 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Pre-Pre-Training Improves Language Model Robustness to Noisy Pre-Training Data
May 11, 2026Large language models (LLMs) rely on web-scale corpora for pre-training. The noise inherent in these datasets tends to obscure meaningful patterns and ultimately degrade model performance. Data curation mitigates but cannot eliminate such noise, so pre-training corpora remain noisy in practice. We therefore study whether a lightweight pre-pre-training (PPT) stage based on synthetic data with learnable temporal structure helps resist noisy data during the pre-training (PT) stage. Across various corruption settings, our method consistently improves robustness to noise during PT, with larger relative gains at higher noise levels. For a 1B-parameter model, a synthetic PPT stage with only 65M tokens achieves the same final loss as the baseline while using up to 49\% fewer natural-text PT tokens across different noise levels. Mechanistic analyses suggest PPT does not immediately suppress attention to noisy tokens. Rather, PPT-initialized models gradually downweight attention between corrupted tokens during noisy PT. This indicates that synthetic PPT inhibits noise self-modeling and shapes the subsequent optimization trajectory. Code is available at https://github.com/guox18/formal-language-prepretraining.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
Explicit Multi-head Attention for Inter-head Interaction in Large Language Models
Jan 27, 2026In large language models built upon the Transformer architecture, recent studies have shown that inter-head interaction can enhance attention performance. Motivated by this, we propose Multi-head Explicit Attention (MEA), a simple yet effective attention variant that explicitly models cross-head interaction. MEA consists of two key components: a Head-level Linear Composition (HLC) module that separately applies learnable linear combinations to the key and value vectors across heads, thereby enabling rich inter-head communication; and a head-level Group Normalization layer that aligns the statistical properties of the recombined heads. MEA shows strong robustness in pretraining, which allows the use of larger learning rates that lead to faster convergence, ultimately resulting in lower validation loss and improved performance across a range of tasks. Furthermore, we explore the parameter efficiency of MEA by reducing the number of attention heads and leveraging HLC to reconstruct them using low-rank "virtual heads". This enables a practical key-value cache compression strategy that reduces KV-cache memory usage by 50% with negligible performance loss on knowledge-intensive and scientific reasoning tasks, and only a 3.59% accuracy drop for Olympiad-level mathematical benchmarks.
How to Set the Batch Size for Large-Scale Pre-training?
Jan 08, 2026The concept of Critical Batch Size, as pioneered by OpenAI, has long served as a foundational principle for large-scale pre-training. However, with the paradigm shift towards the Warmup-Stable-Decay (WSD) learning rate scheduler, we observe that the original theoretical framework and its underlying mechanisms fail to align with new pre-training dynamics. To bridge this gap between theory and practice, this paper derives a revised E(S) relationship tailored for WSD scheduler, characterizing the trade-off between training data consumption E and steps S during pre-training. Our theoretical analysis reveals two fundamental properties of WSD-based pre-training: 1) B_min, the minimum batch size threshold required to achieve a target loss, and 2) B_opt, the optimal batch size that maximizes data efficiency by minimizing total tokens. Building upon these properties, we propose a dynamic Batch Size Scheduler. Extensive experiments demonstrate that our revised formula precisely captures the dynamics of large-scale pre-training, and the resulting scheduling strategy significantly enhances both training efficiency and final model quality.
AutoLogi: Automated Generation of Logic Puzzles for Evaluating Reasoning Abilities of Large Language Models
Feb 24, 2025



While logical reasoning evaluation of Large Language Models (LLMs) has attracted significant attention, existing benchmarks predominantly rely on multiple-choice formats that are vulnerable to random guessing, leading to overestimated performance and substantial performance fluctuations. To obtain more accurate assessments of models' reasoning capabilities, we propose an automated method for synthesizing open-ended logic puzzles, and use it to develop a bilingual benchmark, AutoLogi. Our approach features program-based verification and controllable difficulty levels, enabling more reliable evaluation that better distinguishes models' reasoning abilities. Extensive evaluation of eight modern LLMs shows that AutoLogi can better reflect true model capabilities, with performance scores spanning from 35% to 73% compared to the narrower range of 21% to 37% on the source multiple-choice dataset. Beyond benchmark creation, this synthesis method can generate high-quality training data by incorporating program verifiers into the rejection sampling process, enabling systematic enhancement of LLMs' reasoning capabilities across diverse datasets.
Inference-Time Decontamination: Reusing Leaked Benchmarks for Large Language Model Evaluation
Jun 20, 2024
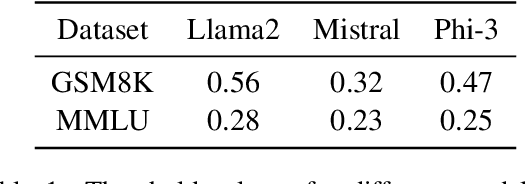


The training process of large language models (LLMs) often involves varying degrees of test data contamination. Although current LLMs are achieving increasingly better performance on various benchmarks, their performance in practical applications does not always match their benchmark results. Leakage of benchmarks can prevent the accurate assessment of LLMs' true performance. However, constructing new benchmarks is costly, labor-intensive and still carries the risk of leakage. Therefore, in this paper, we ask the question, Can we reuse these leaked benchmarks for LLM evaluation? We propose Inference-Time Decontamination (ITD) to address this issue by detecting and rewriting leaked samples without altering their difficulties. ITD can mitigate performance inflation caused by memorizing leaked benchmarks. Our proof-of-concept experiments demonstrate that ITD reduces inflated accuracy by 22.9% on GSM8K and 19.0% on MMLU. On MMLU, using Inference-time Decontamination can lead to a decrease in the results of Phi3 and Mistral by 6.7% and 3.6% respectively. We hope that ITD can provide more truthful evaluation results for large language models.
WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset
Mar 12, 2024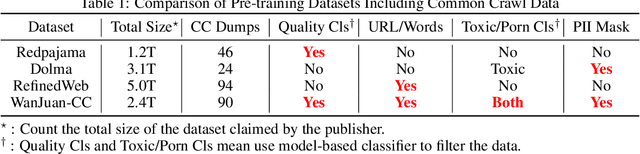
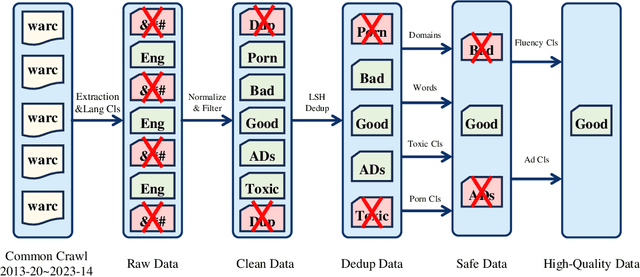
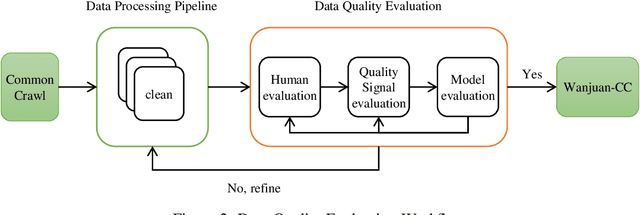

This paper presents WanJuan-CC, a safe and high-quality open-sourced English webtext dataset derived from Common Crawl data. The study addresses the challenges of constructing large-scale pre-training datasets for language models, which require vast amounts of high-quality data. A comprehensive process was designed to handle Common Crawl data, including extraction, heuristic rule filtering, fuzzy deduplication, content safety filtering, and data quality filtering. From approximately 68 billion original English documents, we obtained 2.22T Tokens of safe data and selected 1.0T Tokens of high-quality data as part of WanJuan-CC. We have open-sourced 100B Tokens from this dataset. The paper also provides statistical information related to data quality, enabling users to select appropriate data according to their needs. To evaluate the quality and utility of the dataset, we trained 1B-parameter and 3B-parameter models using WanJuan-CC and another dataset, RefinedWeb. Results show that WanJuan-CC performs better on validation datasets and downstream tasks.
Data-freeWeight Compress and Denoise for Large Language Models
Feb 26, 2024Large Language Models (LLMs) are reshaping the research landscape in artificial intelligence, particularly as model parameters scale up significantly, unlocking remarkable capabilities across various domains. Nevertheless, the scalability of model parameters faces constraints due to limitations in GPU memory and computational speed. To address these constraints, various weight compression methods have emerged, such as Pruning and Quantization. Given the low-rank nature of weight matrices in language models, the reduction of weights through matrix decomposition undoubtedly holds significant potential and promise. In this paper, drawing upon the intrinsic structure of LLMs, we propose a novel approach termed Data-free Joint Rank-k Approximation for compressing the parameter matrices. Significantly, our method is characterized by without necessitating additional involvement of any corpus, while simultaneously preserving orthogonality in conjunction with pruning and quantization methods. We achieve a model pruning of 80% parameters while retaining 93.43% of the original performance without any calibration data. Additionally, we explore the fundamental properties of the weight matrix of LLMs undergone Rank-k Approximation and conduct comprehensive experiments to elucidate our hypothesis.