 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGen-Fab: A Variation-Aware Generative Model for Predicting Fabrication Variations in Nanophotonic Devices
Mar 12, 2026Silicon photonic devices often exhibit fabrication-induced variations such as over-etching, underetching, and corner rounding, which can significantly alter device performance. These variations are non-uniform and are influenced by feature size and shape. Accurate digital twins are therefore needed to predict the range of possible fabricated outcomes for a given design. In this paper, we introduce Gen-Fab, a conditional generative adversarial network (cGAN) based on Pix2Pix to predict and model uncertainty in photonic fabrication outcomes. The proposed method takes a design layout (in GDS format) as input and produces diverse high-resolution predictions similar to scanning electron microscope (SEM) images of fabricated devices, capturing the range of process variations at the nanometer scale. To enable one-to-many mapping, we inject a latent noise vector at the model bottleneck. We compare Gen-Fab against three baselines: (1) a deterministic U-Net predictor, (2) an inference-time Monte Carlo Dropout U-Net, and (3) an ensemble of varied U-Nets. Evaluations on an out-of-distribution dataset of fabricated photonic test structures demonstrate that Gen-Fab outperforms all baselines in both accuracy and uncertainty modeling. An additional distribution shift analysis further confirms its strong generalization to unseen fabrication geometries. Gen-Fab achieves the highest intersection-over-union (IoU) score of 89.8%, outperforming the deterministic U-Net (85.3%), the MC-Dropout U-Net (83.4%), and varying U-Nets (85.8%). It also better aligns with the distribution of real fabrication outcomes, achieving lower Kullback-Leibler divergence and Wasserstein distance.
* Accepted and published in Structural and Multidisciplinary Optimization (2026)
SEMU-Net: A Segmentation-based Corrector for Fabrication Process Variations of Nanophotonics with Microscopic Images
Nov 25, 2024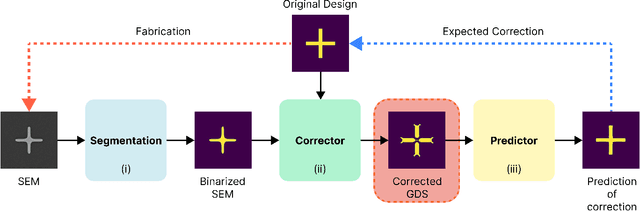
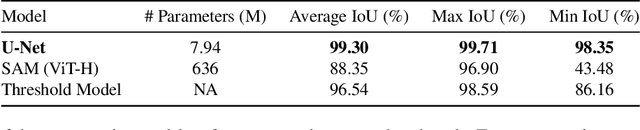
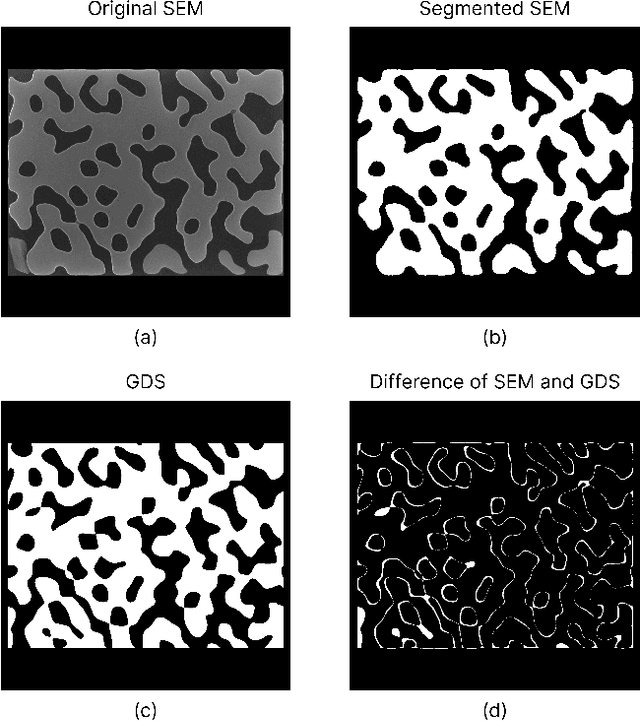
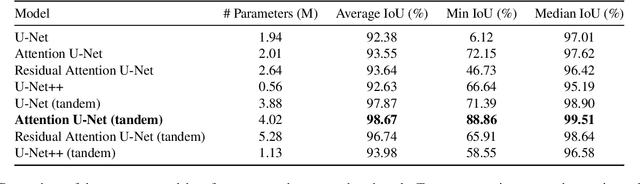
Integrated silicon photonic devices, which manipulate light to transmit and process information on a silicon-on-insulator chip, are highly sensitive to structural variations. Minor deviations during nanofabrication-the precise process of building structures at the nanometer scale-such as over- or under-etching, corner rounding, and unintended defects, can significantly impact performance. To address these challenges, we introduce SEMU-Net, a comprehensive set of methods that automatically segments scanning electron microscope images (SEM) and uses them to train two deep neural network models based on U-Net and its variants. The predictor model anticipates fabrication-induced variations, while the corrector model adjusts the design to address these issues, ensuring that the final fabricated structures closely align with the intended specifications. Experimental results show that the segmentation U-Net reaches an average IoU score of 99.30%, while the corrector attention U-Net in a tandem architecture achieves an average IoU score of 98.67%.
KD-LoRA: A Hybrid Approach to Efficient Fine-Tuning with LoRA and Knowledge Distillation
Oct 28, 2024



Large language models (LLMs) have demonstrated remarkable performance across various downstream tasks. However, the high computational and memory requirements of LLMs are a major bottleneck. To address this, parameter-efficient fine-tuning (PEFT) methods such as low-rank adaptation (LoRA) have been proposed to reduce computational costs while ensuring minimal loss in performance. Additionally, knowledge distillation (KD) has been a popular choice for obtaining compact student models from teacher models. In this work, we present KD-LoRA, a novel fine-tuning method that combines LoRA with KD. Our results demonstrate that KD-LoRA achieves performance comparable to full fine-tuning (FFT) and LoRA while significantly reducing resource requirements. Specifically, KD-LoRA retains 98% of LoRA's performance on the GLUE benchmark, while being 40% more compact. Additionally, KD-LoRA reduces GPU memory usage by 30% compared to LoRA, while decreasing inference time by 30% compared to both FFT and LoRA. We evaluate KD-LoRA across three encoder-only models: BERT, RoBERTa, and DeBERTaV3. Code is available at https://github.com/rambodazimi/KD-LoRA.