 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterventional Domain Adaptation
Nov 07, 2020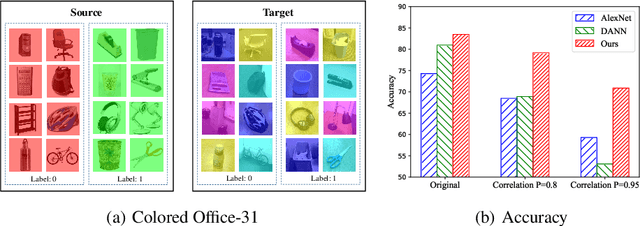
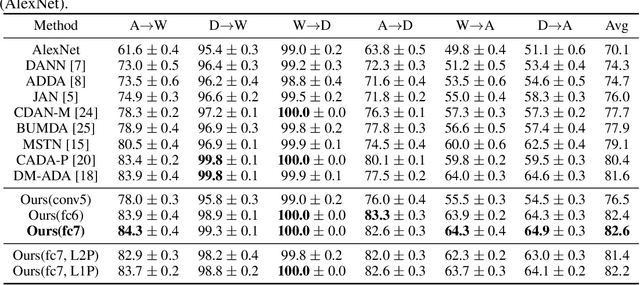
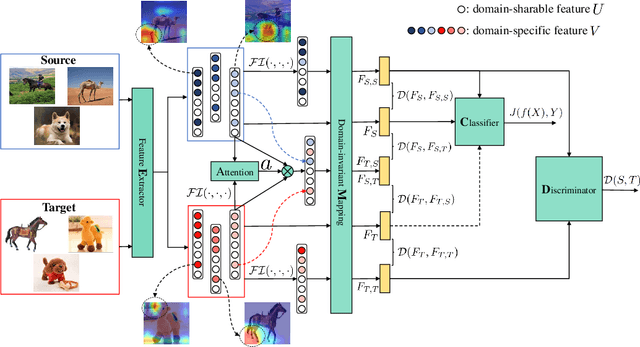
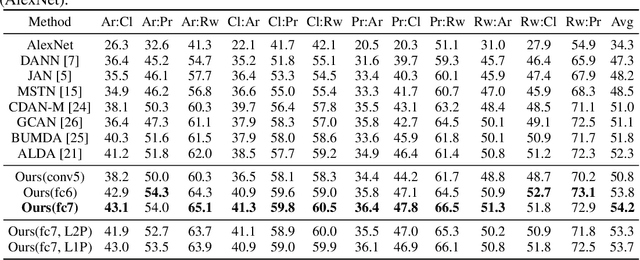
Domain adaptation (DA) aims to transfer discriminative features learned from source domain to target domain. Most of DA methods focus on enhancing feature transferability through domain-invariance learning. However, source-learned discriminability itself might be tailored to be biased and unsafely transferable by spurious correlations, \emph{i.e.}, part of source-specific features are correlated with category labels. We find that standard domain-invariance learning suffers from such correlations and incorrectly transfers the source-specifics. To address this issue, we intervene in the learning of feature discriminability using unlabeled target data to guide it to get rid of the domain-specific part and be safely transferable. Concretely, we generate counterfactual features that distinguish the domain-specifics from domain-sharable part through a novel feature intervention strategy. To prevent the residence of domain-specifics, the feature discriminability is trained to be invariant to the mutations in the domain-specifics of counterfactual features. Experimenting on typical \emph{one-to-one} unsupervised domain adaptation and challenging domain-agnostic adaptation tasks, the consistent performance improvements of our method over state-of-the-art approaches validate that the learned discriminative features are more safely transferable and generalize well to novel domains.
Bayesian Uncertainty Matching for Unsupervised Domain Adaptation
Jun 24, 2019



Domain adaptation is an important technique to alleviate performance degradation caused by domain shift, e.g., when training and test data come from different domains. Most existing deep adaptation methods focus on reducing domain shift by matching marginal feature distributions through deep transformations on the input features, due to the unavailability of target domain labels. We show that domain shift may still exist via label distribution shift at the classifier, thus deteriorating model performances. To alleviate this issue, we propose an approximate joint distribution matching scheme by exploiting prediction uncertainty. Specifically, we use a Bayesian neural network to quantify prediction uncertainty of a classifier. By imposing distribution matching on both features and labels (via uncertainty), label distribution mismatching in source and target data is effectively alleviated, encouraging the classifier to produce consistent predictions across domains. We also propose a few techniques to improve our method by adaptively reweighting domain adaptation loss to achieve nontrivial distribution matching and stable training. Comparisons with state of the art unsupervised domain adaptation methods on three popular benchmark datasets demonstrate the superiority of our approach, especially on the effectiveness of alleviating negative transfer.
Exploiting Local Feature Patterns for Unsupervised Domain Adaptation
Nov 18, 2018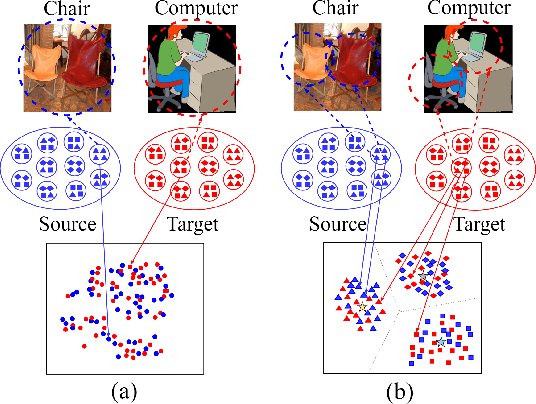
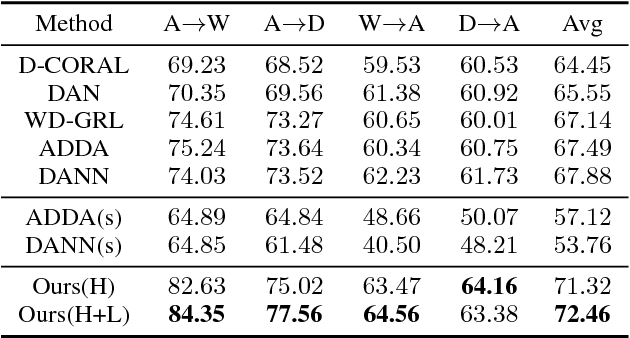


Unsupervised domain adaptation methods aim to alleviate performance degradation caused by domain-shift by learning domain-invariant representations. Existing deep domain adaptation methods focus on holistic feature alignment by matching source and target holistic feature distributions, without considering local features and their multi-mode statistics. We show that the learned local feature patterns are more generic and transferable and a further local feature distribution matching enables fine-grained feature alignment. In this paper, we present a method for learning domain-invariant local feature patterns and jointly aligning holistic and local feature statistics. Comparisons to the state-of-the-art unsupervised domain adaptation methods on two popular benchmark datasets demonstrate the superiority of our approach and its effectiveness on alleviating negative transfer.