 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany-to-Many Matching via Sparsity Controlled Optimal Transport
Mar 31, 2025



Many-to-many matching seeks to match multiple points in one set and multiple points in another set, which is a basis for a wide range of data mining problems. It can be naturally recast in the framework of Optimal Transport (OT). However, existing OT methods either lack the ability to accomplish many-to-many matching or necessitate careful tuning of a regularization parameter to achieve satisfactory results. This paper proposes a novel many-to-many matching method to explicitly encode many-to-many constraints while preventing the degeneration into one-to-one matching. The proposed method consists of the following two components. The first component is the matching budget constraints on each row and column of a transport plan, which specify how many points can be matched to a point at most. The second component is the deformed $q$-entropy regularization, which encourages a point to meet the matching budget maximally. While the deformed $q$-entropy was initially proposed to sparsify a transport plan, we employ it to avoid the degeneration into one-to-one matching. We optimize the objective via a penalty algorithm, which is efficient and theoretically guaranteed to converge. Experimental results on various tasks demonstrate that the proposed method achieves good performance by gleaning meaningful many-to-many matchings.
MCA: Moment Channel Attention Networks
Mar 04, 2024Channel attention mechanisms endeavor to recalibrate channel weights to enhance representation abilities of networks. However, mainstream methods often rely solely on global average pooling as the feature squeezer, which significantly limits the overall potential of models. In this paper, we investigate the statistical moments of feature maps within a neural network. Our findings highlight the critical role of high-order moments in enhancing model capacity. Consequently, we introduce a flexible and comprehensive mechanism termed Extensive Moment Aggregation (EMA) to capture the global spatial context. Building upon this mechanism, we propose the Moment Channel Attention (MCA) framework, which efficiently incorporates multiple levels of moment-based information while minimizing additional computation costs through our Cross Moment Convolution (CMC) module. The CMC module via channel-wise convolution layer to capture multiple order moment information as well as cross channel features. The MCA block is designed to be lightweight and easily integrated into a variety of neural network architectures. Experimental results on classical image classification, object detection, and instance segmentation tasks demonstrate that our proposed method achieves state-of-the-art results, outperforming existing channel attention methods.
DeepBranchTracer: A Generally-Applicable Approach to Curvilinear Structure Reconstruction Using Multi-Feature Learning
Feb 02, 2024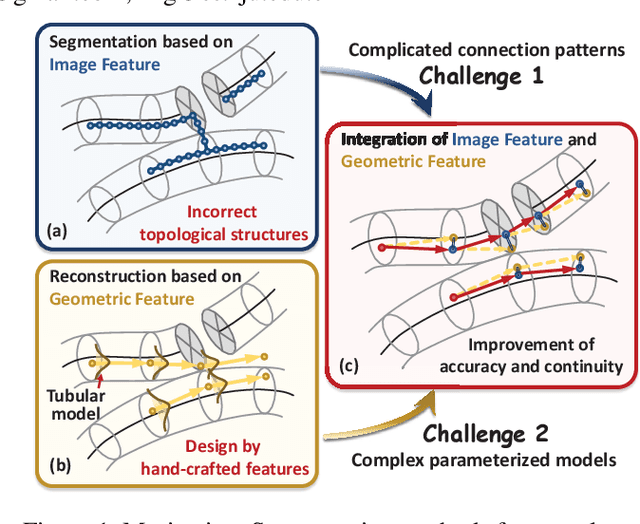
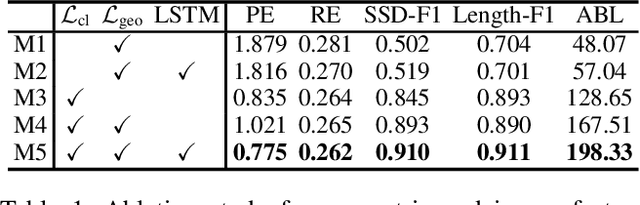
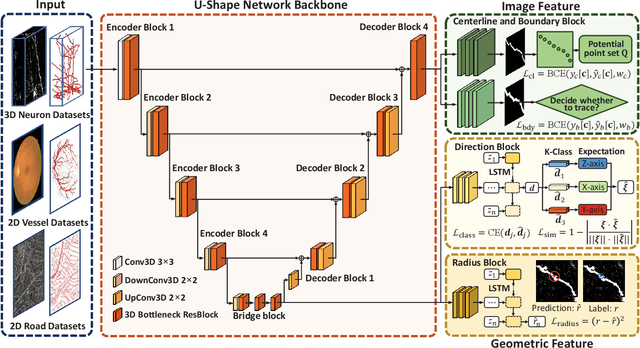
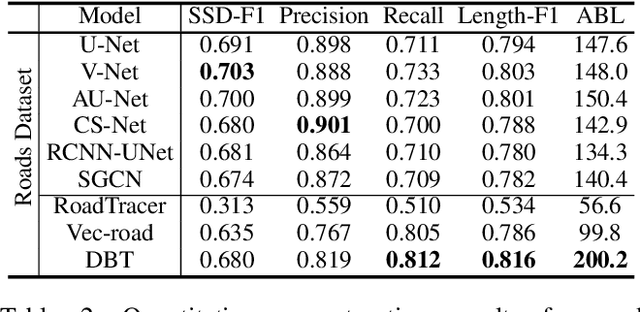
Curvilinear structures, which include line-like continuous objects, are fundamental geometrical elements in image-based applications. Reconstructing these structures from images constitutes a pivotal research area in computer vision. However, the complex topology and ambiguous image evidence render this process a challenging task. In this paper, we introduce DeepBranchTracer, a novel method that learns both external image features and internal geometric characteristics to reconstruct curvilinear structures. Firstly, we formulate the curvilinear structures extraction as a geometric attribute estimation problem. Then, a curvilinear structure feature learning network is designed to extract essential branch attributes, including the image features of centerline and boundary, and the geometric features of direction and radius. Finally, utilizing a multi-feature fusion tracing strategy, our model iteratively traces the entire branch by integrating the extracted image and geometric features. We extensively evaluated our model on both 2D and 3D datasets, demonstrating its superior performance over existing segmentation and reconstruction methods in terms of accuracy and continuity.
Latent Processes Identification From Multi-View Time Series
May 14, 2023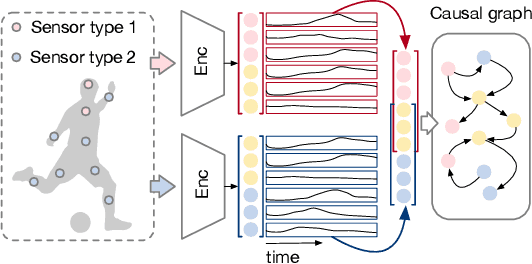
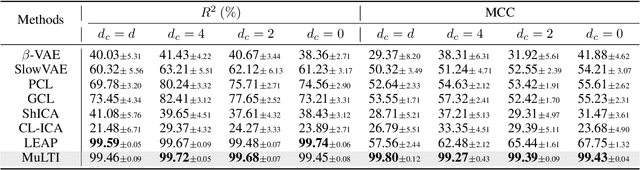
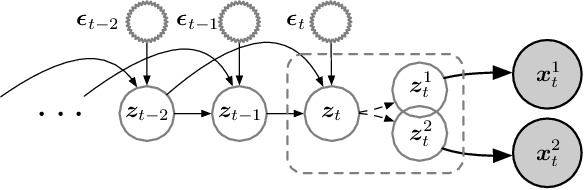
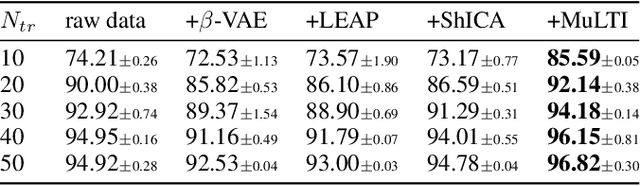
Understanding the dynamics of time series data typically requires identifying the unique latent factors for data generation, \textit{a.k.a.}, latent processes identification. Driven by the independent assumption, existing works have made great progress in handling single-view data. However, it is a non-trivial problem that extends them to multi-view time series data because of two main challenges: (i) the complex data structure, such as temporal dependency, can result in violation of the independent assumption; (ii) the factors from different views are generally overlapped and are hard to be aggregated to a complete set. In this work, we propose a novel framework MuLTI that employs the contrastive learning technique to invert the data generative process for enhanced identifiability. Additionally, MuLTI integrates a permutation mechanism that merges corresponding overlapped variables by the establishment of an optimal transport formula. Extensive experimental results on synthetic and real-world datasets demonstrate the superiority of our method in recovering identifiable latent variables on multi-view time series.
Discriminative Radial Domain Adaptation
Jan 01, 2023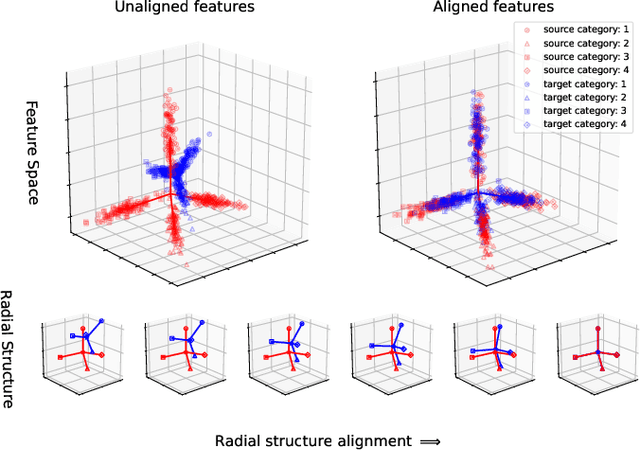
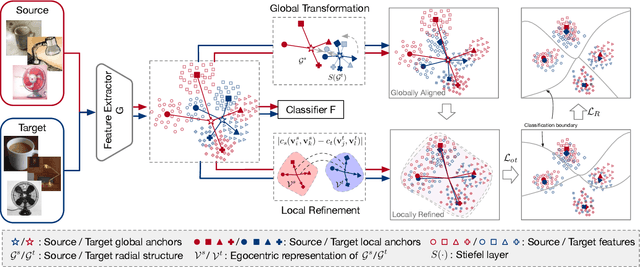
Domain adaptation methods reduce domain shift typically by learning domain-invariant features. Most existing methods are built on distribution matching, e.g., adversarial domain adaptation, which tends to corrupt feature discriminability. In this paper, we propose Discriminative Radial Domain Adaptation (DRDR) which bridges source and target domains via a shared radial structure. It's motivated by the observation that as the model is trained to be progressively discriminative, features of different categories expand outwards in different directions, forming a radial structure. We show that transferring such an inherently discriminative structure would enable to enhance feature transferability and discriminability simultaneously. Specifically, we represent each domain with a global anchor and each category a local anchor to form a radial structure and reduce domain shift via structure matching. It consists of two parts, namely isometric transformation to align the structure globally and local refinement to match each category. To enhance the discriminability of the structure, we further encourage samples to cluster close to the corresponding local anchors based on optimal-transport assignment. Extensively experimenting on multiple benchmarks, our method is shown to consistently outperforms state-of-the-art approaches on varied tasks, including the typical unsupervised domain adaptation, multi-source domain adaptation, domain-agnostic learning, and domain generalization.
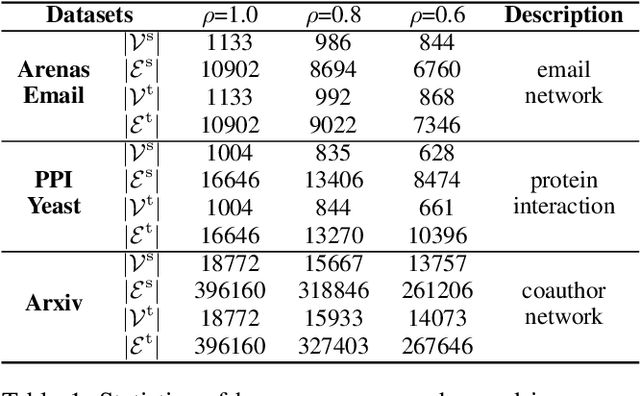
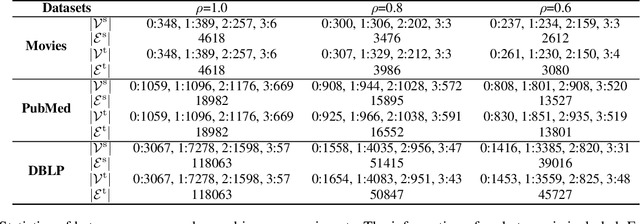
SIGMA: A Structural Inconsistency Reducing Graph Matching Algorithm
Feb 06, 2022


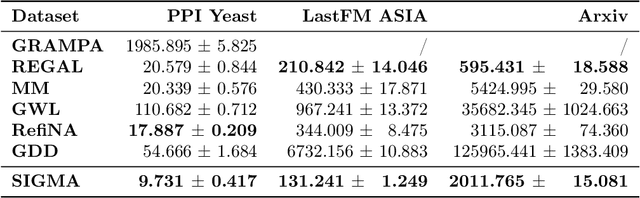
Graph matching finds the correspondence of nodes across two correlated graphs and lies at the core of many applications. When graph side information is not available, the node correspondence is estimated on the sole basis of network topologies. In this paper, we propose a novel criterion to measure the graph matching accuracy, structural inconsistency (SI), which is defined based on the network topological structure. Specifically, SI incorporates the heat diffusion wavelet to accommodate the multi-hop structure of the graphs. Based on SI, we propose a Structural Inconsistency reducing Graph Matching Algorithm (SIGMA), which improves the alignment scores of node pairs that have low SI values in each iteration. Under suitable assumptions, SIGMA can reduce SI values of true counterparts. Furthermore, we demonstrate that SIGMA can be derived by using a mirror descent method to solve the Gromov-Wasserstein distance with a novel K-hop-structure-based matching costs. Extensive experiments show that our method outperforms state-of-the-art methods.
Approximating Optimal Transport via Low-rank and Sparse Factorization
Nov 12, 2021Optimal transport (OT) naturally arises in a wide range of machine learning applications but may often become the computational bottleneck. Recently, one line of works propose to solve OT approximately by searching the \emph{transport plan} in a low-rank subspace. However, the optimal transport plan is often not low-rank, which tends to yield large approximation errors. For example, when Monge's \emph{transport map} exists, the transport plan is full rank. This paper concerns the computation of the OT distance with adequate accuracy and efficiency. A novel approximation for OT is proposed, in which the transport plan can be decomposed into the sum of a low-rank matrix and a sparse one. We theoretically analyze the approximation error. An augmented Lagrangian method is then designed to efficiently calculate the transport plan.
Partial Gromov-Wasserstein Learning for Partial Graph Matching
Dec 09, 2020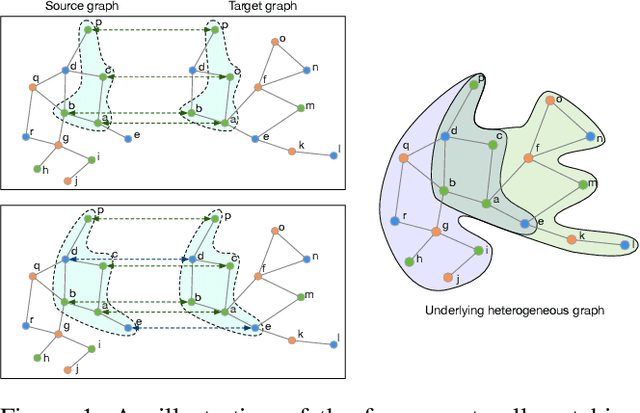
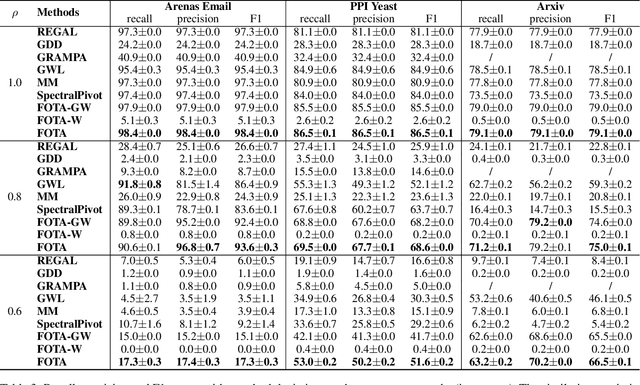
Graph matching finds the correspondence of nodes across two graphs and is a basic task in graph-based machine learning. Numerous existing methods match every node in one graph to one node in the other graph whereas two graphs usually overlap partially in many \realworld{} applications. In this paper, a partial Gromov-Wasserstein learning framework is proposed for partially matching two graphs, which fuses the partial Gromov-Wasserstein distance and the partial Wasserstein distance as the objective and updates the partial transport map and the node embedding in an alternating fashion. The proposed framework transports a fraction of the probability mass and matches node pairs with high relative similarities across the two graphs. Incorporating an embedding learning method, heterogeneous graphs can also be matched. Numerical experiments on both synthetic and \realworld{} graphs demonstrate that our framework can improve the F1 score by at least $20\%$ and often much more.
Interventional Domain Adaptation
Nov 07, 2020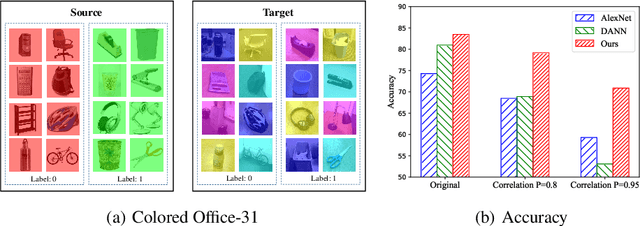
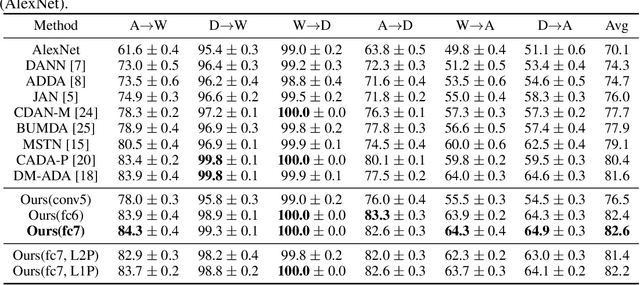
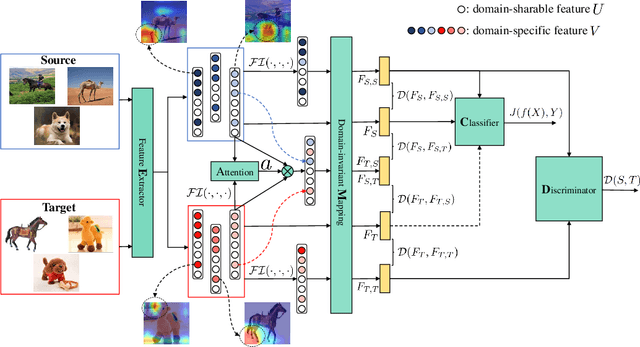
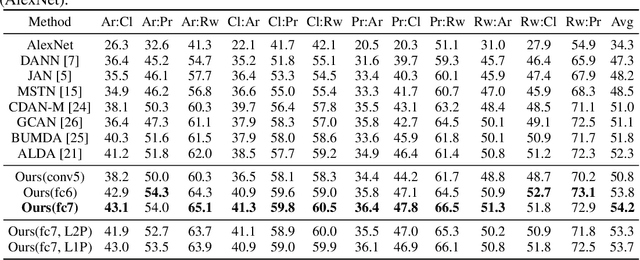
Domain adaptation (DA) aims to transfer discriminative features learned from source domain to target domain. Most of DA methods focus on enhancing feature transferability through domain-invariance learning. However, source-learned discriminability itself might be tailored to be biased and unsafely transferable by spurious correlations, \emph{i.e.}, part of source-specific features are correlated with category labels. We find that standard domain-invariance learning suffers from such correlations and incorrectly transfers the source-specifics. To address this issue, we intervene in the learning of feature discriminability using unlabeled target data to guide it to get rid of the domain-specific part and be safely transferable. Concretely, we generate counterfactual features that distinguish the domain-specifics from domain-sharable part through a novel feature intervention strategy. To prevent the residence of domain-specifics, the feature discriminability is trained to be invariant to the mutations in the domain-specifics of counterfactual features. Experimenting on typical \emph{one-to-one} unsupervised domain adaptation and challenging domain-agnostic adaptation tasks, the consistent performance improvements of our method over state-of-the-art approaches validate that the learned discriminative features are more safely transferable and generalize well to novel domains.
A Decentralized Proximal Point-type Method for Saddle Point Problems
Oct 31, 2019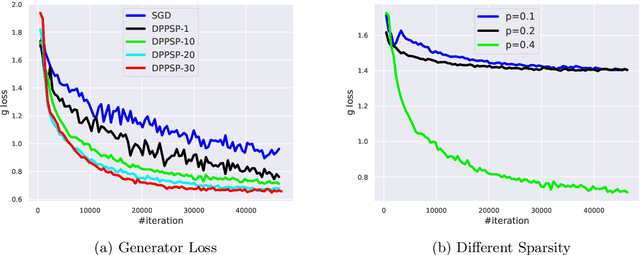

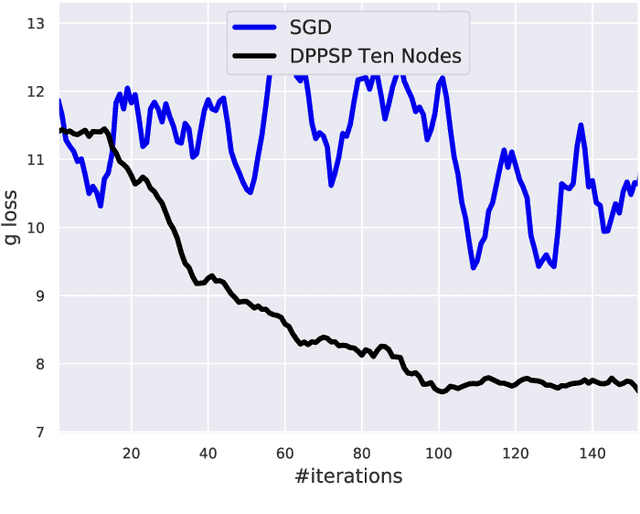
In this paper, we focus on solving a class of constrained non-convex non-concave saddle point problems in a decentralized manner by a group of nodes in a network. Specifically, we assume that each node has access to a summand of a global objective function and nodes are allowed to exchange information only with their neighboring nodes. We propose a decentralized variant of the proximal point method for solving this problem. We show that when the objective function is $\rho$-weakly convex-weakly concave the iterates converge to approximate stationarity with a rate of $\mathcal{O}(1/\sqrt{T})$ where the approximation error depends linearly on $\sqrt{\rho}$. We further show that when the objective function satisfies the Minty VI condition (which generalizes the convex-concave case) we obtain convergence to stationarity with a rate of $\mathcal{O}(1/\sqrt{T})$. To the best of our knowledge, our proposed method is the first decentralized algorithm with theoretical guarantees for solving a non-convex non-concave decentralized saddle point problem. Our numerical results for training a general adversarial network (GAN) in a decentralized manner match our theoretical guarantees.