments in enhancing model capacity. Consequently, we introduce a flexible and comprehensive mechanism termed Extensive Moment Aggregation (EMA) to capture the global spatial context. Building upon this mechanism, we propose the Moment Channel Attention (MCA) framework, which efficiently incorporates multiple levels of moment-based information while minimizing additional computation costs through our Cross Moment Convolution (CMC) module. The CMC module via channel-wise convolution layer to capture multiple order moment information as well as cross channel features. The MCA block is designed to be lightweight and easily integrated into a variety of neural network architectures. Experimental results on classical image classification, object detection, and instance segmentation tasks demonstrate that our proposed method achieves state-of-the-art results, outperforming existing channel attention methods.
Energy-based Automated Model Evaluation
Jan 25, 2024



The conventional evaluation protocols on machine learning models rely heavily on a labeled, i.i.d-assumed testing dataset, which is not often present in real world applications. The Automated Model Evaluation (AutoEval) shows an alternative to this traditional workflow, by forming a proximal prediction pipeline of the testing performance without the presence of ground-truth labels. Despite its recent successes, the AutoEval frameworks still suffer from an overconfidence issue, substantial storage and computational cost. In that regard, we propose a novel measure -- Meta-Distribution Energy (MDE) -- that allows the AutoEval framework to be both more efficient and effective. The core of the MDE is to establish a meta-distribution statistic, on the information (energy) associated with individual samples, then offer a smoother representation enabled by energy-based learning. We further provide our theoretical insights by connecting the MDE with the classification loss. We provide extensive experiments across modalities, datasets and different architectural backbones to validate MDE's validity, together with its superiority compared with prior approaches. We also prove MDE's versatility by showing its seamless integration with large-scale models, and easy adaption to learning scenarios with noisy- or imbalanced- labels. Code and data are available: https://github.com/pengr/Energy_AutoEval
Towards Domain-Specific Features Disentanglement for Domain Generalization
Oct 04, 2023



Distributional shift between domains poses great challenges to modern machine learning algorithms. The domain generalization (DG) signifies a popular line targeting this issue, where these methods intend to uncover universal patterns across disparate distributions. Noted, the crucial challenge behind DG is the existence of irrelevant domain features, and most prior works overlook this information. Motivated by this, we propose a novel contrastive-based disentanglement method CDDG, to effectively utilize the disentangled features to exploit the over-looked domain-specific features, and thus facilitating the extraction of the desired cross-domain category features for DG tasks. Specifically, CDDG learns to decouple inherent mutually exclusive features by leveraging them in the latent space, thus making the learning discriminative. Extensive experiments conducted on various benchmark datasets demonstrate the superiority of our method compared to other state-of-the-art approaches. Furthermore, visualization evaluations confirm the potential of our method in achieving effective feature disentanglement.