 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Scope: Turning Sparse Features into Development Tools for Large Language Models
May 12, 2026Large language models have achieved remarkable capabilities across diverse tasks, yet their internal decision-making processes remain largely opaque, limiting our ability to inspect, control, and systematically improve them. This opacity motivates a growing body of research in mechanistic interpretability, with sparse autoencoders (SAEs) emerging as one of the most promising tools for decomposing model activations into sparse, interpretable feature representations. We introduce Qwen-Scope, an open-source suite of SAEs built on the Qwen model family, comprising 14 groups of SAEs across 7 model variants from the Qwen3 and Qwen3.5 series, covering both dense and mixture-of-expert architectures. Built on top of these SAEs, we show that SAEs can go beyond post-hoc analysis to serve as practical interfaces for model development along four directions: (i) inference-time steering, where SAE feature directions control language, concepts, and preferences without modifying model weights; (ii) evaluation analysis, where activated SAE features provide a representation-level proxy for benchmark redundancy and capability coverage; (iii) data-centric workflows, where SAE features support multilingual toxicity classification and safety-oriented data synthesis; and (iv) post-training optimization, where SAE-derived signals are incorporated into supervised fine-tuning and reinforcement learning objectives to mitigate undesirable behaviors such as code-switching and repetition. Together, these results demonstrate that SAEs can serve not only as post-hoc analysis tools, but also as reusable representation-level interfaces for diagnosing, controlling, evaluating, and improving large language models. By open-sourcing Qwen-Scope, we aim to support mechanistic research and accelerate practical workflows that connect model internals to downstream behavior.
Controllable LLM Reasoning via Sparse Autoencoder-Based Steering
Jan 07, 2026Large Reasoning Models (LRMs) exhibit human-like cognitive reasoning strategies (e.g. backtracking, cross-verification) during reasoning process, which improves their performance on complex tasks. Currently, reasoning strategies are autonomously selected by LRMs themselves. However, such autonomous selection often produces inefficient or even erroneous reasoning paths. To make reasoning more reliable and flexible, it is important to develop methods for controlling reasoning strategies. Existing methods struggle to control fine-grained reasoning strategies due to conceptual entanglement in LRMs' hidden states. To address this, we leverage Sparse Autoencoders (SAEs) to decompose strategy-entangled hidden states into a disentangled feature space. To identify the few strategy-specific features from the vast pool of SAE features, we propose SAE-Steering, an efficient two-stage feature identification pipeline. SAE-Steering first recalls features that amplify the logits of strategy-specific keywords, filtering out over 99\% of features, and then ranks the remaining features by their control effectiveness. Using the identified strategy-specific features as control vectors, SAE-Steering outperforms existing methods by over 15\% in control effectiveness. Furthermore, controlling reasoning strategies can redirect LRMs from erroneous paths to correct ones, achieving a 7\% absolute accuracy improvement.
Unveiling Language-Specific Features in Large Language Models via Sparse Autoencoders
May 08, 2025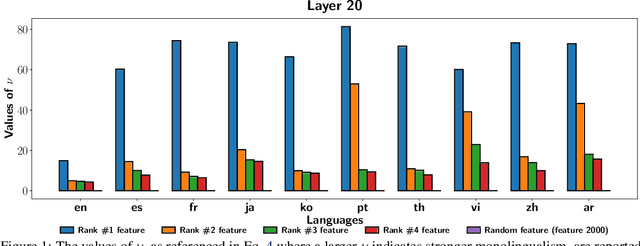
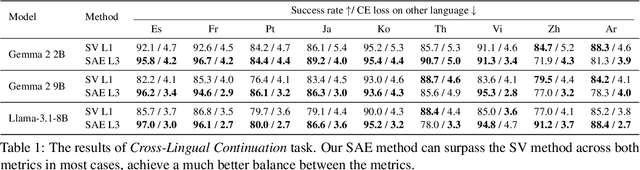
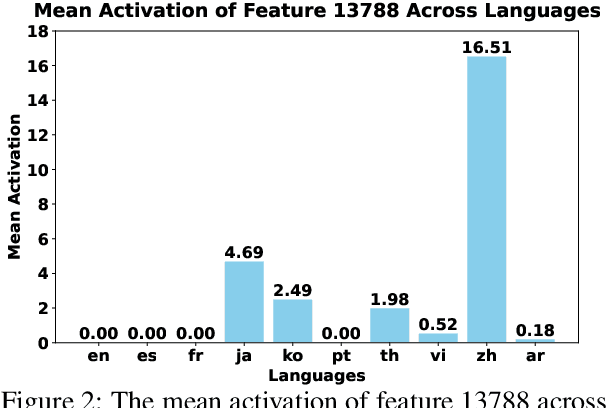
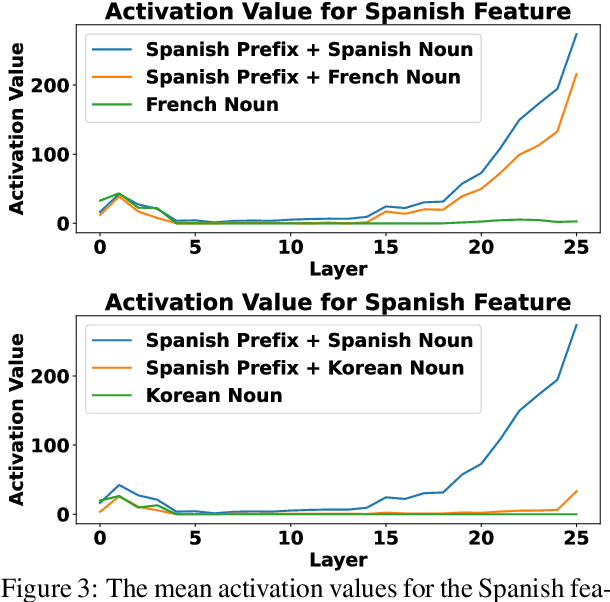
The mechanisms behind multilingual capabilities in Large Language Models (LLMs) have been examined using neuron-based or internal-activation-based methods. However, these methods often face challenges such as superposition and layer-wise activation variance, which limit their reliability. Sparse Autoencoders (SAEs) offer a more nuanced analysis by decomposing the activations of LLMs into sparse linear combination of SAE features. We introduce a novel metric to assess the monolinguality of features obtained from SAEs, discovering that some features are strongly related to specific languages. Additionally, we show that ablating these SAE features only significantly reduces abilities in one language of LLMs, leaving others almost unaffected. Interestingly, we find some languages have multiple synergistic SAE features, and ablating them together yields greater improvement than ablating individually. Moreover, we leverage these SAE-derived language-specific features to enhance steering vectors, achieving control over the language generated by LLMs.
P-MMEval: A Parallel Multilingual Multitask Benchmark for Consistent Evaluation of LLMs
Nov 14, 2024
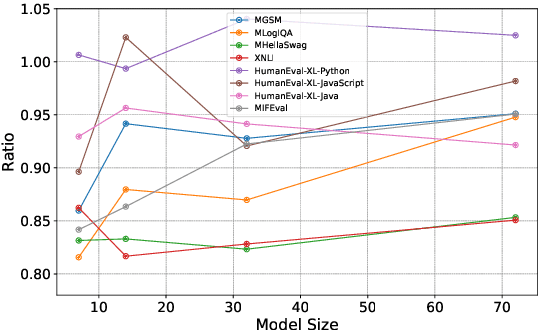


Recent advancements in large language models (LLMs) showcase varied multilingual capabilities across tasks like translation, code generation, and reasoning. Previous assessments often limited their scope to fundamental natural language processing (NLP) or isolated capability-specific tasks. To alleviate this drawback, we aim to present a comprehensive multilingual multitask benchmark. First, we present a pipeline for selecting available and reasonable benchmarks from massive ones, addressing the oversight in previous work regarding the utility of these benchmarks, i.e., their ability to differentiate between models being evaluated. Leveraging this pipeline, we introduce P-MMEval, a large-scale benchmark covering effective fundamental and capability-specialized datasets. Furthermore, P-MMEval delivers consistent language coverage across various datasets and provides parallel samples. Finally, we conduct extensive experiments on representative multilingual model series to compare performances across models, analyze dataset effectiveness, examine prompt impacts on model performances, and explore the relationship between multilingual performances and factors such as tasks, model sizes, and languages. These insights offer valuable guidance for future research. The dataset is available at https://huggingface.co/datasets/Qwen/P-MMEval.
CrAM: Credibility-Aware Attention Modification in LLMs for Combating Misinformation in RAG
Jun 17, 2024Retrieval-Augmented Generation (RAG) can alleviate hallucinations of Large Language Models (LLMs) by referencing external documents. However, the misinformation in external documents may mislead LLMs' generation. To address this issue, we explore the task of "credibility-aware RAG", in which LLMs automatically adjust the influence of retrieved documents based on their credibility scores to counteract misinformation. To this end, we introduce a plug-and-play method named $\textbf{Cr}$edibility-aware $\textbf{A}$ttention $\textbf{M}$odification (CrAM). CrAM identifies influential attention heads in LLMs and adjusts their attention scores based on the credibility of the documents, thereby reducing the impact of low-credibility documents. Experiments on Natual Questions and TriviaQA using Llama2-13B, Llama3-8B, and Qwen-7B show that CrAM improves the RAG performance of LLMs against misinformation pollution by over 20%, even surpassing supervised fine-tuning methods.
Attack Prompt Generation for Red Teaming and Defending Large Language Models
Oct 19, 2023Large language models (LLMs) are susceptible to red teaming attacks, which can induce LLMs to generate harmful content. Previous research constructs attack prompts via manual or automatic methods, which have their own limitations on construction cost and quality. To address these issues, we propose an integrated approach that combines manual and automatic methods to economically generate high-quality attack prompts. Specifically, considering the impressive capabilities of newly emerged LLMs, we propose an attack framework to instruct LLMs to mimic human-generated prompts through in-context learning. Furthermore, we propose a defense framework that fine-tunes victim LLMs through iterative interactions with the attack framework to enhance their safety against red teaming attacks. Extensive experiments on different LLMs validate the effectiveness of our proposed attack and defense frameworks. Additionally, we release a series of attack prompts datasets named SAP with varying sizes, facilitating the safety evaluation and enhancement of more LLMs. Our code and dataset is available on https://github.com/Aatrox103/SAP .